




Automation is a fantastic and scary word. We hear about it in the press with robots doing jobs in manufacturing that people used to do. Robotic process automation (RPA) software captures and automates repetitive business tasks. In many cases, machines and software are better suited to these repetitive jobs — they don't get bored, they deliver consistent quality, and they don't leave or demand a transfer to a better paying, more exciting job.
Automated machine learning, aka AutoML, is the most notable automation buzzword for predictive analytics and data science. AutoML promises to create production-ready models for a variety of use cases. Less well-known are the automation of DataOps and MLOps. DataOps can automate data pipelines to deliver production data for analytics, model scoring, and AI applications. MLOps can automate monitoring for production models for service levels, data drift, and model accuracy and then alert data scientists and operators or take action like retraining the model.
To Automate or Not Automate?
One perspective is that automation should be pervasive in data science, DataOps, and MLOps — so much so that people are only there for edge cases in design and production. Imagine if automated machine learning created all models, tested and deployed models to production, and made decisions about retraining, model replacement, and more. AI projects would become increasingly autonomous and optimize their outputs based on their objectives, taking on a life of their own.
This intense level of automation may seem like a universal remedy to executives but, to data teams, this looks like the end of the road. It is even worse for finance executives and risk managers; the lack of visibility and control into these increasingly automated programs would create an unknown risk that could blow up at any time.
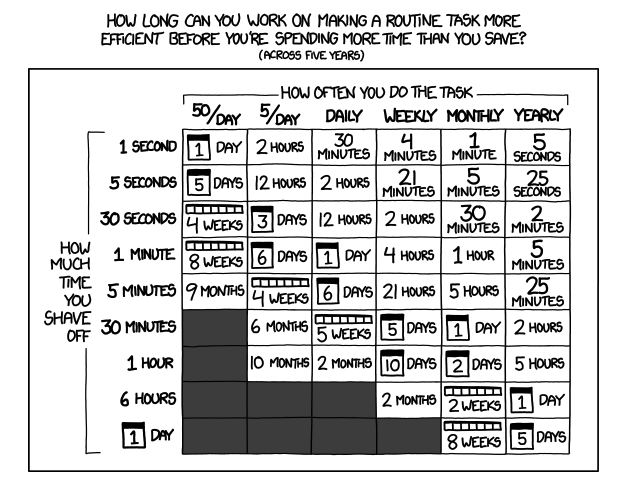
Establishing any type of automation comes at an opportunity cost — this means that you have to invest some time upfront to gain benefits. The cartoon below outlines how much sunk time you can spend on automating a recurring task — it depends on how often the task you are automating recurs and how much time you can shave off.
{kind=link}
A more realistic perspective is that, to scale, we need people and automation. We need humans and machines each doing their best work with humans in the loop to allow people to work faster, make sure our machine learning (ML) and AI align with our human values, do what we expect, and we can continue to trust their outputs. Additionally, even with the best AutoML, we will also need people that set up the workspace for the AI to perform. To reap the full benefits of AI, organizations will need a framework and playground to work on — including but not limited to data sources that need to be connected, storage/computation that need to be provisioned, and ideas where AutoML should look (i.e., what business challenge it should address).
As it turns out, we need people to scale AI. The reality is that ML and even deep learning are relatively new fields. AutoML is even more recent and is better suited to some use cases and not others. If we can use AutoML where appropriate and with oversight, that can free up data science teams to take on more mission-critical, challenging, and creative problems, which is precisely the kind of stuff they like to do.
Automation is also an accelerator for people, not a replacement. Automation helps a person complete a series of tasks more efficiently, taking away mundane work. In data science, using prepackaged modules and frameworks and even automating steps like feature engineering can have a substantial impact.
At Dataiku, we've seen this ability to leverage automation to perform tasks faster across a wide range of our customers. One data scientist at a multinational telecommunications company said, "Dataiku allows me to work 10x faster. Before, I was doing multiple steps in each line of code and it was previously taking an hour, but now it takes 1 minute to 5 minutes."
Avoiding Pitfalls
Machines and software do not have human values or ethics on their own. We, as humans, give them goals and guardrails. So, what happens when you let a machine program itself, as in ML? The machine algorithm will learn from the data you provide and build a model of the patterns that it discerns. The errors or biases in the data will become biased predictions. It is still up to people to understand this potential bias and determine how much bias is acceptable while maintaining our moral principles, corporate policies, and legal and regulatory compliance. Ensuring that our AI is responsible remains very much a human problem.
Predictive models are the product of a mathematical algorithmic approach and data. AutoML is good at picking the suitable algorithm for a given data shape or even using brute force to try many different techniques to find the best variables and approach. To determine if this output is valid and to make it useful is still very much a human endeavor. When we put models into production, the data used for production scoring can differ from the data used to train the model.
This "data drift" can cause the model to be less accurate in making predictions. Who should determine when a model has drifted enough? Again, we need a person to set the monitoring conditions to alert stakeholders and even retrain on newer data. Even if we can automatically test the new model, we still want someone to sign off that the new model still meets our expectations. Automagically judging whether a suggested model is even appropriate is equally challenging, especially for cases where potentially biased training data may lead to structurally unsound conclusions — an expert may determine with his domain knowledge that this makes sense, but your algorithm may not have access to such insights.

Critical to the adoption and scale of AI and machine learning is trust. People who don't know how these new technologies work, and even those who do, can and should be skeptical about the predictions they produce. As AI scales, more people across organizations will use predictive models to make decisions and streamline processes. Even customers will interact with models through chatbots, website recommendations, optimized offers, and more.
Having people in the loop who can attest to and sign off on AI projects and models is critical for trust. People can trust other people, but it will take time to develop confidence in machines and automation. Based on the pitfalls mentioned earlier in the article, there is a critical emphasis on quality control and continuous monitoring of the end-to-end machine learning lifecycle.
So, do we still need humans in the loop of AI? Yes, we do! We need people to do the hard stuff that machines can't. We need people to set goals and guardrails. We need people to provide oversight. We need people to help us understand models and to help our organizations develop trust.