




{kind=link}
The fact that we can analyze the use of words in language to deduce their meaning is a fundamental idea of distributional semantics called the “distributional hypothesis”. This is the inspiration behind many algorithms for learning numerical representations of words (also called word embeddings). An important aspect of these representations is the ability to solve word analogies of the form “A is to B what C is to X” using simple arithmetic. This is generally simplified as “King — Man + Woman = Queen. In this article, we will try to shed some light on this result by giving a framework under which such relations do arise.
We will also quickly go over the main techniques for learning word embeddings (Word2vec, GloVe and fastText). The objective is not to go over each and every embedding model in detail, but rather to get the most important idea that is associated with each technique. For a detailed explanation of how Word2vec works, refer to the reference section below.
Another interesting thing about word vectors is the misconception that we either need deep learning or neural networks to compute them. In practice, none of the above are necessary and we will see how we can learn good word vectors using plain Singular Value Decomposition (SVD).
Sparse Representations
Viewing words as discrete units
A simple way to represent words is through one-hot representations (a one-hot representation of a word is a N-dimensional vector with only one non-zero position corresponding to the index of that word). Let’s index the vocabulary V by the set {1, …, N}.

Viewing all the words as discrete units is not ideal and the first problem that we would face when using one-hot representations is a sparsity problem. In fact, since there can be hundreds of thousands of words in a given language, representing and storing words as one-hots can be extremely expensive.
Another (more serious) problem is the lack of an inherent similarity notion. In fact, a simple way of measuring the similarity between two vectors is using the cosine similarity. But since the one-hot vectors of any two different words are necessarily orthogonal, taking the dot product of even two synonyms would yield a similarity score of 0.
Dense Representations
Word2vec: learning embeddings by predicting word contexts
