




{kind=link}
It’s hard to believe, but we’ve reached the end of another year.
Despite constant change and uncertainty in the world around us, one thing at Dataiku definitely hasn’t changed: our commitment to product innovation. If anything, we’ve doubled down, increasing the pace of product updates to provide our customers with new ways to be more efficient and successful at delivering Everyday AI.
As we prepare to flip the calendar over to 2023, let’s take a moment to look back and celebrate some of Dataiku’s finest engineering accomplishments during the past 12 months. For fun and nostalgia’s sake, I’ve compiled a yearbook style list so you can get to know my favorite new features a bit better (yes, everyone gets a trophy today). So without further ado, I present to you:
The Class of 2022 Superlative Awards!
⭐ Brightest Future: Visual Time Series Forecasting
⭐ Most Inclusive: MLflow Integrations
⭐ Most Likely to Tell It Like It Is: Model Evaluation Store With Automated Drift Analysis
⭐ Biggest Geek: Code Studios
⭐ Most Photogenic: Computer Vision and Managed Labeling
⭐ Teacher’s Pet: Dataiku Govern
⭐ Most Judgmental: Model Comparisons
⭐ Most Optimistic: What-If Accelerators
⭐ Model Citizen: Feature Store
⭐ Most Likely to Succeed: Dataiku Business Solutions
Below each superlative, be sure to click on the feature name for a short video highlighting how the feature works.
Brightest Future
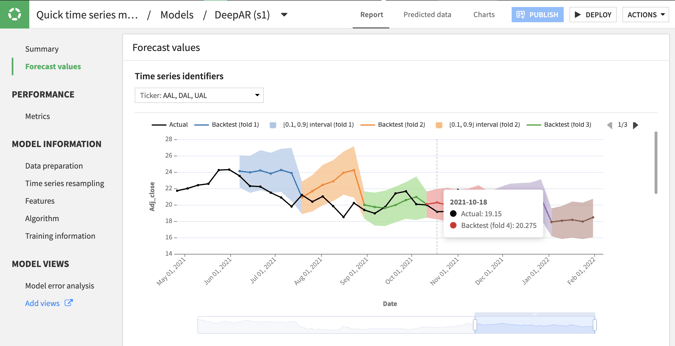
Visual Time Series Forecasting
Analysts rejoice! No-code time series capabilities help analysts and subject matter experts generate robust statistical analyses on time series data and visually develop, deploy, and monitor forecasting models — all in the familiar Dataiku framework. The visual forecasting interface includes easy-to-use settings for resampling, time step parameters and forecast horizons, and a comprehensive set of statistical and deep learning algorithms.
Most Inclusive
Interoperability between Dataiku and MLflow means expert data scientists and ML engineers can benefit from the best of both worlds, mixing and matching the frameworks across the model lifecycle. For example, programmatically design, experiment, and train models with MLflow in external development environments, but import experiment artifacts and model objects into Dataiku for model registration, deployment, and governance. The reverse scenario is also possible: Design and train models in Dataiku’s framework and export the artifacts in MLflow (or Python) formats for deployment and inference in external systems.
Coders will also appreciate the additional advantages Dataiku provides for external models, such as automatic visualizations for experiment comparisons and a full panel of pre-built model explainability and interpretability reports.

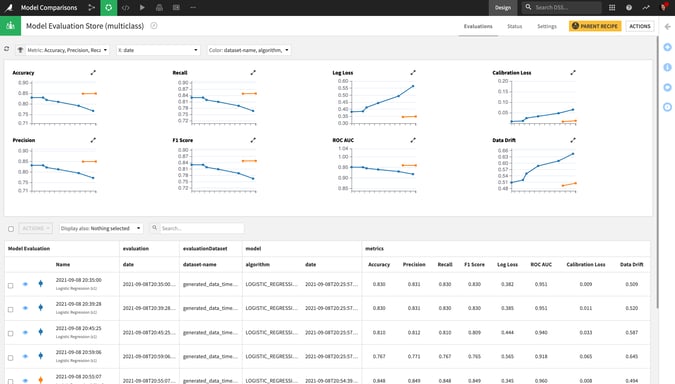
Most Likely to Tell It Like It Is
Model Evaluation Store With Automated Drift Analysis
Just like your high school valedictorian can probably tell you, being the best performer at a point in time doesn’t guarantee you the top spot forever. For live models in production, the model evaluation store is the continuous feedback tool that ML operators need to monitor model performance and detect issues. Historical views of key metrics across generations of model versions provide valuable context, and built-in drift analysis helps pinpoint the root cause of model degradation to inform next steps.
