




{kind=link}
Anomaly detection is all about finding patterns of interest (outliers, exceptions, peculiarities, etc.) that deviate from expected behavior within dataset(s). Given this definition, it’s worth noting that anomaly detection is, therefore, very similar to noise removal and novelty detection. Though patterns detected with anomaly detection are actually of interest, noise detection can be slightly different because the sole purpose of detection is removing those anomalies — or noise — from data.
As with most data science projects, the ultimate end goal or output of anomaly detection is not just an algorithm or working model. Instead, it’s about the value of the insight that outliers provide. That is, for a business, money saved from preventing equipment damage, money lost on fraudulent transactions, etc. In healthcare, it can mean earlier detection or easier treatment.
Anomaly detection requires a system that is agile and constantly learning because:
- The very nature of the use cases for anomaly detection (specifically in the IT and finance sectors) means often times fraudsters are specifically and deliberately trying to produce inputs that don’t look like outliers. Adapting to and learning from this reality is critical.
- Aside from malicious intents, datasets generally tend to change over time as users change, so a system needs to evolve along with those users. Anomalies, by their nature, are unexpected, so it’s important that any methods used are adaptive to the underlying data.
- Many use cases are extremely time sensitive, and businesses (or patients, customers, etc., of those businesses) can’t afford to wait. Detecting patterns early based on a combination of data points can help anticipate issues before it’s too late.
It is important to note that, despite the most common use cases being detection of fraud or system intrusion, anomalies are not always bad — that is, they don’t always have to indicate that something is wrong. Anomaly detection can also be used, for example, to detect or predict slight changes in customer or user behavior that may then result in a shift in selling, development, or marketing strategy, allowing businesses to stay a step ahead of new trends.
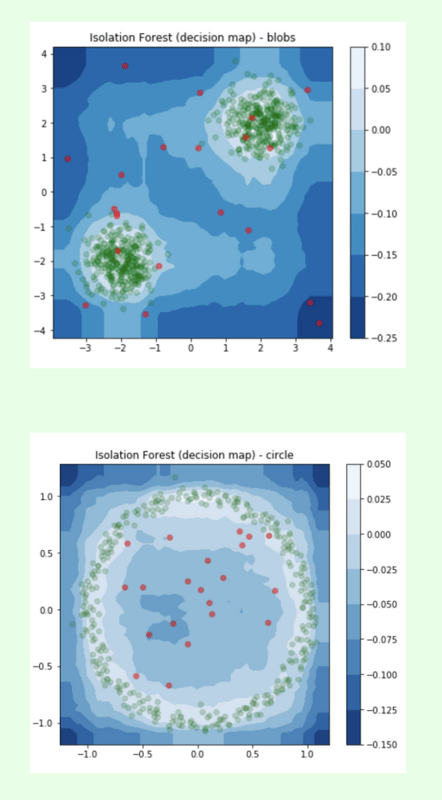 Visualizations are especially useful in the process of building and testing anomaly detection models because sometimes they are the clearest way to see outliers, especially in very large datasets.
Visualizations are especially useful in the process of building and testing anomaly detection models because sometimes they are the clearest way to see outliers, especially in very large datasets.
3 Types of Anomalies
There are three basic types of anomalies that may be detected:
- Point anomalies: Point anomalies are simply single, anomalous instances within a larger dataset. For example, a temperature of 60 degrees Centigrade in a dataset would be a point anomaly, as that would be the highest temperature ever recorded on Earth. Anomaly detection systems often start by identifying point anomalies, which can be used to detect more subtle contextual or collective anomalies.
- Contextual (or conditional) anomalies: These are points that are only considered to be anomalous in certain context. A good example is temperature again; while 30 degrees Centigrade is considered to be within the range of possible temperatures, given the context of December in New York City, this data point is certainly an anomaly. With spatial data, latitude and longitude are the context, while with time-series data, time is the context.
- Collective anomalies: When related datasets or parts of the same dataset taken together are anomalous with respect to the entire data set (even when individual datasets don’t contain anomalies). For example, say there is data from a credit card making purchase in the U.S., but also a dataset showing money being taken out of ATMs in France at the same time. A collective anomaly may occur if no single anomaly happens in any one dataset, but all datasets measuring various components taken together signal an issue.
