




{kind=link}
Many technologies that make it to the mass market hit a tipping point somewhere along their growth curve where marginal costs rapidly drop, which drives more demand, which drives economies of scale, which drives down prices, which drives demand and jumpstarts a virtuous cycle. For automobiles, the tipping point was the moving assembly line, convenient stores like iTunes for MP3 players, microprocessors for computing, and for software it was object-oriented programming. Reusing pre-trained models just might be a tipping point for AI.
Lower Marginal Cost
Carl Benz began producing automobiles in 1886. Fourteen years later, Henry Ford was making 25 cars a day, taking 12 hours per car. By 1925, he reduced that 85% to 1.5 hours. More importantly, the cost to consumers also plummeted 85% to $4,500 per car in today’s dollars. The tipping point was Ford’s moving assembly line. The effects were, and still are, huge: increased efficiency created margins that allowed Ford to pay workers $5 per day and jump-start the American middle class, automobiles enabled the development of suburbs and single family housing, and oil to fuel cars changed global geopolitics. An 85% drop in costs generated big and unexpected effects.
MP3 players appeared in the late 1990s. A few years later, iTunes drastically increased the convenience and decreased the cost of digital music. Today, Spotify has 100 million songs for $10 a month, driving the marginal cost of a song to a hundred thousandth of a penny.
Transistors lowered the cost of electrical circuit switches, which led to microprocessors and a rapid decline in computing costs. Computing costs today are a hundred millionth of what they were in 1980, resulting in desktop, mobile, and cloud computing.
Microprocessors increased the demand for software and the need for a productivity gain like Ford’s assembly line. Object-oriented programming provided it, leading to design patterns, frameworks, and global open source software reuse. Today, there are millions of open source software contributors worldwide and nearly every new project depends on some open source software.
Now comes AI. Deep learning used neural networks to drastically reduce the human effort of engineering predictive model inputs. That led to a new class of models called large language models (LLMs) that train on millions of text documents and can be reused for many tasks. Perhaps reuse of pre-trained models will drive down marginal costs like object-oriented programming and microprocessors did, creating a tipping point for AI and many exciting, unexpected effects. To explain further, we need to introduce some terminology.
What Is a Neural Network Parameter?
This is a non-technical simplification for explanatory purposes. A neural network is a set of nodes connected by directed links. Nodes output a number, links have weights, and the output of a node is a simple function of its weighted inputs. For example:
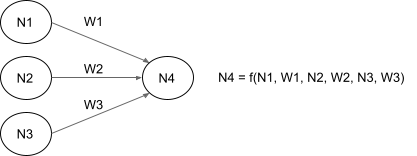
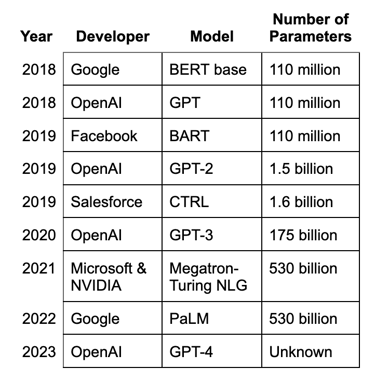
Weighted links are called parameters and the number of parameters is a rough measure of how much a neural network can learn. Here are the sizes of some LLMs:
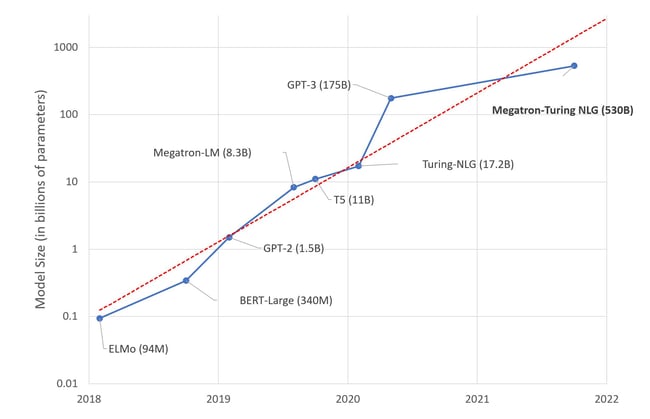
Model size is growing exponentially as illustrated by this chart from Hugging Face, a platform for AI code and model reuse:
LLM training is the process of learning parameter values and uses a lot of computation. It’s been estimated that OpenAI’s GPT-2 cost $40,000 to train, GPT-3 cost $4,600,000 and Google’s PaLM cost $13 million. This may seem cheap since these models are new and exciting. However, even GPT-2’s $40,000 is too expensive to scale like Ford’s $4,500 automobile, desktop computing, and Spotify did. That’s where reuse of pre-trained models comes in.
