




A Single Project to a Tissue of Services
In this article, we continue our exploration of how expert Dataiku users and administrators can lift Dataiku created APIs into a data mesh, seeking to expose data and inference engines created during the experimental phase as a tissue of governed microservices.
In my last article, I reviewed how to produce a service that does machine learning (ML) model scoring and then documented that single service and protected access to it with MuleSoft’s API management on the Dataiku API Node. That’s all well and good, but to actually use that service as exported, there’s some assumptions implied. One must be able to access the set of features required for the model to score the incoming request; often this implies a lookup of data from an arbitrary point in the data flow used to prepare this data.
Dataiku provides many interesting capabilities around exposing these datasets as data products to a mesh as APIs. Data access as a service implies a need to manage access to a tissue of APIs, as well as the ability to scale those horizontally to address elastic demand, which makes us look to Kubernetes (K8s). K8s will provide us with a modern microservices deployment architecture to access this data AND demand a zero-trust communication fabric between services. We’ll look at using a service mesh around these services to both discover them and control access to them allowing for integration with other data products in the mesh.
So You Want to Predict Something...
In our last exercise, we lifted a predictor about a given customer’s propensity to spend a high amount of money with our firm. The service itself was pretty complex, with 11 fields required to meaningfully predict that outcome, with many of the features being demographics. The truth is: In a real-time scoring use case, incoming payloads tend to be simple, lightweight, and require a fair amount of enrichment in order to produce valuable results. This use case is no exception, but we have some options that don’t just require all 20 fields.
Auto-Lookup
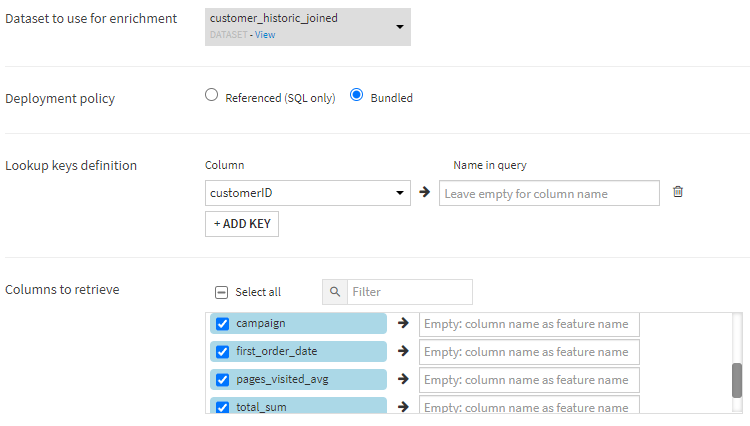
Dataiku provides the ability to allow any generated service endpoint to leverage any dataset in the project to automatically lookup any missing fields, which is great for simplifying the inputs to a service and promoting usability for the endpoint. When we created our service, we just took the defaults, but a facet of good API design is to simplify the complexity for the caller. By looking up customer details from earlier in the flow, we can ensure that our caller need only pass us a customer ID.
On the Enrichments tab of this scoring API endpoint, we can add automatic lookups which the service will use to provide any missing features. Here, I can set up my API to automatically look up the birthdate, gender, and campaign status from my customers without needing to provide it.