In 2013, Tomas Mikolov et al. developed an algorithm for learning word embeddings called Word2vec [paper][code]. This algorithm uses a shallow neural network to learn word vectors so that each word of a given corpus is good at predicting its own contexts (Skip-Gram) or vice versa (CBOW).
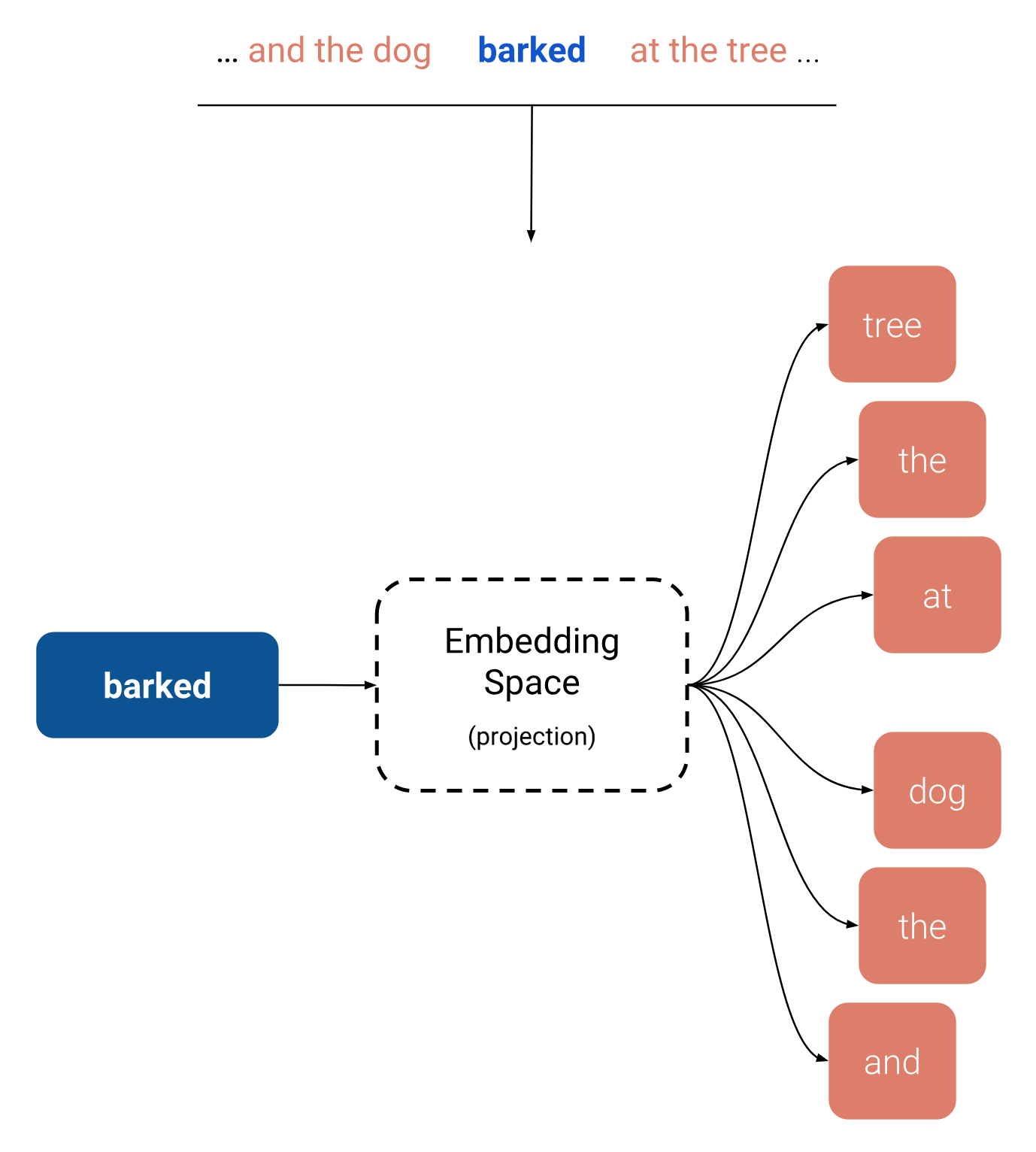
Empirical results using these methods seem to show that this approach is successful at learning the meaning of words. In fact, the resulting embedding space seems to have directions of semantic and syntactic meaning that can be exposed through simple operations on word vectors.
For example, we can retrieve words that have semantic relations such as Country-Capital:
vector(Paris) — vector(France) + vector(Morocco) ~ vector(Rabat)
As well as words that have syntactic relationships such as the Singular-Plural:
vector(Kings) - vector(King) + vector(Person) ~ vector(People)
How can we explain the arithmetic of word vectors?
In a recent paper by Gittens et al. a demonstration is given about how such relations can emerge. The authors start by assuming that a word c has the same meaning as the set of words C when, for any other word w:
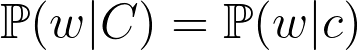
Given a set of words C, trying to find the word c that verifies the equation above is complicated. Therefore, the authors propose to look for a word that minimizes the “distance” between the two conditional distributions:
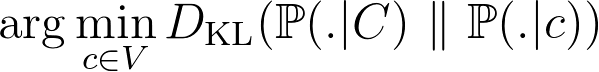
where KL denotes the Kullback-Leibler divergence and V denotes the set of all possible words (vocabulary). Such a word is called the paraphrase of C.
The authors then prove (theorem n°1) that if the model is log-linear:
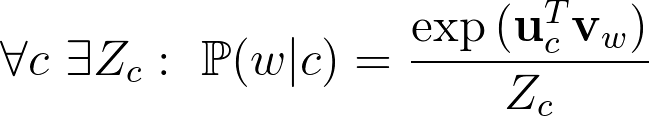
and if we assume conditional independence of word distributions:
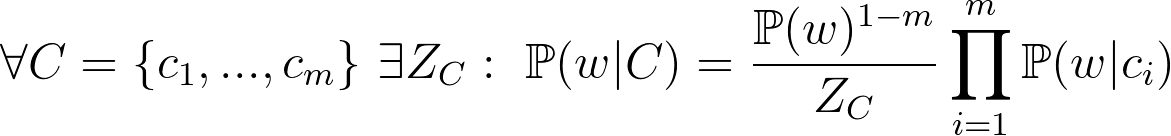
then the paraphrase word c verifies:
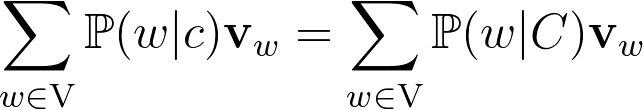
Finally (theorem n°2), they assume that words are uniformly distributed, which allows them to prove that the paraphrase word vector is:
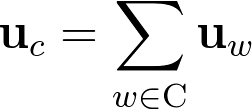
[TLDR] Basically, if we assume that:
- All the words are distributed uniformly,
- The embedding model is log-linear and
- The conditional distributions of words are independent,
- Then the embedding of the paraphrase of a set of words is obtained by taking the sum over the embeddings of all of the individual words.