How Are LLMs Reused?
OpenAI’s ChatGPT took the world by storm in November 2022 and gained 100 million users in two months. It was developed by fine-turning their GPT-3 (the “P” stands for pre-trained) LLM for chatting. That is, GPT-3 (3.5 technically) was trained months earlier and had all its 175 billion parameters set. Additional training was done, and parameters changed, to make ChatGPT. There are other important differences between GPT-3 and ChatGPT — such as ChatGPT using supervised and reinforcement learning to continuously learn — but the wholesale reuse of one by the other reduced ChatGPT’s costs.
Another example of pre-trained model fine-tuning is Stanford’s Alpaca. They used ChatGPT to generate 50,000 instruction-response pairs by bootstrapping from just 175 open source instructions such as “Create a birthday planning checklist” and “Reply to the following email and refuse the invitation politely.” The 50,000 pairs were then used to fine-tune Facebook’s seven billion parameter LLaMA. It cost $500 to use ChatGPT-3 to generate responses and $100 to fine-tuning LLaMA for a total cost of just $600.
Databricks reused Alpaca’s 50,000 instruction-response pairs to replicate the experiment on the 6 billion parameter open source model GPT-J from EleutherAI for just $30. Two weeks later they released a 12 billion parameter, open source model fine-tuned on 15,000 manually-generated instruction-response pairs crowd sourced from their employees. And it’s licensed for commercial use. We went from $40,000 per model to $30 in four years.

Another way to reuse pretrained models is to provide additional training examples during inference and not change the underlying model parameters at all. This is sometimes called prompt engineering. While it increases inference cost, it adds no additional training costs. OpenAI demonstrated this approach with GPT-3 and Hugging Face did it with EleutherAI’s six billion parameter GPT-Neo. Dataiku showed it on images.
Reusing pretrained models makes sense since that’s how people work too. If you need representation in a legal case then you’re better off with someone with a law degree and years of experience than with training your plumber to represent you. A lawyer with experience has background knowledge and has seen similar cases. While they still need to learn the specifics of your case, unlike the plumber, they already know the basics.
Marginal Cost of Lawyers vs. Pre-Trained LLMs
The marginal cost of lawyers and LLMs are very different. It costs about $600,000 to duplicate an experienced lawyer: $200,000 for three years of law school and $400,000 for their first five years of salary. LLM parameters are digital data so the cost of duplicating them is almost nothing.
The 176 billion parameter open source BLOOM model, for example, would take a few hours to duplicate and cost only about $180 a year to store in the cloud. Eight years and $600,000 for a lawyer versus a few hours and $180 for an LLM. Those are pretty compelling economics. BLOOM is one of many free LLMs available today. (These are just the duplication, or training, costs. Inference and total cost of ownership costs will be extra.)
Key Takeaways
There are cases where training your own LLM from scratch is worth the cost. Google, Facebook, and OpenAI certainly have the resources and business cases for it. Bloomberg does too because of their unique, highly curated, financial corpus spanning 40 years that is a big competitive advantage for them. However, most tasks don’t need their own base model.
Rather, we can reuse open source models and get good results for hundreds of dollars. And costs are dropping fast. Some estimate that LLM training costs fall 45% a year. Who knows how much it will be next year when NVIDIA and the cloud providers come out with new hardware, and we adopt more efficient software methods such as mixture of experts, quantization, and distillation that can reduce training and inference costs by 85%. As marginal costs plummet, LLM inference may start being added to every app, like graphical user interfaces a generation ago. This might just be AI’s tipping point.