




{kind=link}
One of the critical challenges for analytics and AI projects is the leap from design to production. After creating projects, data teams need models and pipelines to run on production data sources and environments to make predictions and drive business decisions. Manual project deployment is resource-intensive and can result in mistakes and rework that lead to delays and frustration.
Luckily, Dataiku already offers several deployment options for batch and real-time predictions via Automation and API nodes. The Deployer in Dataiku 9 adds to the existing framework to create a consistent and easy way to deploy projects with a self-service interface and support for programmatic deployment via APIs to support CI/CD.
New, Self-Service Deployment for the Data Team
In Dataiku, a project contains more than just a predictive model. A Dataiku project has all the data preparation steps, model training, and predictive scoring, along with all the code and other artifacts needed to make it all work. Dataiku nicely wraps up all these steps into a bundle for export and import between design and production nodes. The challenge is that even with bundles, manual steps can result in errors. In addition, when data scientists or data engineers don't have access to production nodes, they must coordinate with IT or the owners of test and production environments to import their project, which again introduces extra steps, work, and potential for error and delays.
The new Deployer in Dataiku 9 provides an easy-to-use, self-service interface for data team members to deploy Dataiku project bundles, from design nodes to automation nodes. A data scientist, for example, can easily bundle a project in a few clicks and then pick the automation node where they would like to deploy the project, as shown in figure 1. Note that IT admins can configure where the data teams can deploy. The most likely scenario is that data scientists deploy their bundle to a test environment. At that point, data engineers or IT operators test the AI project under production conditions before deployment onto a live production environment.
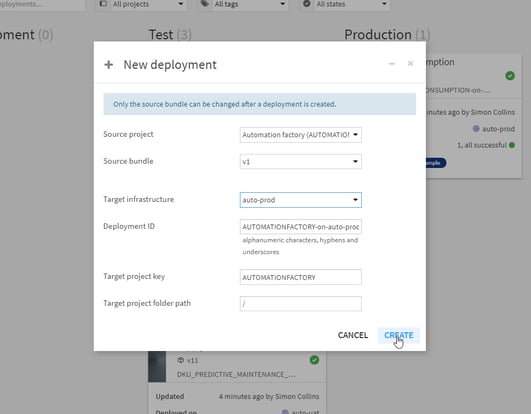 Figure 1: The self-service process walks data scientists through the deployment process
Figure 1: The self-service process walks data scientists through the deployment process
Once deployed, project status is available via the deployment dashboard for dev, test, and production nodes, as shown, including the version of the project deployed to each.
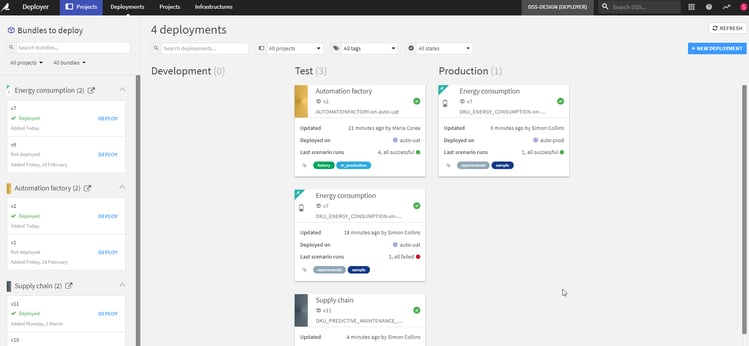 Figure 2: The project deployment dashboard
Figure 2: The project deployment dashboard
CI/CD with Automation Nodes
AI production projects undergo frequent updates as data and models change. Using manual processes to update production processes, even with an excellent interface, is resource-intensive. For this reason, CI/CD tools can help to automate updates to most projects. Learn more about CI/CD in this blog or watch the video at the end of this post. In Dataiku 9, the Deployer also supports automation via APIs to automate ongoing projects using existing tools like Jenkins.
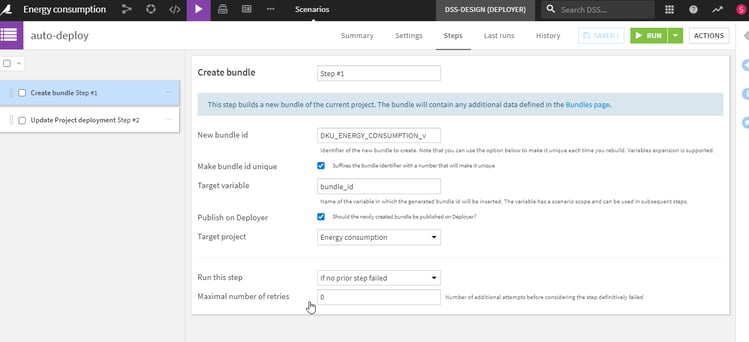
Figure 3: Setup rules for automated deployment
The new Deployer in Dataiku 9 makes it easy to deploy projects between design, testing, and production environments, which helps data teams drive more production projects faster and with fewer errors so that organizations can generate more value from analytics and AI programs. To learn more about CI/CD with Dataiku and Jenkins, check out this video.