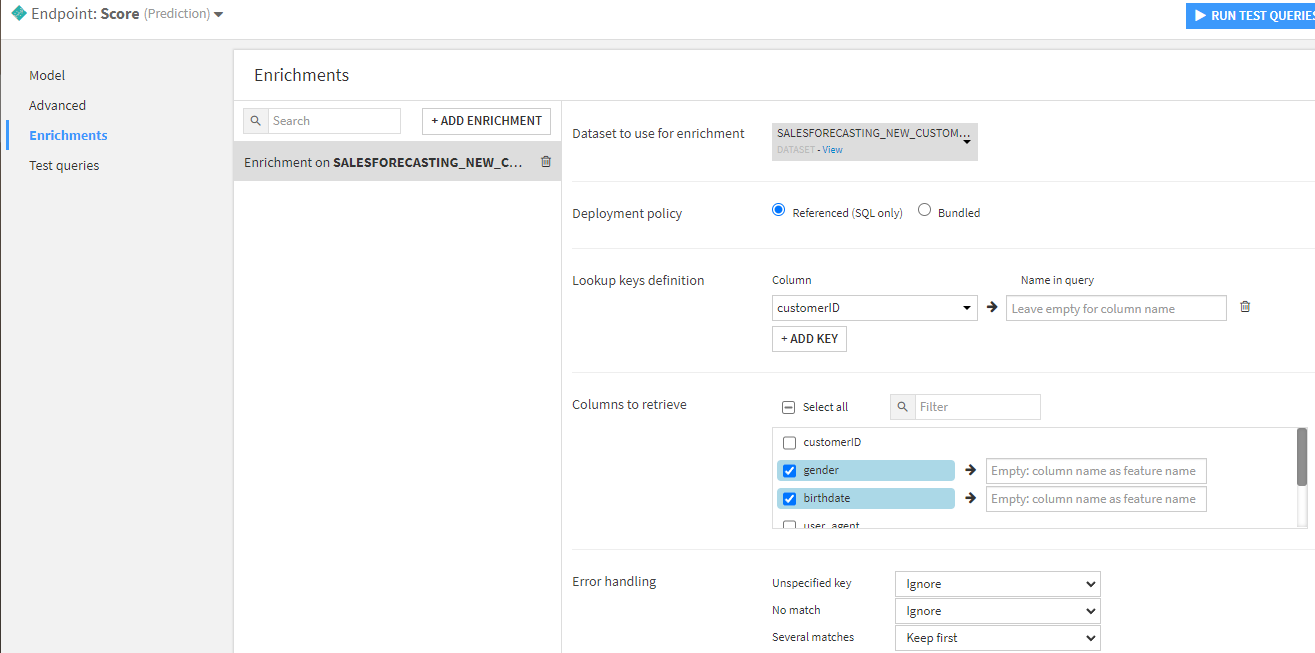
Because my datasets are starting in a SQL store, I can look up the gender, birthdate, and other campaign statuses straight from my original Snowflake database. When I remove those elements from the test queries, I get the same answer and probabilities from my test service:
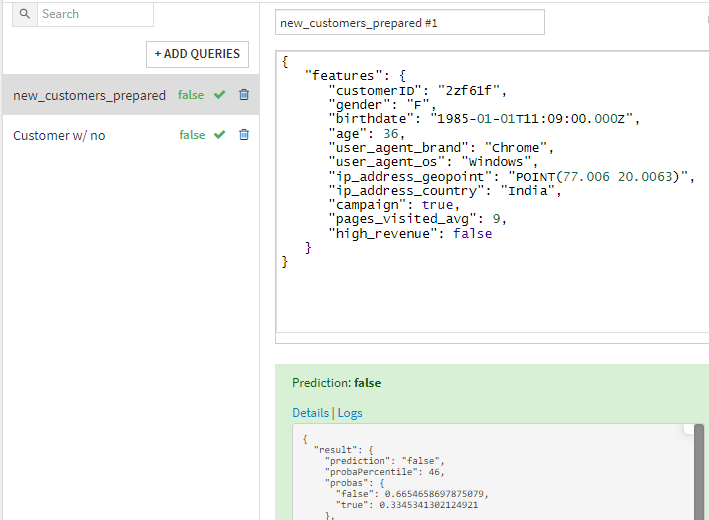
Versus:
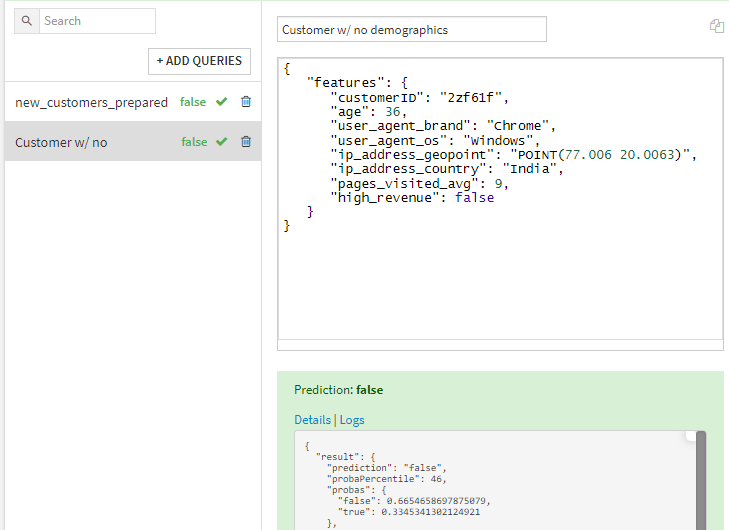
And this is all well and good and is certainly easier for the end user of my inference engine, which is a principle of good API design, but this lookup isn’t reusable by anyone else for any other purpose. Additionally, as the data I’m preparing here might include useful customer demographics details or possibly summations of my organization’s current understanding of the customer behavior, hiding this in an implied lookup is less useful than it could be.
