




Data mesh is seemingly the new shining star on the landscape of data strategies — everybody is talking about it, and a few have taken tangible steps in this direction. Now it is time for us to share our customers’ experiences around data mesh in the enterprise context, along with what we have learned in practice. So, if you are interested in how to scale your data and analytics beyond a center of excellence, this might be of interest to you. Organizations do not store and generate data for fun — there is a purpose.
Why Data Mesh?
Systems like enterprise resource planning or document management systems favor centralization as part of the operational model because, both from a cost and “trust” perspective, you really want to make sure that it is the “single source of truth” - which in reality rarely worked, or required tremendous overhead.
You end up with central teams that guard the data warehouses and business critical systems. These central teams also analyze data so that you can “bundle” knowledge and expertise. And, inevitably, the understanding of the data and the business challenge that is to be addressed gets further away from the source and use of the data. Also, the data landscape is constantly changing: More and more systems are to be integrated due to upgrades, M&A, or shadow IT (based on a locally best choice).
So let's step back and ask what organizations are actually trying to achieve with a data strategy. Likely, they want to create value from data in a timely, efficient, trustworthy, and compliant manner. Here is where we see large, multinational companies hit a glass ceiling in terms of scalability and transformation. The usual approach does not scale to the extent needed by the business, and excessive centralization is part of the problem. A quote from one of our customers brings it to the point: “A central team won’t scale, and the citizen data scientists out there in five different business units work all with their own processes and tools. That’s neither governance nor cost efficient.”
Enter data mesh, a concept coined by Zhamak Deghani of Thoughtworks, which offers a radically different approach to these eternal problems. Conceptually, data mesh is a mix of technology choices and a data operating model. That means it is not a product you can buy off the shelf. It encourages domain ownership with decentralized creation of data products via self-serve data infrastructure within a federated (computational) governance.
When you read that, it becomes clear that data mesh is more than an architecture pattern. So what then, exactly, is data mesh? Is it an evolution of the “data analytics operating model”?
Finding the Right Mix of Architecture Choices and Operating Model
The operating model is how data architecture comes to life in practice and, when corporations go through the learning curve in terms of data analytics towards high data maturity, they adjust the operational model on the way. The tech stack and the architecture adapt as well. Nothing is as constant as change. Like a pendulum, it often swings back and forth between the extremes of “centralization” and “decentralization.”
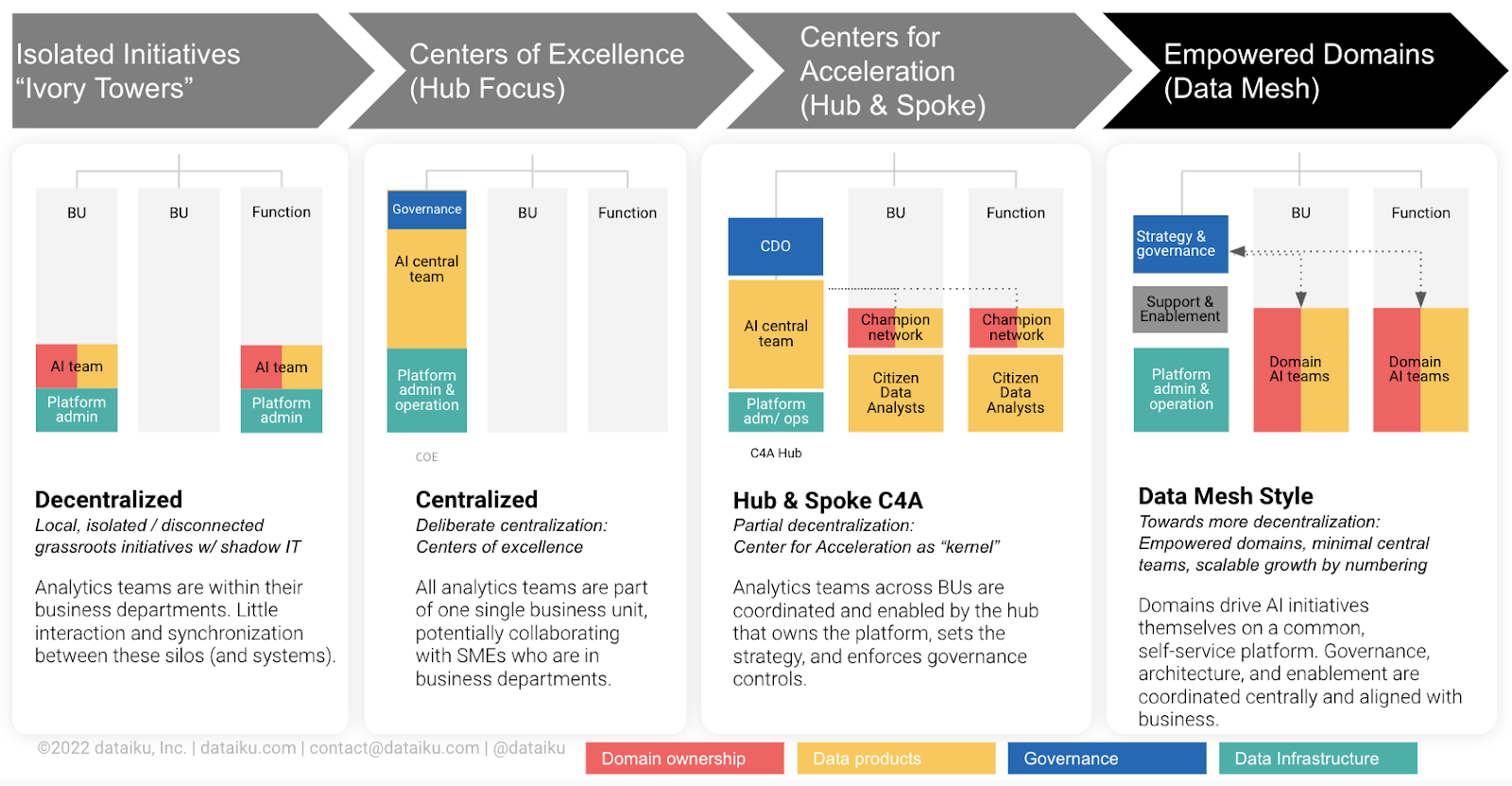