Why?
Anomaly detection is an approach that can be useful across an array of industries and for a variety of purposes. But the underlying, unifying factor is the ability to detect small changes or differences in a system that might otherwise go unnoticed. Uncovering anomalies using machine learning allows humans (or other systems) to take action based on these outliers.
Specifically, a non-exhaustive look at use cases for anomaly detection systems include:
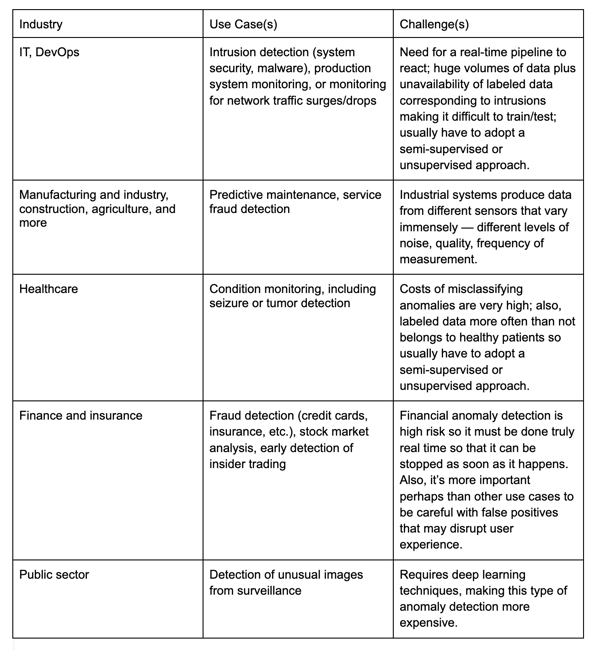
Anomaly detection can be useful in a number of other fields and industries where rare events are very important or impactful, but they are hard to find within data. Because of its wide array of applications, mastering anomaly detection from a data scientist’s perspective is an incredibly applicable use case.
How?
If you’re familiar with the seven fundamental steps to building a data project, then you already know the basics for how to get started using anomaly detection to benefit your team or business. But there are also several particularities to bear in mind when working with anomaly detection:
1. Understand the Business
The first step in successful anomaly detection is to really understand what kind of a system the business needs and to lay out framework for the requirements and goals of anomaly detection before diving in. These are important preliminary discussions because not all anomaly detection work is the same; exactly what qualifies as an anomaly and the subsequent processes kicked off by anomaly detection vary vastly by (and even among) use cases.
Notably, the nature of the data, of the problem at hand, and the goals of the project necessarily dictate the techniques employed for anomaly detection. Even within a single, specific industry like healthcare, different projects will have different definitions of what makes a datapoint an anomaly. Very small fluctuations in a system tracking body temperature, for example, could be considered anomalies, while other systems could tolerate a much larger range of inputs. So it’s not as easy to universally apply a single approach as it is for other types of data projects.
To ensure the success of a project involving anomaly detection, data team members will need to work directly together, collaborating with other non-data teams (business, operations, legal, etc., depending on the domain) to:
- Define and continually refine what constitutes an anomaly. It might constantly change, which means continual re-evaluation.
- Define goals and parameters for the project overall. For example, the end goal is probably not just to detect anomalies, but something larger that impacts the business, like block fraudulent charges, cure more patients by detecting health conditions earlier, increase revenue by anticipating future trends, etc. Having larger goals will allow you to better define the scope of the project and the expected output.
- Determine, once an anomaly is detected, what the system will do next. For example, send anomalies to another team for further analysis and review, automatic actions on an associated asset/account, etc.
- Develop a plan to monitor and evaluate the success of the system going forward.
- Identify what anomaly detection frequency (real time vs. batch) is appropriate for the business and the use case at hand.
2. Get Your Data
Having as much data for anomaly detection as possible will allow for more accurate models because you never know which features might be indicative of an anomaly. Using multiple types and sources of data is what allows a business to move beyond point anomalies into identifying more sophisticated contextual or collective anomalies. In other words, variety is key.