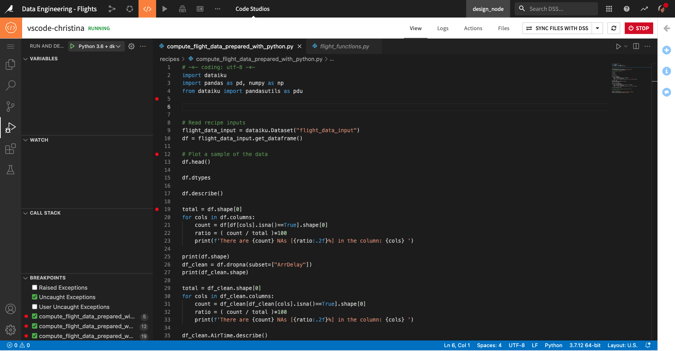
Biggest Geek
People are most comfortable and efficient using the tools they’re familiar with, and coding is no exception. Code studios in Dataiku make it simple for you to programmatically contribute to Dataiku projects using personal, embedded instances of your preferred web-based IDE (e.g., Visual Studio Code, JupyterLab, RStudio). You can develop custom web applications using the Streamlit framework or edit and debug code libraries, recipes, and other objects using your favorite code editor, all without ever leaving the project.
The elastic Kubernetes backend and automatic synchronization with project files means more time solving problems and less time configuring environments and compute resources.
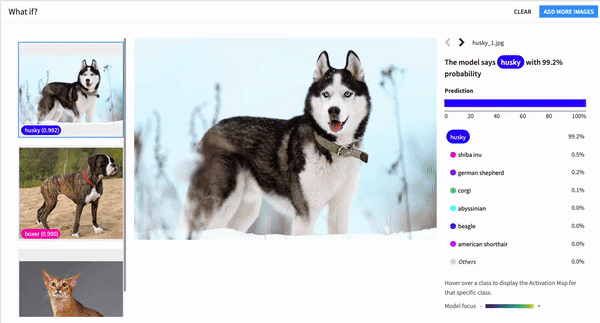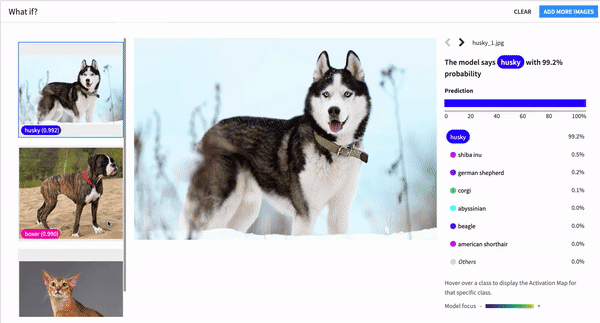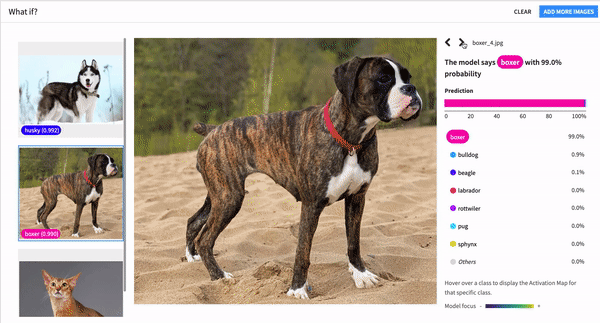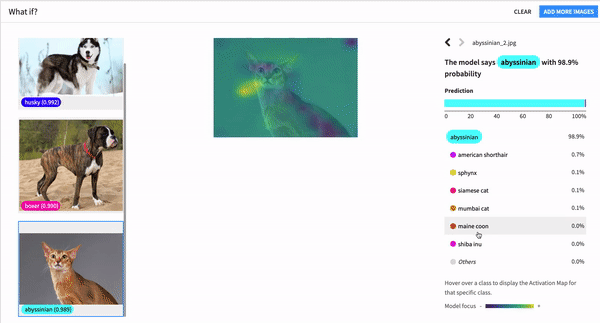
Most Photogenic
Computer Vision and Managed Labeling
Guided visual tasks for image classification and object detection mean that, with little to no code needed, data professionals of all types can now tackle deep learning projects. Prepare and augment training images, use pre-trained models and transfer learning to bootstrap a deep learning model tailored to your data, and deploy and govern the model — all in Dataiku’s familiar platform. Even better, Dataiku’s managed labeling framework helps teams orchestrate and oversee large data labeling initiatives with class-level instructions, consensus requirements, labeling conflict detection and resolution, and team performance and progress reports.
