




In this article, we focus on the second half of a session from Everyday AI New York with a transcript of the easy-to-grasp use case walkthrough from Dataiku Principal Partner Sales Engineer, Pat Masi-Phelps.
Pat is throwing a real-world scenario at us, showing how Snowflake and Dataiku team up to put Generative AI to work. We're talking about the nitty-gritty stuff — handling sensitive data, like bank call transcripts. Think about anonymizing names, addresses, and all the other sensitive information that banks have to safeguard.
Pat takes us through this use case where responsible data privacy and security are top concerns. In this project, we’re connecting Dataiku’s LLM Mesh to an LLM hosted in Snowflake’s Snowpark Container Services. It's not just a tech show-off; it's a practical example of how these smart technologies can get down to business while keeping things private and safe. So, buckle up and join us for the hands-on, real-world side of Generative AI where it’s not just theory; it's the good stuff you can actually use.
You can watch the full session with more from Matt Glickman, VP of Customer Product Strategy and Financial Services at Snowflake, on how Snowflake and Dataiku work together; or you can do a quick read through of Pat’s use case presentation below. Up to you. Whichever you choose, get excited to dive right into the action!
Pat Masi-Phelps:
I'm excited to show you all how we're integrating Snowflake into the Dataiku LLM Mesh. So first off, we can use Snowpark ML to deploy an open-source LLM like Llama2 or Falcon into Snowpark Container Services, and the benefit of this is that it's within your Snowflake account. It's a private model and then Dataiku can connect to it.
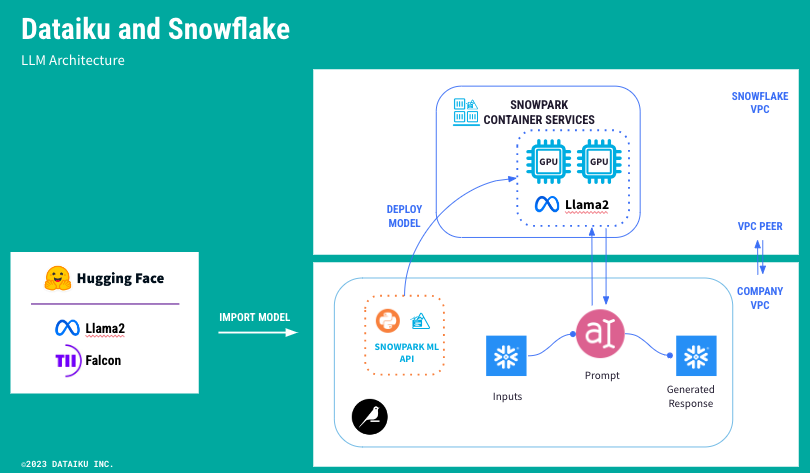
Dataiku can send it data. We can send it prompts, and we can incorporate this model as a part of a larger LLM-based workflow. To emphasize the benefits of using a private LLM, I want to take a use case of consumer bank call transcripts.
The company Gridspace simulated thousands of calls between people and their bank — opening new accounts, transferring money between accounts, figuring out what the hours of the bank are, and we can ask an LLM to summarize what happened in a call. “Was the issue resolved? What's the sentiment of the customer?” We can understand the issues of our customers better in this way. So, it's smart reading comprehension, which is a really good use case for an LLM on unstructured text data.
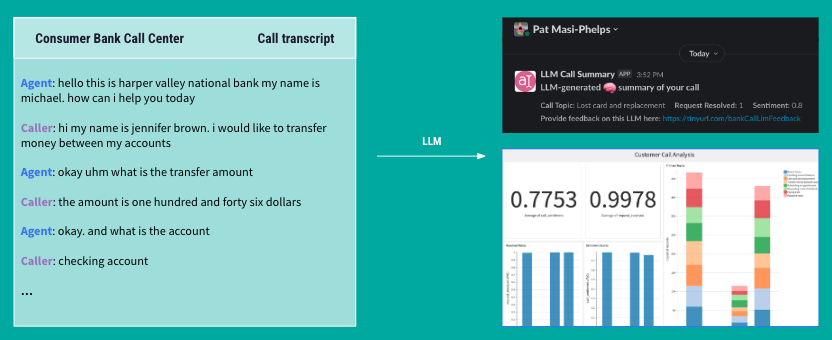
Another thing we can do is automate sending out messages to our agents to say here's a summary of your call that happened earlier today. But, I'm sure you can understand how this data is very sensitive. If I'm calling my bank, I'm likely to be giving them my name, my social security number, my address, my bank account number, right? So how do we deal with this in a responsible way?
