




{kind=link}
This blog post was originally published in October 2018 on Data From the Trenches.
TL;DR: As data science evolves as a discipline, we think that it’s time to have a more systematic approach to feature engineering. That’s why we built EventsAggregator, an automatic feature engineering framework that leverages user’s knowledge to generate expressive features. The goal is to have a versatile, modular and interpretable pipeline that is domain-free .
Disclaimer: EventsAggregator is currently available as a Python library and plugin on Dataiku. We hope to be able to make it open source in the near future.
Feature Engineering: The Heart of Data Science
“Feature engineering is the process of transforming raw data into features that better represent the underlying problem to the predictive models, resulting in improved model accuracy on unseen data.”
— Dr. Jason Brownlee
The groundwork for this field was laid long before the hype of Kaggle and machine learning, with KPI design.
Key Performance Indicators (KPIs) are crucial for companies of all sizes. They offer concrete metrics on business performance. Take the classic RFM (recency, frequency, monetary value) paradigm that is used by retailers to measure customer value. More recently, the Power User Curve is an interesting example of how thoughtful metrics help companies understand user engagement in a complex context.
We believe that a good feature engineering tool should not only generate sophisticated indicators, but should also keep them interpretable so that data scientists can use them either for the machine learning models or for the KPI dashboards.
The Need for Automated Feature Engineering
Imagine you are working for an e-commerce company. You have collected transactional data and are now almost ready to make some magic with machine learning.
The task at hand is churn prediction: you want to predict who might stop visiting your website next week so that the marketing team has enough time to react.
Before doing any feature engineering, you need to choose a reference date in the past, in this case it will be 2018–09–01. Only data before that date will be taken into account by the model, which predicts the churners of the week after 2018–09–01. This is a way to make sure that there is no data leaking: we are not looking at the future to predict the past.
As an experienced data scientist, you know that one important feature for this type of problem will be the recency of the client: if the timespan between two visits of a client is increasing, that’s an alert to potential!
You put on your SQL ninja hat and write the following PostgreSQL query:
SELECT user_id,
AVG(time_interval)/(3600*24) as mean_interval_between_group_1_in_days,
STDDEV_POP(time_interval)/(3600*24) as std_interval_between_group_1_in_days
FROM
(
SELECT user_id,
event_timestamp,
extract(epoch from event_timestamp) - lag(extract(epoch from event_timestamp))
over (PARTITION BY user_id order by event_timestamp) as time_interval
FROM "My_big_transactional_table"
WHERE event_timestamp <= (cast( ' "2014-09-01 00:00:00" ' as date) - INTERVAL '7' DAY)
) as table_layer_2
GROUP BY user_id
This is fine, but now you want to go further: you want to add a time filter to capture long and short term signals, then you want to compute this feature for each type of activity the user does, and then you want to add some more statistics on top of these results, and then …
You get the idea, the list of ideas keeps growing exponentially, and this is just for one feature!
EventsAggregator to the Rescue
Now let’s see how things change with EventsAggregator.
First, we need to instantiate the feature_aggregator object as follows:
from feature_aggregations import AggregationParams, CardinalityLimiterParams, FeatureAggregator
aggregation_params = AggregationParams(
time_reference_type='fixed_timestamp',
keys=['user_id],
timestamp_column='event_timestamp',
selected_aggregation_types=['RECENCY'],
windows={'month':[6, 12], 'week':[1,3]}, # compute same type of features for
# different window size
auto_infering_col_type=True)
cardinality_limiter_params = CardinalityLimiterParams()
feature_aggregator = FeatureAggregator(
aggregation_params=aggregation_params,
cardinality_limiter_params=cardinality_limiter_params
)
We then apply the feature_aggregator to the input dataset:
transform_params = TransformParams(buffer_unit = 7,
buffer_value = 'day',
ref_date='2018-09-01')
feature_aggregator.fit(input_dataset)
feature_aggregator.transform(input_dataset='raw_transaction_log',
output_dataset='enriched_transaction_log',
transform_params=transform_params)
Under the hood, feature_aggregator generates a set of SQL queries corresponding to our criteria.