Using this result, we can very easily recover semantic relationships such as Man:Woman::King:Queen as follows:
ManandWomanshare the relationship Male-Female. This means thatManis the paraphrase of{Woman, X}whereXis the abstract set of all the words that encode the relationship Male-Female.- Since
KingandQueenshare the same Male-Female relationship, thenKingis the paraphrase of the set of words{Queen, X}.
Using theorem n°2, we get:
Note:This proof is an interesting attempt at explaining the directions of semantic and syntactic meaning in Word2vec and other models. But it also assumes something inaccurate about the distribution of words. In fact, word distributions are not uniformly distributed, they are instead considered to follow Zipf’s Law.
GloVe: learning embeddings from word co-occurrence
One year after the publication ofWord2vec, Pennington et al. developed a new algorithm for learning word embeddings calledGloVe[paper][code]. This algorithm is based on the observation that word relationships can be recovered from the co-occurrence statistics of any (large enough) corpus.
LetXijbe the number of times wordsiandj“co-occur” in a given corpus, andXibe the number of times the wordioccurred in general. Provided the corpus is large enough, we can consider that the probability that a wordioccurs next to the wordjis:

We can discover relationships between words by looking at ratios of these probabilities. For instance, by computingP(j|"ice")/P(j|"steam")for many words j, the highest and lowest values would be those of solid and gas, informing us that “ice” is to “solid” what “steam” is to “gas”.
The authors sought to build a model F that encodes these semantic and syntactic relationships as linear operations on their word vectors:
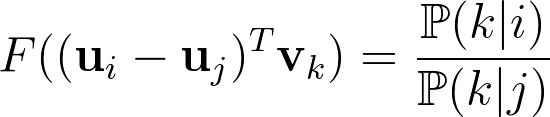
Here u denotes the word vector and v denotes the context word vectors. This choice is arbitrary, therefore the model should be symmetric for the transformation u ←→ v. This is achieved in two steps.
First,Fshould be a homomorphism between the groups (R,+) and (R+, ×):

Which implies thatFis the exponential function. This means that:
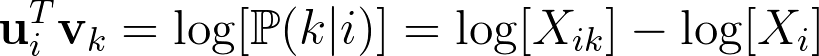
Since the last logarithm is independent fromk, it can therefore be absorbed in a biasbi. Adding a second biasbkcompletes the symmetry of the model:
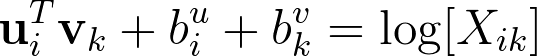
GloVe seeks to verify this equality for every possible pair of wordsi&jby minimizing the weighted least-squares objective:
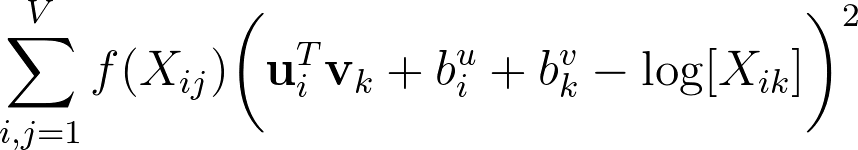
Wherefis a weighting function that needs to be 0 whenXij = 0in order to ensure that the logarithm is well-defined:
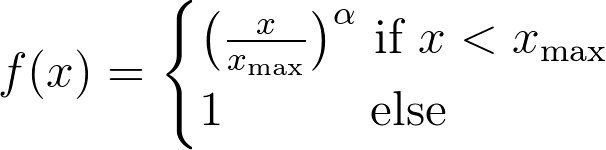
where the cut-off parameterx_maxis set to 100.