Based on our observations, the journey usually starts with spread out, isolated “ivory towers” of data analytics in some parts of the company (e.g., a certain business unit or company function).
Next, resources are often pooled into a center of excellence for analytics (or data science) which leads to a “critical mass” of users with higher maturity, which seemingly speeds up the progress. Naturally, that means that the analytics move “away” from the use case. So, we see (and encourage) and embrace the idea of democratizing data analytics and providing it directly in the business.
This so-called hub and spoke setup features a set of experts in the core but builds on citizen data scientists in all parts of the business. At a certain point, your “local” teams in the spokes are ready to take over the full responsibility — and they can truly own the creation, lifecycle management, and operations of the data products.
This means that the central functions in the hub mainly go back to a “supporting” role, providing the capabilities to enable the businesses to work. So, from my point of view, data mesh is the next logical step.
{kind=link}
However, the high-level operational model is only one part of the story. It tells us a bit on where the work with that data should happen, but it is not about how that work is structured and how value is generated. Rarely, we talk about the user experience of a “model” or a “dashboard”...
It Is Time to Talk About Data Products!
Switching the mindset to delivering “data products” is a fundamental shift from “project” thinking. But first, what is a “data product”? From my perspective, I would see any artifact that takes data and transforms it as a “data product.” This means the result of an ETL pipeline is a data product, so is a consumable dashboard, a report, a deployed deep learning model, or an output that is valuable to another data product. What all these have in common is that they rely on (ever-changing) input data and some kind of recipe (or code) that defines the output.
Focusing on the use, adoption, and value of the data product also means that you need to think of lifecycle management, operations, and quality control right away. It is about creating a positive user experience and putting the user (your internal customer) in the center of your thinking.
Treating all data products consistently with a MLOps / DataOps business process is the logical consequence — and builds on the learnings from the CoE times. Aligning on what the use of a data product should provide is most easily done when having a clear understanding of the purpose and how it fits into the business. This of course is easier when the data product is created as part of the business. As we said, a data product is not a project that is “done” — as per experience we need updates, changes, and adaptations. These of course are easier when you do not have to file a change request with a ticket system of an overloaded CoE halfway across the planet! So, ownership of the data products by the domains is an approach to mitigate that. It is indeed one of the guiding principles of Dataiku. We truly believe in the democratization of data analytics!