For example, looking at fraud detection, it’s possible that transaction data isn’t anomalous because the fraudster has stayed within the “normal” range of the actual user’s habits. But data from ATM use or account weblogs may reveal anomalies.
3. Explore, Clean, and Enrich Data
When doing anomaly detection, this stage is even more important than usual, because often the data contains noise (usually errors, either human or not) which tends to be similar to the actual anomalies. Hence, it is critical to distinguish between the two and remove any problematic data that could produce false positives.
In an ideal world, you’d have a sufficient amount of labeled data from which to begin; that is, you’d be able to enrich the datasets you have with information on which records represent anomalies and which are normal. If possible, starting with data you know is either anomalous or normal is the preferred way to begin building an anomaly detection system because it will be the simplest path forward, allowing for supervised methods with classification (as opposed to unsupervised anomaly detection methods).
For some of the use cases detailed above, this is likely very attainable. Specifically in financial for fraud detection or manufacturing/industry for predictive maintenance because there is a clear mechanism for feedback on which cases where anomalous (customer relationship manager data detailing fraud complaints or maintenance records). For other use cases, like condition monitoring in healthcare or intrusion detection, having enough labeled data from which to begin could be difficult, though it’s still possible to successfully detect anomalies without labeled data.
4. Get Predictive
There are two primary architectures for building anomaly detection systems:
- Supervised anomaly detection, which you can use if you have a labeled dataset where you know whether or not each datapoint is normal or not.
- Unsupervised anomaly detection, where the dataset is unlabeled (i.e., whether or not each datapoint is an anomaly is unreliable or unknown).
When using a supervised approach, you’ll apply a binary classification algorithm. Exactly which algorithm is less important than making sure to take the appropriate measures regarding class imbalance (i.e., the fact that for anomaly detection, it’s highly likely that you have far more “normal” cases than anomalous ones).
When using an unsupervised approach, there are two ways of training your algorithms:
- Novelty detection: The training set is made exclusively of inliers so that the algorithm learns the concept of "normality" (hence the prefix "one-class" found in some methods). At test time, the data may also contain outliers. This is also referred to as semi-supervised detection.
- Outlier detection: The training set is already polluted by outliers. The assumption is made that the proportion of outliers is small enough, so that novelty detection algorithms can be used. Consequently, those algorithms are expected to be robust enough at training time to ignore the outliers and fit only on the inliers.
5. Visualize
Visualizations are especially useful in the process of building and testing anomaly detection models because sometimes they are the clearest way to see outliers, especially in very large datasets.
6. Deploy and Iterate
To have real impact with an anomaly detection system, your model should be scoring data real time in production. Anomaly detection is generally time sensitive, so going to production to make predictions on live data rather than retroactively on test or stale data is more important than ever.
But putting a model in production isn’t the end. Iteration and monitoring of anomaly detection systems is critical to ensuring that the model continues to learn and be agile enough to continue detecting anomalies even as user behaviors change. However, unlike other types of machine learning models, accuracy is not a viable metric for anomaly detection. Since the vast majority of data is not composed of anomalies (i.e., there could be hundreds of thousands of “normal” data points), the system could achieve a very high accuracy but still not actually be accurately identifying anomalies.
Looking Ahead
Because of the breadth of its utility, especially as fraudulent activity and attacks on systems become more pervasive, anomaly detection will continue to become more sophisticated. There have been, and will continue to be, developments in the realm of anomaly detection with unstructured data (like images and text). Developments in anomaly detection using deep learning in imaging will be particularly influential in healthcare.
Additionally, developments will go from pure detection of anomalies to automated prevention techniques. Being able to stop potentially harmful anomalous behavior before it happens has the potential for broad impact in the years to come, particularly, again, when it comes to cyber security and fraud detection.
And finally, in the years to come as more and more industries hinge on anomaly detection, expect to see an overall streamlining of anomaly detection processes as businesses continue to scale. This means more and more companies investing in the right architecture to retrieve data critical for anomaly detection work, the means to process it quickly, and apply models for impact in production.