Explicit Lookup
A better, more reusable approach to this might be to add an endpoint which explicitly looks up this data from my flow and provides it as usable to any caller: This adds extra steps on the behalf of the caller, but provides explicit reusability in the form of additional endpoints or services for performing these data lookups.
Starting from my original service, I will instead add another endpoint to this service.
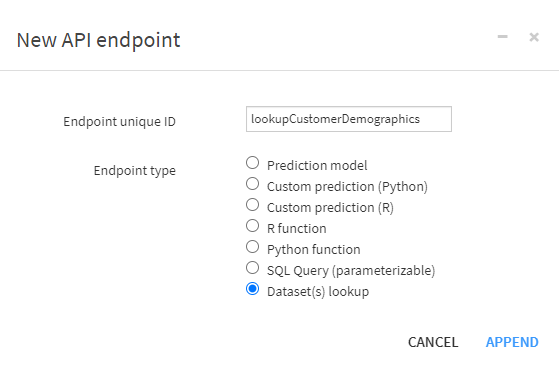
I’ll also add an arbitrary dataset lookup to my service:
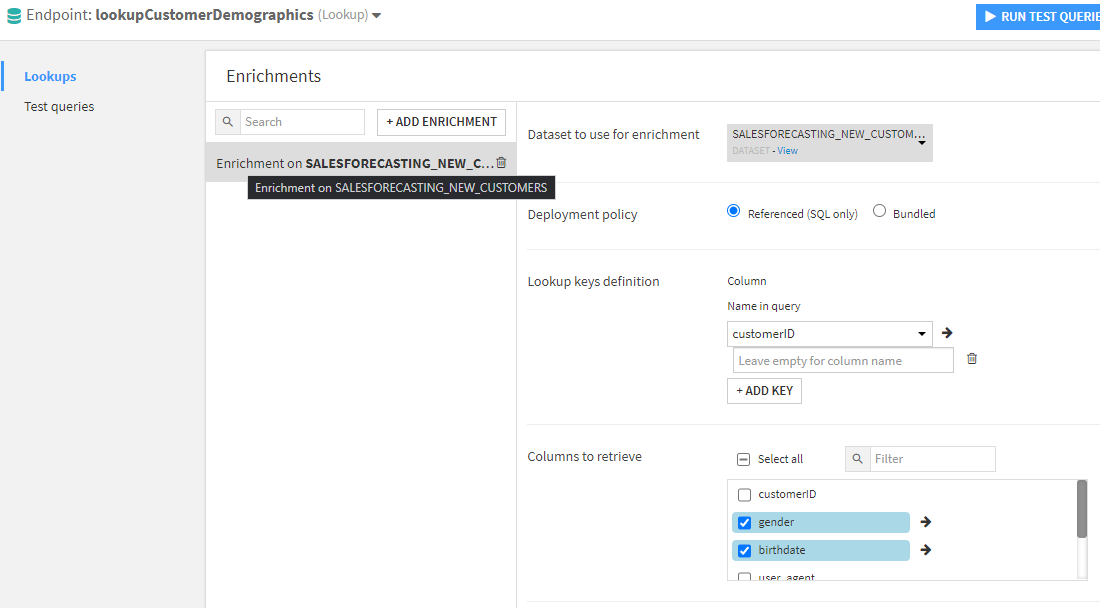
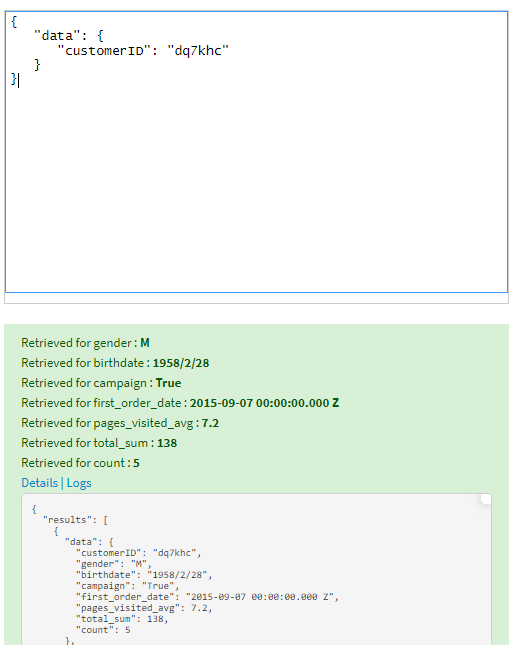
And now I can perform the same types of enrichments I could embed into my service as explicit data extraction endpoints:
