




{kind=link}
Today, there (probably) isn’t a single company out there that would release a piece of software without testing it. Testing can ensure quality, save money, and eliminate risk. So it goes without saying that machine learning (ML) systems should also be tested.
Between 2016 and 2017, Google published two papers on building robust architecture for ML, including rubrics for self-assessment of one’s architecture. One of the underlying tenets of both papers (that, it’s worth noting, many companies spinning up their ML capabilities today tend to overlook or downplay) is the fundamental difference between testing software and testing machine learning systems.
Testing ML is different than testing software because of multiple steps (offline and online) and possible failure points (data needs to be tested, monitored, etc.). In addition, software testing is relatively simple because for every input, there is a known, defined output — not so with ML systems:
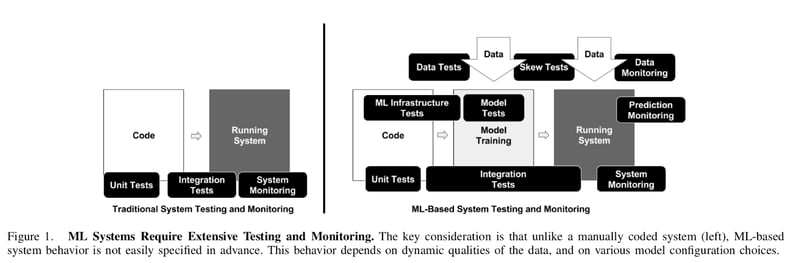
Given the number of steps involved and these potential points of failure, naturally, evaluation of a ML-based system is significantly more complicated as well. Google’s test score self-assessment looks at 28 criteria in four groups. Here’s the gist:
- You shall maintain all features in a schema, keeping only meaningful features that are not too complex to build (compared to what you want) and that can be used from a privacy or regulatory standpoint in your industry. All of that is tested programmatically.
- You shall build models in a historized environment, optimizing model parameters and doing regular checks against baseline models (with a good understanding of the model quality per the business metric and over all subparts of the data).
- You shall build fully integrated ML pipeline that you can easily debug and where everything is tested before pushing to production (plus it must be easy to rollback).
- You shall build a monitoring practice that monitors for unavailability or changes in input data, inconsistencies between training and scoring sub-parts, decrease in model statistical quality, or overall speed of the system.
More specifically, here are the criteria in their groups:
- Data 1: Feature expectations are captured in a schema.
Data 2: All features are beneficial.
Data 3: No feature’s cost is too much.
Data 4: Features adhere to meta-level requirements.
Data 5: The data pipeline has appropriate privacy controls.
Data 6: New features can be added quickly.
Data 7: All input feature code is tested. - Model 1: Every model specification undergoes a code review and is checked in to a repository.
Model 2: Offline proxy metrics correlate with actual online impact metrics.
Model 3: All hyperparameters have been tuned.
Model 4: The impact of model staleness is known.
Model 5: A simpler model is not better.
Model 6: Model quality is sufficient on all important data slices.
Model 7: The model has been tested for considerations of inclusion. - Infra 1: Training is reproducible.
Infra 2: Model specification code is unit tested.
Infra 3: The full ML pipeline is integration tested.
Infra 4: Model quality is validated before attempting to serve it.
Infra 5: The model allows debugging by observing the step-by-step computation of training or inference on a single example.
Infra 6: Models are tested via a canary process before they enter production serving environments.
Infra 7: Models can be quickly and safely rolled back to a previous serving version. - Monitor 1: Dependency changes result in notification.
Monitor 2: Data invariants hold in training and serving inputs.
Monitor 3: Training and serving features compute the same values.
Monitor 4: Models are not too stale.
Monitor 5: The model is numerically stable.
Monitor 6: The model has not experienced a dramatic or slow-leak regressions in training speed, serving latency, throughput, or RAM usage.
Monitor 7: The model has not experienced a regression in prediction quality on served data.
Improving Your Score
In case you didn’t notice, this list of criteria is both incredibly broad and incredibly thorough. Developing home-grown ways of addressing each of these criteria in hopes of improvement is expensive in terms of both time and resources. So how, then, can a company improve its Google ML Test Score meaningfully?
 Want to improve your Google ML Test Score? Use a data platform.
Want to improve your Google ML Test Score? Use a data platform.
One of the easiest ways is with an underlying platform built for the explicit purpose of developing, deploying, and maintaining ML-based systems. Data science, machine learning, or AI platforms offer — or should offer, if you’ve chosen the right one — capabilities that check off many of the categories in all four groups.
Of course, no platform is a magic bullet that will immediately optimize architectures and environments for perfect models, every time. But using one is a good start toward some level of automation and consistency that can boost a score, especially if the previous methods were manual and inconsistent. Plus, the good news is that these platforms are getting better and more robust every day, adding additional features to make ML-based systems easier to build as well as to maintain.
So who knows? Maybe one day we’ll see testing machine learning systems as the software systems of today, focused instead on testing the next type of cutting-edge system.