For example, you can see below one of the generated queries for the Postgres database, where it considers only the 6 most recent months of history:
DROP TABLE IF EXISTS recency_feature_group_1;
CREATE TABLE recency_feature_group_1 AS
(
SELECT *,
CASE WHEN std_interval_between_group_1_in_days IS NULL OR std_interval_between_group_1_in_days = 0
THEN NULL
ELSE mean_interval_between_group_1_in_days/std_interval_between_group_1_in_days
END as cv_interval_group_1
FROM
(
SELECT user_id,
AVG(time_interval)/(3600*24) as mean_interval_between_group_1_in_days,
stddev_pop(time_interval)/(3600*24) as std_interval_between_group_1_in_days
FROM
(
SELECT user_id,
event_timestamp,
extract(epoch from event_timestamp)
- lag(extract(epoch from event_timestamp))
over (PARTITION BY user_id order by event_timestamp)
as time_interval
FROM "My_big_transactional_table"
WHERE event_timestamp::timestamp <=
(cast( ' "2014-09-01 00:00:00" ' as date) - INTERVAL '7' DAY)
AND
event_timestamp::timestamp >=
(cast( ' "2014-09-01 00:00:00" ' as date)
- INTERVAL '7' DAY - INTERVAL '6' MONTH)
) as table_layer_2
GROUP BY user_id
) as table_layer_3
)
Companies face similar problems whether it’s churn prediction, fraud detection, or recommendation systems. Even though they have their own specificities (difference in the data or in the domain knowledge), they share enough similarities that makes a generic approach possible.
It all boils down to a generalizable relationship: similar problems share the same logic and data model. More concretely, for the use cases listed above, the data always incorporates a notion of time and hence of events.
The goal of feature engineering in these use cases is to enrich the information we have about the event itself. The most important and significant features are those that reflect the evolution of the events over time. But how can we leverage this high-level understanding of the problem and automate the tedious process of generating features one by one ?
One of the first approaches that attempted to answer this question was Zipline, an internal tool at Airbnb. It can be described as a training feature repository that provides a wide range of predefined queries to their data scientists.
On the open-source side, there is featuretools, the Python library for automated feature engineering behind Deep Feature Synthesis: Towards Automating Data Science Endeavors. Another solution was recently proposed by SalesForce’s TransmogrifAI, a Scala library for Machine Learning Automation.
However, as data scientists often work with various SQL-databases (whether it is traditional SQL like Postgres, MySQL, Oracle,… or on distributed cluster like Hive, Impala,…), we believe the ideal automated feature engineering framework should be generic in that respect: we define the logic and the framework takes care of the translation to the correct SQL-dialect. That’s what we aimed for with EventsAggregator.
Deep Dive Into EventsAggregator
EventsAggregator allows data scientists to generate expressive features based on their high-level understanding of the data and problem at hand. It does all the grunt work for the data scientist while (s)he is still in control of the output generated.
It applies multiple predefined feature functions over the raw features of the dataset. The temporal aspect is crucial in the process, and we take it into account in two different levels: by group or event.
In our framework, each row of the input dataset should correspond to an event. This means:
- Each row belongs to a group, defined by one or several aggregation keys.
- It has a timestamp (i.e. has a date field)
- There are (numerical or categorical) features describing the event.
We will again turn to a typical transactional dataset as an example, where each row represents the event of a client purchasing a product for a certain amount. The group here is thus the client.
Each transaction comes with information such as the product’s price, product’s type, date of purchase,…
When feature engineering for this type of model, our goal is twofold:
- We want to have more information summarizing the group’s state (here is the client) in a specific time window. This means information concerning the general statistics of columns describing the group. We hope to answer questions such as “How much did he spend in the last three months or the last three transactions?” or“Among all the products bought, what is the percentage of groceries ? of clothes ?”, etc.
- We want to have more information characterizing the evolution of the group’s events through time: the frequency (occurrence of events) and recency (interval between events). So we’d like to know “How many times did the client purchase a product in the last 6 months?” or “When was the last time that he purchased something ?”
Our package generates multiple feature families, with the capacity to produce hundreds of features. Besides the two families in the example above, there are also:
- Information function: Statistics on subject’s state. For example, average amount spent in the last n days/weeks/months.
- Distribution function: Percentage of distinct values in a categorical column. For example, percentage of events that happened on Sunday.
Another important aspect of EventsAggregator is temporal aggregation, which exists on two levels:
- One-shot aggregation by group: For each group, we aggregate all their events in order to have a general view of the group. Churn prediction is a good example, as we want to know whether or not the customer will stop using the product, based on their historical activities.