Now, however, the shape of the test queries and the responses are slightly different:
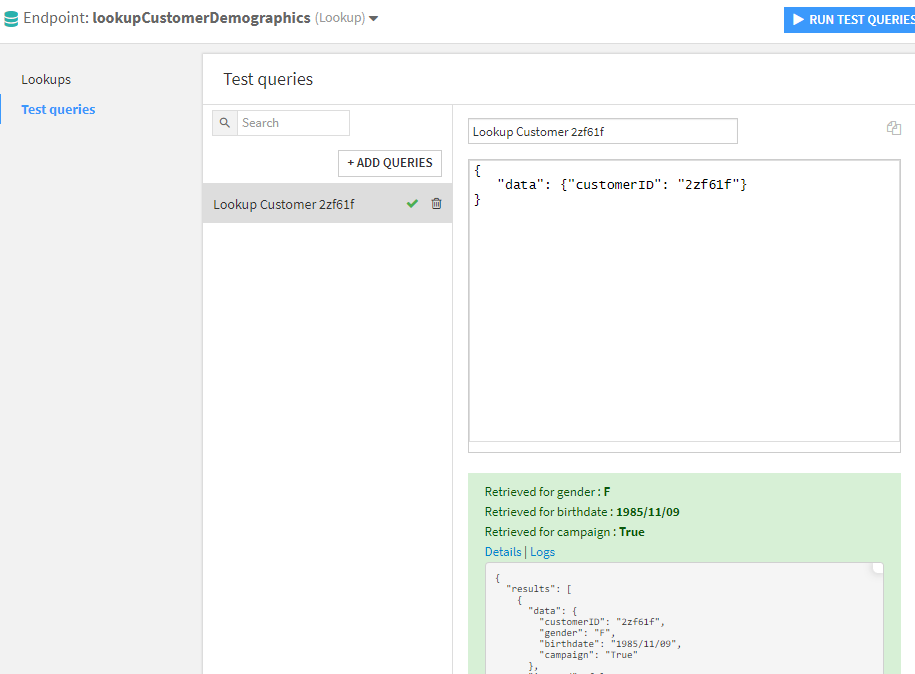
With a single click, I’ve created an API endpoint which accesses the data in my flow! This example used the raw data, but I could target any dataset in my flow, taking advantage of all of the preparation and cleaning available, which might be useful to any other user who wants the daily summation of a given customer’s buying habits!
With a couple of clicks, we’ve created some real reusability for the data preparation and feature development we did when we were developing our ML predictor!