Note: If we ignore the biases in the previous training objective, we see that the algorithm tries to make the dot product of the word and context vectors as close as possible to the logarithm of the words’ co-occurrence. We can interpret this as GloVe implicitly factorizing the logarithm of the co-occurrence matrixX.
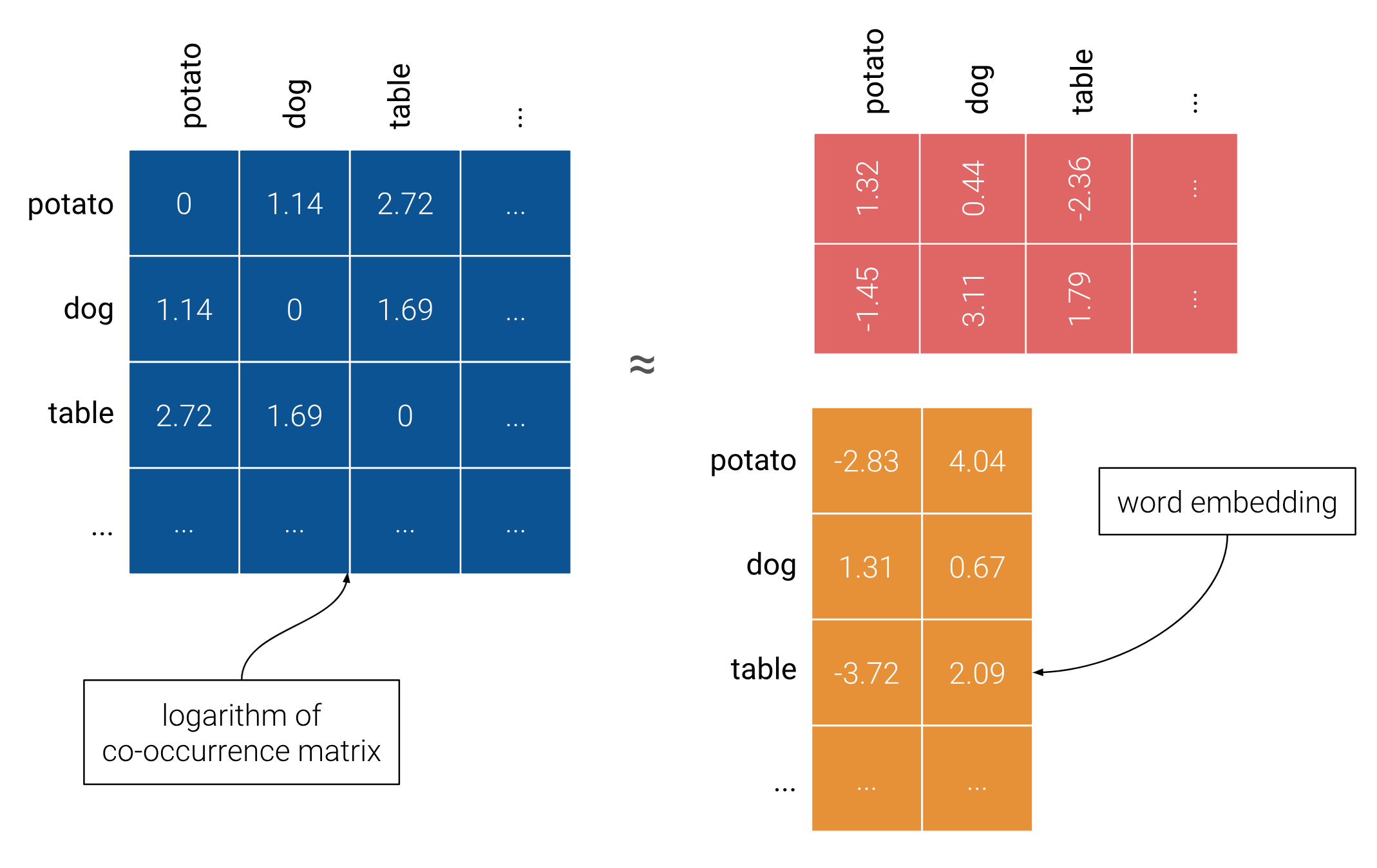
Note:From a memory point of view, computing an entire co-occurrence matrix can be expensive. But since this operation is only done once, and since the resulting word vectors are dense, GloVe doesn’t entail any storage/memory issue.