Teacher's Pet
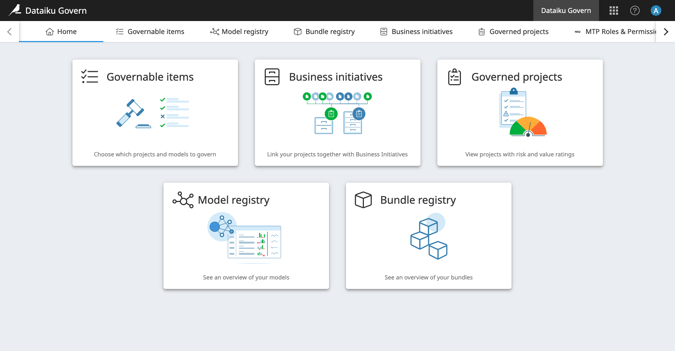
You know the type: smart, responsible, organized, helpful, involved. The Govern module of Dataiku has all these qualities of the classic teacher’s pet, and is a critical scaffolding component for companies wishing to build an effective AI Governance system. Dataiku Govern provides a central space to document and standardize AI rules, requirements, and processes aligned to your organization’s priorities and values. Model and bundle registries, risk/value qualifications, and review & signoff workflows are just a few examples of the capabilities included with this powerful component.
Most Judgmental
Ever used an online comparison tool when buying a car, health plan, or electronic device? Sometimes seeing all the specs for each option in a single view is what you need to determine the best choice for you. Model comparisons in Dataiku provide that pre-built scorecard for data scientists and ML operators, helping them perform champion/challenger analysis and identify differences in feature handling, performance metrics, and run times. Visualize models of all types (lab candidates, saved model versions, externally developed “foreign” models, etc.) in a side-by-side view.
Most Optimistic
What’s the best outcome that could happen, and what do we need to do to get there? Like any good optimist, Dataiku’s accelerators for what-if analysis address these very questions. These tools take interactive scoring to the next level, enabling everyone from data scientists to business users to discover which specific changes would lead to a different (or optimal) outcome.
For classification models, counterfactual and actionable recourse analysis “explores the neighborhood” to prescribe incremental changes to model inputs that would result in a different predicted class. For regression models, outcome optimization gives you the most plausible changes that would result in a minimum, maximum, or specific predicted value.
Model Citizen
As the model citizen award winner, Dataiku’s feature store gets a gold star not only for indexing the best reference datasets an organization team has to offer, but also for helping others succeed. By promoting high-quality datasets to the feature store, data scientists make it more efficient for teammates to discover and then reuse curated features in their own projects. Details about dataset lineage, data freshness, storage location, and sharing status make “shopping” for suitable reference data and features easier than ever before.
Most Likely to Succeed
While not technically a single feature, Dataiku’s ever-growing roster of industry and business solutions wins the award for most likely to succeed because these off-the-shelf packaged projects are designed to be plug and play! These implementations for common use cases like customer segmentation, demand forecasting, process mining, and product recommendations are an easy way to shortcut development cycles and make the most out of your Dataiku investment. Each project comes with pre-built user applications and dashboards, a detailed wiki and documentation, and a fully functional Flow. Check out the list of Dataiku solutions here.
What's Next?
Hopefully you enjoyed the awards show as much as we did. It’s hard to believe this is only the tip of the iceberg of what our developers and engineers delivered during 2022. As we roll into 2023, keep an eye out for even more new features as we continue to enhance Dataiku 11 and then beyond, when we release the next major version of the product: Dataiku 12. Until then, I wish you a wonderful holiday and happy new year!