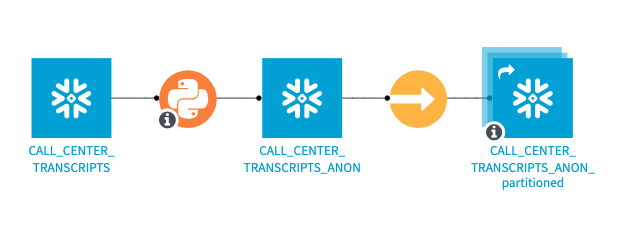
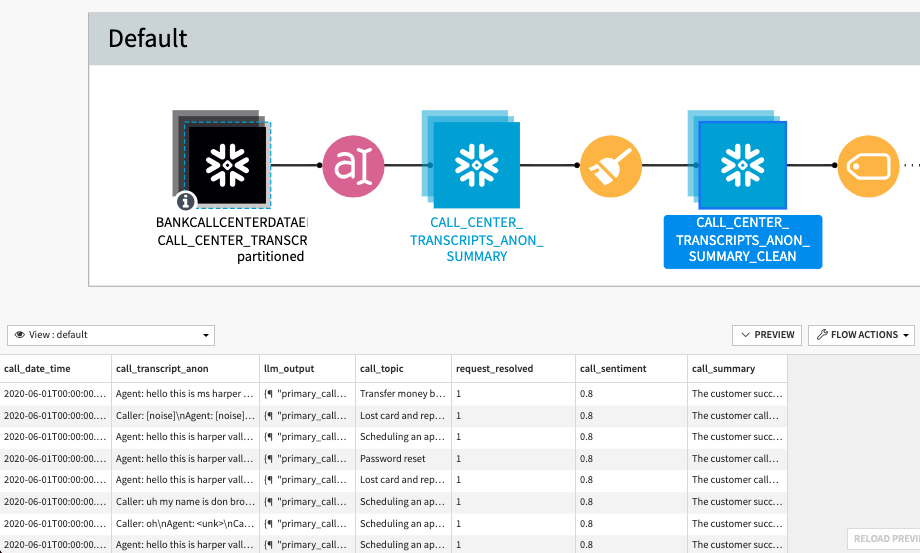
What I'm going to do is connect to my data in Snowflake, and this is my raw unedited transcript data. I'm going to flag it as GPR-sensitive. Then, I'm going to use a Python library called Presidio, which was developed by Microsoft, to anonymize the transcripts. I'm going to take out names, addresses, social security numbers, and lots of other info. I'm going to store the output in another Snowflake database, and we can expose this database to a different group of people in our organization.
Our data scientists can engineer a prompt, we can choose our private model (in this case Mistral 7B) hosted in Snowpark Container Services, and ask the model, “Please give me a summary, the sentiment, and was this issue resolved?” Again, we feel good about this because our model is hosted privately in our Snowflake account. Even though we've stripped the transcripts of all of our sensitive data, we still want to be comfortable with sending it to a model locally.