Deployment Considerations
So, while this is great for development, there’s a number of concerns this doesn’t tackle: First, adding these lookup endpoints to the inference engine will place undue load on that service if they are used outside this use case, so we probably want to scale them (and probably version them) independently. Second, we want to actually be able to allow these services to scale automatically if we’re going to put them into business critical real-time workflows, and the API Node we set up in our first exercise is not something that scales elastically, so we will want to look at K8s to provide the execution backend for these services. Let’s start with a separation of concerns by moving those lookup endpoints out of the inference engine service. From my project, I'll go to the API Designer:
I’ll add a new service “CustomerFeatures” with my two lookup endpoints to do a simple lookup for customer demographics and another for the more complete customer behavior summary:
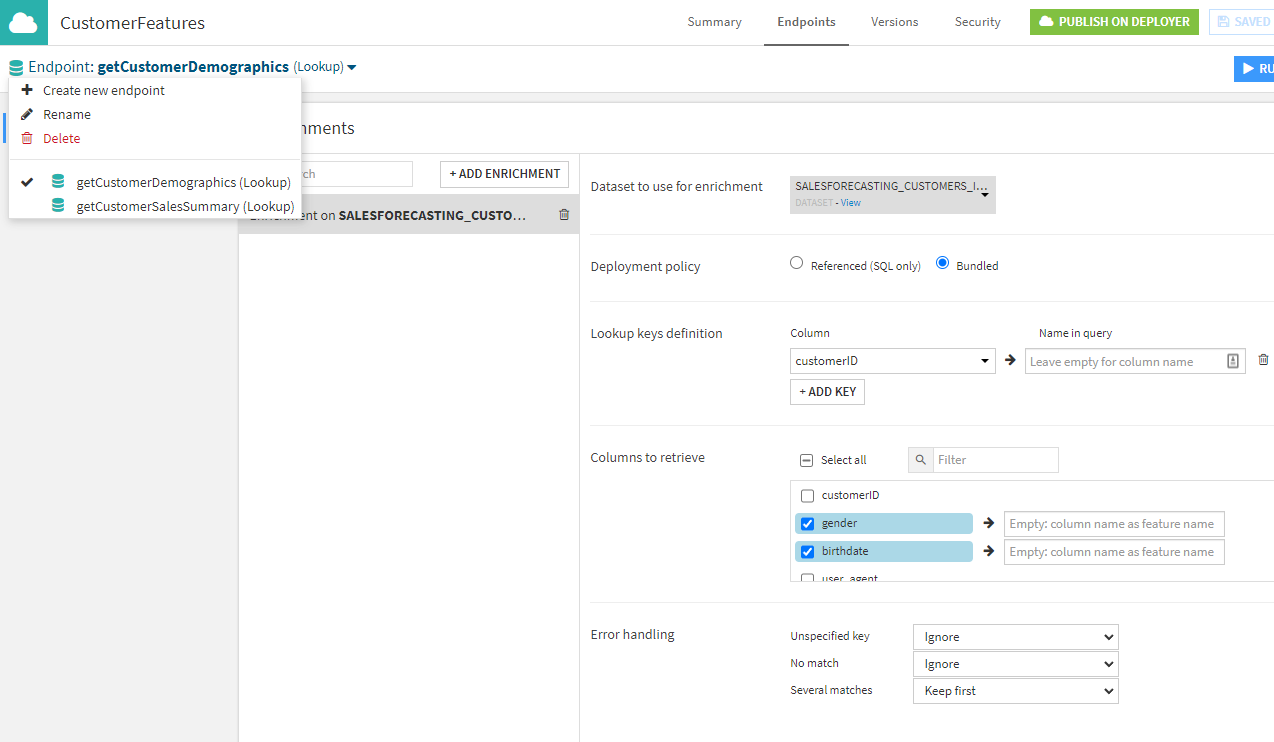
In this case, I’ll bundle the data: It’s small enough that I can deploy these microservices as truly independent feature stores services, with their data locally so as to not imply a dependency on the Snowflake database. Make sure to publish to my Deployer!