fastText: robust embeddings using subword information
An issue with GloVe and Word2vec is that they only learn embeddings for words of the vocabulary. As a result,Out-of-vocabulary(OOV) words don’t have a vector representation and are usually either represented by a vector of zeros, by the average of all word vectors or simply ignored from the sentence. In 2016, Bojanowski et al. [paper][code] publishedFastText, a method for learning word embeddings using subword information that solves this issue.
Note:The name “FastText” actually stands for two different -but related- algorithms. On one hand there is the embedding method we are interested in. But on the other hand there is also the “FastText” classification algorithm that uses optimization tricks for efficiently classifying texts [paper]. This classifier may or may not use FastText embeddings depending on the user’s choice.
In short, FastText (embedding technique) learns embeddings of character n-grams, i.e. sequences of n successive characters. After the training, the embedding of each word is computed as the sum of its constituent n-grams.
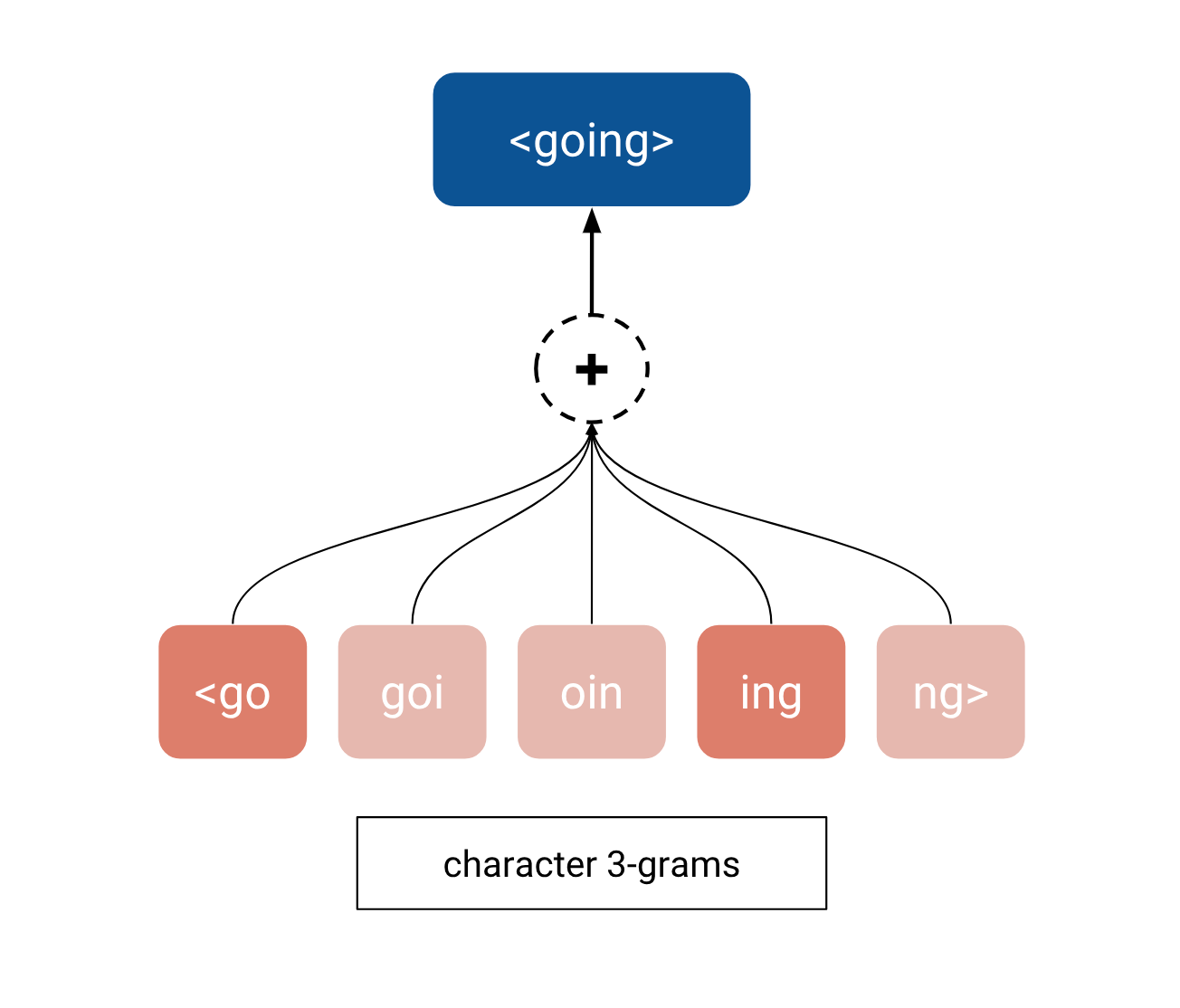
In the example above, we suppose that the wordgoingis out-of-vocabulary. Using FastText with n=3, the embedding forgoingcan be obtained as the sum of its character 3-grams. Among all of these n-grams, those of<goandingmight inform us that the wordgoingis a continuous action related to the verbgowithout the wordgoingactually occurring in the training data.
A Simpler Approach
Factorizing a co-occurrence matrix using SVD
While the first successful techniques for learning word embeddings all relied on neural networks (Bengio et al. 2003, Collobert and Weston 2008), the performance of recent embeddings methods proved that none of that was necessary. In fact, Word2vec is barely a neural network since it has no hidden layers and no non-linearities but still achieves good results. Then, GloVe implicitly factorizes a co-occurrence matrix and achieves even better results. So how simple can a model be and still learn good word embeddings ?It turns out, as it is explained in this great post by Stitch Fix, that we can directly factorize a co-occurrence matrix and get good word embeddings. In practice, we can follow these simple steps:- Compute the probability of occurrence of each word