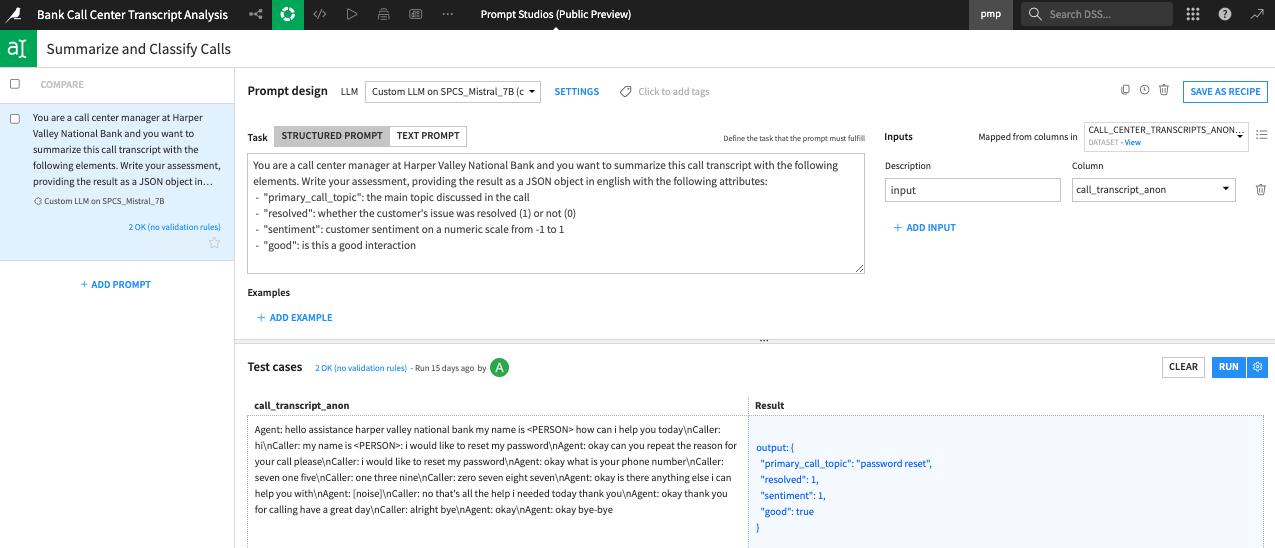
We can deploy this model as a part of our workflow, run it on all of our call transcripts, and we can use a Dataiku scenario to send that Slack message every day to each of our agents.
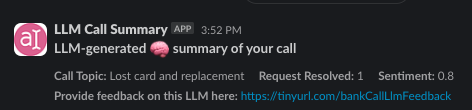
Notice the way that we present this information. We're explicitly calling out that this was generated by an LLM, and we're offering people a feedback form. This way they can go back in and say, “Hey, this LLM output was good. This one was bad.” These are all ways that we can continue to improve LLM performance over time.
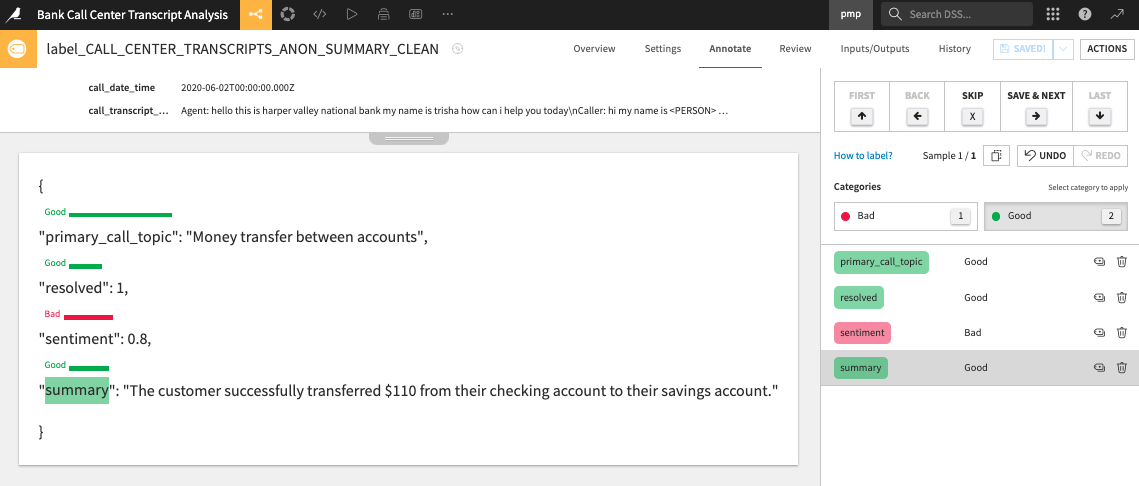
{kind=link}
I think our collaboration — Snowflake and Dataiku — is really interesting for all of you because it's a good option to privately host an LLM. I also want to emphasize the importance of these other LLM Mesh concepts. How do we deal with sensitive data coming into an LLM? How do we measure LLM performance? And how do we present LLM generated outputs? These are all important things to consider.