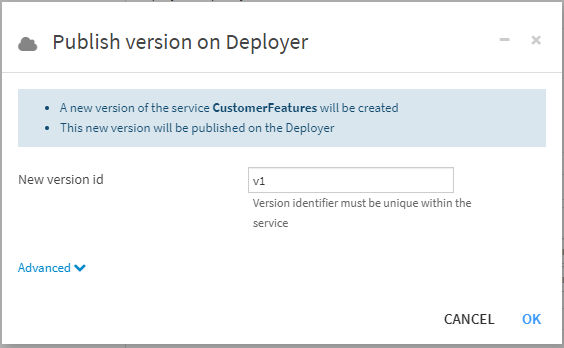
And now I can turn to my execution infrastructure. First, I’ll use the Dataiku AWS EKS Plugin (Dataiku ships analogous plugins for AKS and GKE on Azure and GCP, respectively) to generate an EKS cluster configuration and cluster for me with a couple of public facing subnets so I can access my services from my desktop.
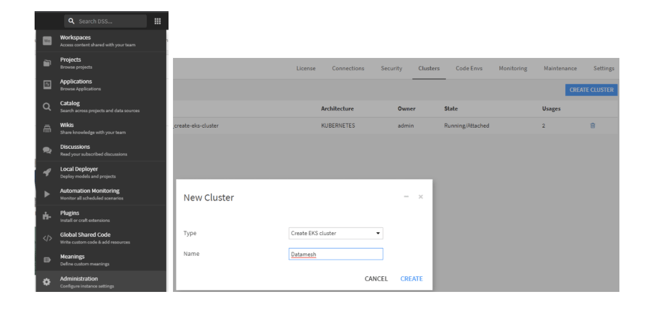
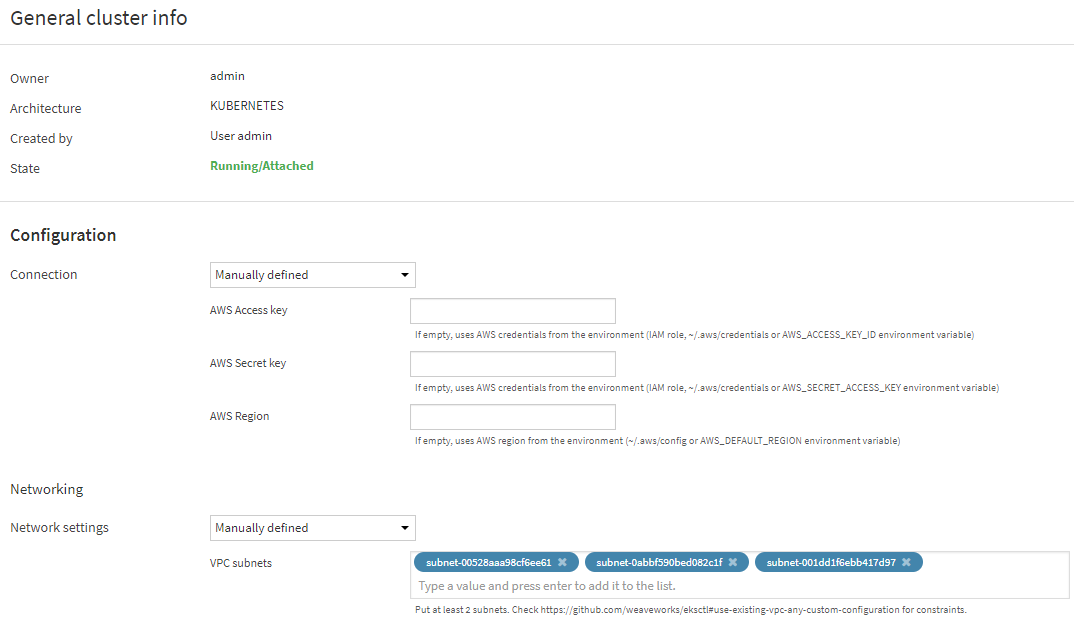
And then I set that as the default cluster for my containerized execution:

Now I need to use that as a target for my API services, but while I’m here I’ll grab the ECR URL from the configuration of my cluster:

Switching to my deployer and selecting “API Services” and then “Infrastructures,” I’ll define an infrastructure:
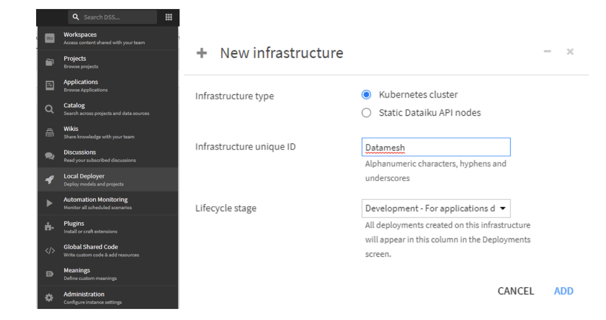