p(x) - Compute the probability of co-occurrence of each couple of words
p(x,y) - Divide each co-occurrence probability by each word’s probability
p(x,y)/p(x)p(y) -
Apply the logarithm to the ratio:
log[p(x,y)/p(x)p(y)].
This last value is called called Point-wise Mutual Information(PMI). Since many words never co-occur, this means the logarithm might be ill-defined. To avoid that, we turn any negative PMI value into a 0. This statistic is now called PPMI for Positive Point-wise Mutual Information.After computing the PPMI matrix the only thing that is left to do is to decompose that matrix using SVD to get fresh word embeddings. But you may think that these embeddings are not as good as Word2vec or Glove’s. After all, a simple SVD can't be as good as more complex models right ?
In 2014, Levy and Goldberg demonstrated that word vectors learned via SVD on the PPMI matrix could outperform Word2vec embeddings on analogy tasks — provided a slightly different similarity measure is used. Moreover, they also showed that these word vectors also learn directions of word meaning just as Glove and Word2vec vectors do.
Conclusion
Research about word embeddings is still ongoing. If simple approaches give satisfying word embeddings, more sophisticated models can add more expressivity. For example, the recent modelELMo(Peters et al, 2018) [paper][code] relies on an arsenal of CNNs and bi-LSTMs to learn contextualized word vectors. These vectors can then be added to regular embeddings such as GloVe to enrich them with information about the context of a word, which would help differentiating the word “play” in the context “I loved this play” and “Let’s play together” for example.
Computing meaningful word representations is the first step towards real machine language understanding. In fact, before a machine is able to understand complete sentences as can Siri or Alexa do, it needs to be able to produce good sentence representations (or sentence embeddings). This will be the topic of the next post so make sure not to miss it!