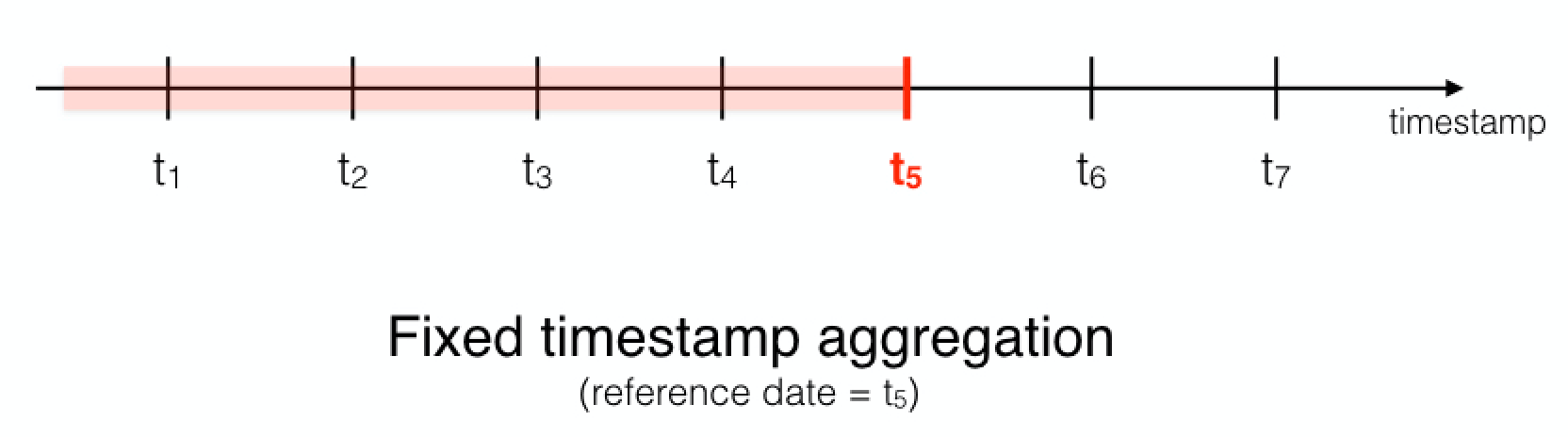
- Sequential aggregation by event: For each group, we aggregate features sequentially by event. One example use case is fraud detection, where we need to analyze the user’s behavior transaction by transaction.
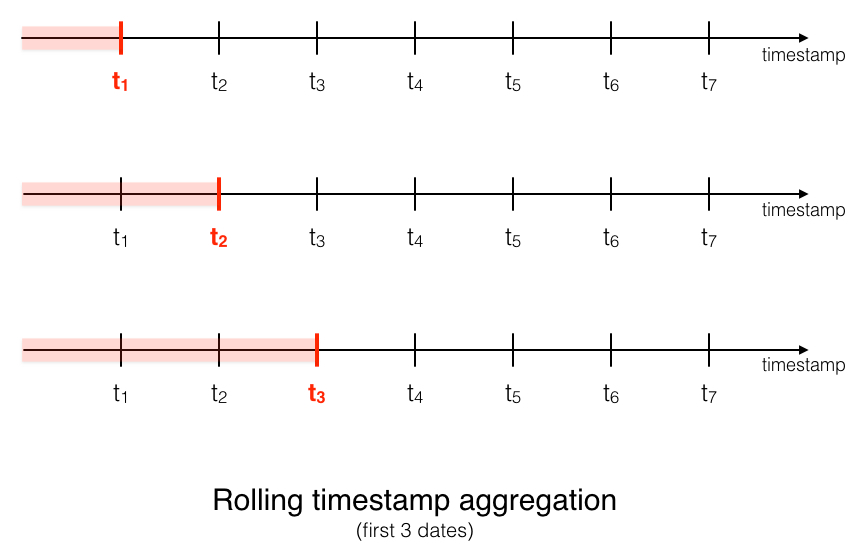
Moving Forward With Feature Engineering
Feature engineering is one of the most important tasks in data science and machine learning. In real life, it usually serves two purposes: improving the performance of predictive models and creating expressive indicators that allow data scientists/analysts to have a deeper understanding of the problem at hand.
Most approaches for automatic feature engineering tend to focus only on the former point. Features are usually generated in a brute-force or non-interpretable manner (as in deep learning). However, in a lot of real-life use cases, stakeholders want more than that; they want actionable insights and they want features/KPI/indicators that can help them know what actions they should take next.
We believe that our approach can answer both of the questions above. Automatic feature engineering is not just about optimizing a model for that last 0.1% metrics boost, but more about being able to tell a better story with better features.