And now here, I have some configuration to do to set how I want the deployer to manage images, connections, and service exposition with the EKS cluster. First, I’ll drop the ECR Registry from the main settings here, and configure it to enable the push to ECR:
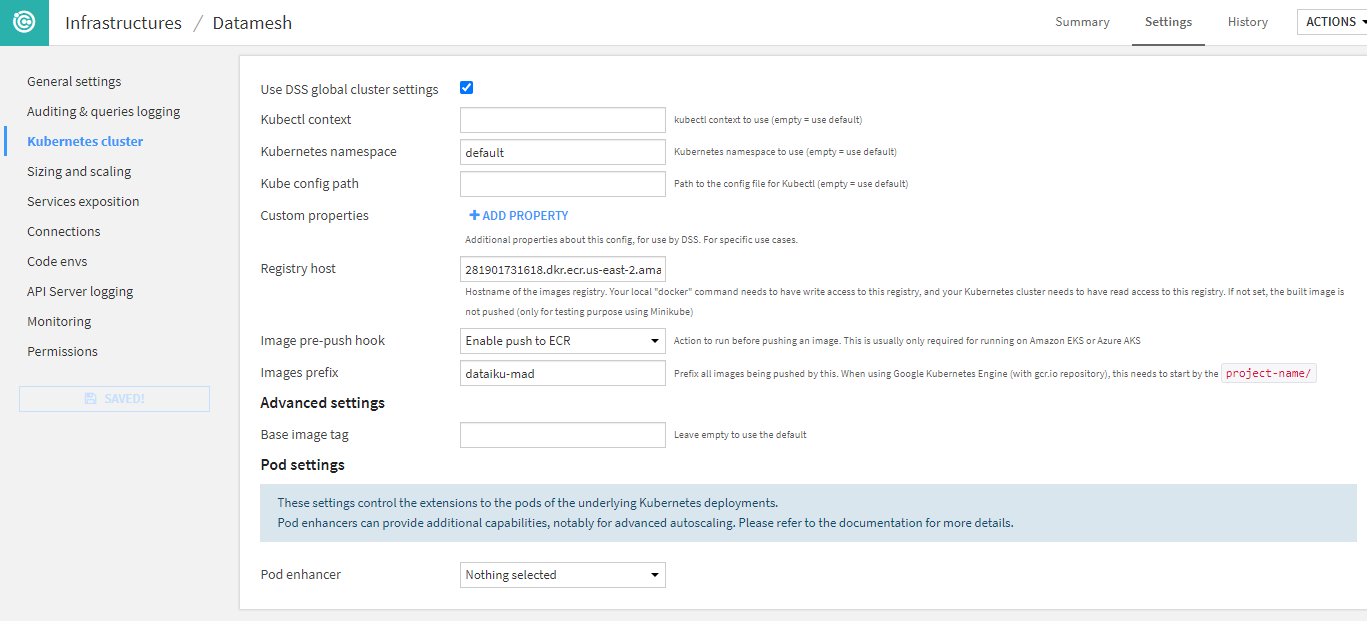
Next, I’ll set up my database connections. Since I’m deploying services that either collect their data and keep it in memory or get it fresh, I want to be able to configure that differently for different environments. For the purposes of this blog, I’ll just select my connection (Snowflake for this project) and Dataiku drops its configuration into my clipboard! So it’s a snap to paste that into the bundled data connection and/or to create a connection which matches the name with the setting. Important Note, you need to drop the database connection password, and replace the encrypted version from your clipboard.