Ownership comes also with responsibility: Suddenly you are responsible for the quality and availability of the data product! The good news is that operations of data products is typically a team sport — but it is wise to decide (maybe even by means of a RACI matrix) who has which role. What we have learned from a good amount of customers is that giving ownership also means that you give the power to decide back to the teams — and, here, more than one hierarchical enterprise had their fair share of learning to do.
Another learning we can share from one of our customers is that cornerstones like strategy, infrastructure, and business processes (governance) should be decided centrally — but this won’t work if you also centrally (or even worse, in a series of staggered committees), decide on every data product, etc. The customer shared that they also changed their decision making processes from “staggered committees” to empowering the domains to really “own” their data products.
Providing Infrastructure - With Aligned Governance
In the previous section, we learned how to think about data and analytics as products, but now we'll share how to actually create them easily, from a user perspective you need to:
- Find and get access to the data you need (data catalogs and data access)
- Understand the context of the data you are using (metadata management)
- Be able to create your data product (on a platform like Dataiku)
- Have computational resources to perform the transformation, modeling, etc. within your data product (on your hyperscale / cloud provider of choice, or on premise)
- Publish and operate the data product (MLOps with Dataiku)
All of that respecting compliance rules and fitting into governance frameworks. This also shows you that data and AI platforms like Dataiku are just a part of making a data mesh a reality. Such platforms act as the place where data products are created and managed, so they are the orchestrator of the whole technology stack. This is also the part where a solid integration with our partners within the ecosystem plays a huge role - here you can truly benefit from things working together well.
Now imagine hundreds of data sources with esoteric interfaces to connect to. One part of the data mesh is to simplify this — but how? From a user perspective, this data integration complexity should be easy, hidden, and focused on the capability of finding data and its metadata in a (virtual) catalog. Even if the data infrastructure runs locally, you need some kind of “index” on which data (product) is where and how to connect to it/them.
Similarly, the computational resources may be run / provided by the domains and, from a user perspective, it again should not matter whether this is on premise, in one public or private cloud, or across many. From an operational excellence (and cost) perspective, we see more and more organizations opting for architecture patterns that favor a hybrid approach — and hide the underlying infrastructure choices from the user.
As we learned from numerous customers: The creation of data products work best when the platform abstracts away the complexities of the underlying infrastructure and allows frictionless work with data (at scale). For the user, it should not matter what happens underneath.
Deciding on the standards that have to be followed in order to “productionalize” a data product is something that is often done centrally within a corporate function — similar to what happens with most other corporate governance choices.
One customer told us: “We do not just have ONE data strategy — we have at least five.” Just saying that you now do data mesh won’t fix that misalignment and, consequently, that customer opted for one aligned data strategy and one overarching governance framework, and decided on an architecture pattern as outlined above.
That way, the “engineering and operations” of the self-serve data infrastructure is located centrally, whereas the entire responsibility of building the data products is decentralized (and democratized) — which is exactly in line with the design principle we put into Dataiku. This part makes it also simple and transparent from a cost perspective, as now businesses can pay for the use of the infrastructure that is provided.
Learnings From the Machine Room
Thinking in terms of data products that are domain owned means shifting to a clear focus on the value of what you do with data — and is something that truly makes sense as the north star for your data strategy. Thinking of data as a product is very much what we believe in, and a self-service platform like Dataiku provides everything you need to make that a success. We remove the complexity of the underlying infrastructure and make it easy to build, ship, and manage many data products.
This builds on enterprise-grade self-serve data infrastructure with the capability of establishing clear governance and business processes. Domain ownership, empowered teams, and independent work is something we embrace and that means thinking beyond just a CoE that does your data analytics, but rather owning and shipping your own data products.
Since 2013, we’ve been building Dataiku towards something very much compatible with the core ideas of data mesh: empowering teams, democratizing access to data analytics and AI, and enabling agility, control, and trust. Building on those, we can help you achieve your data mesh ambition in the long run — so why not get started thinking about it today.