




Reinforcement learning is a technique largely used for training gaming AI — like making a computer win at Go or finish Super Mario Bros levels super fast. That's great, but to some extent, this use case isn’t very exciting or useful. Yet reinforcement learning is also the potential first step toward bringing intuition to AI in business contexts, filling the gap between abductive reasoning and inductive reasoning.
Oh my! What does that last sentence even mean? Allow me to explain…

A Small Side Walk Though Epistemology
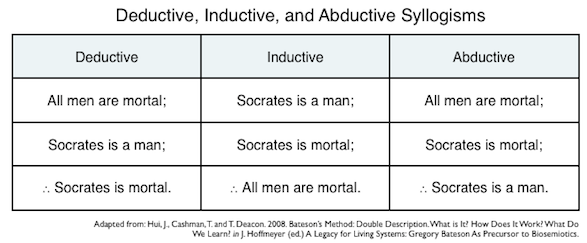
In philosophy, there are various ways to classify reasoning methods. But for the scope of this blog post, let’s focus on a simple taxonomy with three categories: deductive, inductive, and abductive reasoning.
- Deductive reasoning is about reaching a conclusion from the fact directly. In other words, if A, then B.
- Inductive reasoning is about generalizing concepts from facts, then using those concepts to reach a conclusion. For instance, all cats that you have observed purr. Therefore, every cat must purr.
- Abductive reasoning is about filling the gap in a situation with missing information and then using best judgement to bridge the gap.
{kind=link}
So, when applying machine learning to a business problem, are we implicitly using a deductive, inductive, or the abductive reasoning method? The correct answer is: it depends.
Is ML Inductive or Abductive Reasoning?
There are indeed several kinds of machine learning problems. An obvious way to segregate them is by the type of data they use; another obvious way is by domain or business objective.
But machine learning problems can also be more subtly distinguished between problems where you want to decide or forecast within the parameters of historical data and those where you need to apply decision making outside the range of historical parameters.
Let’s take practical examples in three different industries: insurance, e-commerce, and manufacturing
In insurance, a very common problem is to try to classify claims. For example, the claim after an apartment flooding that leaves water damage on all of the walls and the ceiling (all of this because a bird was caught in the water evacuation, which is especially fun if the logo of the company is a bird). The main problem to solve for here is whether a claim should be further investigated by a human analyst. And typically the way this is done is by looking for example of former claims (fraudulent or not) and use them to train a model.
In such an instance, it’s fairly likely that any claim you investigate has things in common with a claim reviewed by the company in the past. After all, there are only so many ways to get water damage in an apartment, right?
So the kind of reasoning used here is actually implicitly inductive reasoning: you mostly generalize as to what a regular and an irregular claim should look like based on many examples.
Another problem in insurance, this time with life insurance, is to try and determine the capital allocation strategy for the insurance company. The point for the insurance company is to be able to guarantee that it has enough capital to cover any damages or any call for capital.
The challenge with these kinds of problems is that a completely rigorous approach requires taking many possible edge cases into account. For instance, there’s a probability that global warming significantly increases the likelihood of flooding. There’s also some probability for a war that would impact things, etc.
In such an instance, the challenge is that your forecast requires you to explore “states” of the system that are unknown from a historical data perspective, and that such edge cases might also be correlated.
When building such models, actuaries and finance specialists have to make some common sense assumptions — like, there’s such average likelihood of a certain event that its probability can be represented as a normal function. Or such and such parameter would interact, and such and such parameter would not.
To build a full strategy, historical data would be used to build statistical or machine learning models, but this data would also be combined with lots of implicit modeling on the behavior of the system at the extreme. And in fact, implicit modeling is required in order to model for anything that would be outside of the range of historical data.
In retail, another typical machine learning problem is to try to predict if a given basket will convert. If you can predict that a basket is less likely to convert, you may want to push the needle a bit by delivering a marketing message or offer a last minute discount, for instance. Such prediction can be achieved with machine learning by looking at the characteristics of similar baskets: size of the basket, recurrence of purchases by the customer, time of the day, time spent shopping, etc.
Another kind of problem is to try and optimize pricing or arrangement — i.e., would you improve revenue (and margin) by reducing the price of Item X by 5 percent? Or by providing a discount for a group sale?
The challenge of pricing optimization is that it typically requires the exploration of spaces (in the set of all possible prices for each product or assortment) that are not part of the historical data. Especially assortment with a discount: you probably haven’t tried all possible arrangements, and rightfully so — some of them likely don’t make sense. For example, providing a discount for a basket containing cat food to package it with an LED TV probably does not make sense. But you never tried it, so you don’t have data for it… so how do you know?
At the end of the day, pricing optimization requires you to make some underlying assumptions, like how a variation in price correlates to a willingness to buy. Such a behavior can be partially observed with data on some products, but never completely.
Reinforcement Learning: Turning Abduction Into Induction
Induction reasoning done with mathematical formulas is useful, but not completely satisfying for at least two reasons:
- You build a perspective of the world that “looks” credible by relying on well-distributed distributions. When going the mathematical route, you implicitly favor symmetry and continuousness over realism.
- It is difficult to optimize for mathematical models.
In a nutshell, reinforcement learning (RL) algorithms, or agents, learn by interacting with their environment (check out 5 Things You Need to Know About Reinforcement Learning to go more in depth).
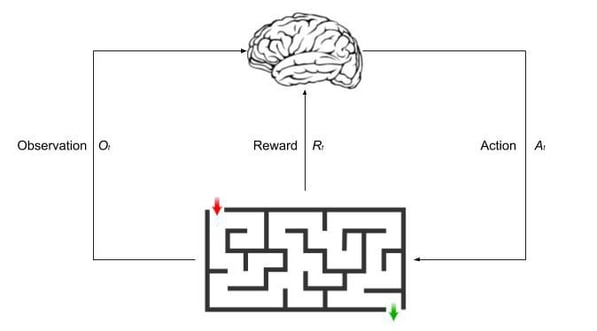 The process of reinforcement learning - image source
The process of reinforcement learning - image source
Today, reinforcement learning is filling the gap between the “dense data-driven” and the “shallow model-driven” world. Instead of building an intuitive mathematical “model” that fills the void, in a RL paradigm, humans try to build a realistic universe by modeling the system’s behavior with a computing perspective. Then RL kicks in, trying to optimize for this and in a sense, “re-creating” a form of intuition — i.e., what is obvious to do in context.
Pricing optimization with reinforcement learning would be implemented as such:
- Some predictive models and statistics would be built to capture user demand and user behavior in context (e.g., transformation). That’s data science work.
- A full-fledged universe with users and customers would be programmed. That’s AI modeler work.
- Then a RL system would try to explore this universe, playing with the prices in this virtual universe and learning how to best behave from this perspective.
What’s to Come for RL
Clearly, reinforcement learning is not a new concept, but it is becoming an increasingly important field of machine learning and AI for all of its very practical applications (outside of gaming, of course). In addition to the applications discussed here, there is also a lot of promise in the area of computer system and network resource management.
McKinsey estimates that AI techniques (including RL) have the potential to create between $3.5T and $5.8T in value annually across nine business functions in 19 industries. But so far, this is really just potential, and very few businesses have been able to harness the power of AI, and more specifically, reinforcement learning. But thanks to the rising popularity of RL and lots of research on the subject, it’s likely that in the coming years, RL will move out of the research sphere and into the enterprise for actual, real-world developments.