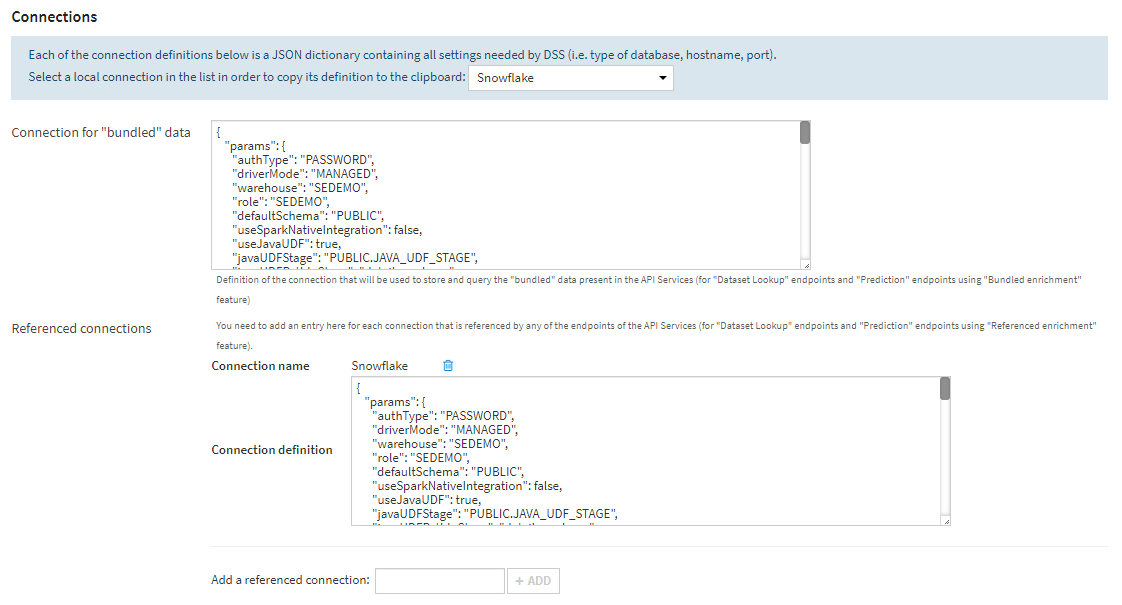
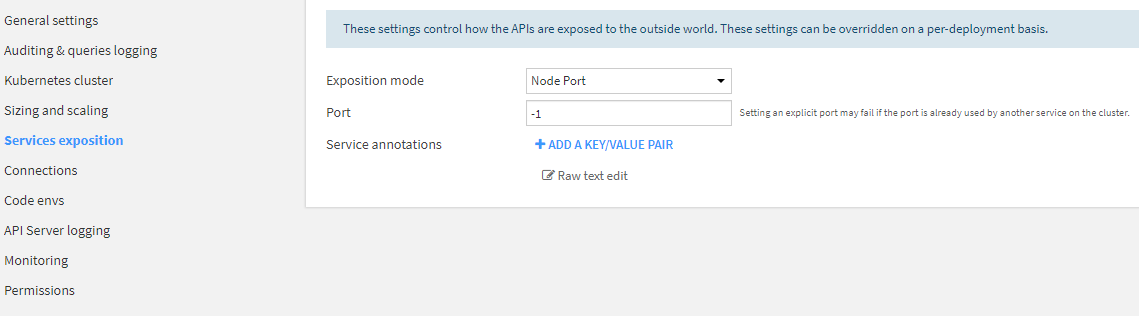
Now I need to configure how different services will be accessed from outside of the K8s cluster. For simplicity’s sake, we’ll start with a simple NodePort setup, which will open a port on each node the service gets deployed to, accessible only from inside the vpc. For our next article, we’ll take a more production-like approach to service exposition:
Finally, we can do a deployment of my services, both my lookup service and my inference engine:
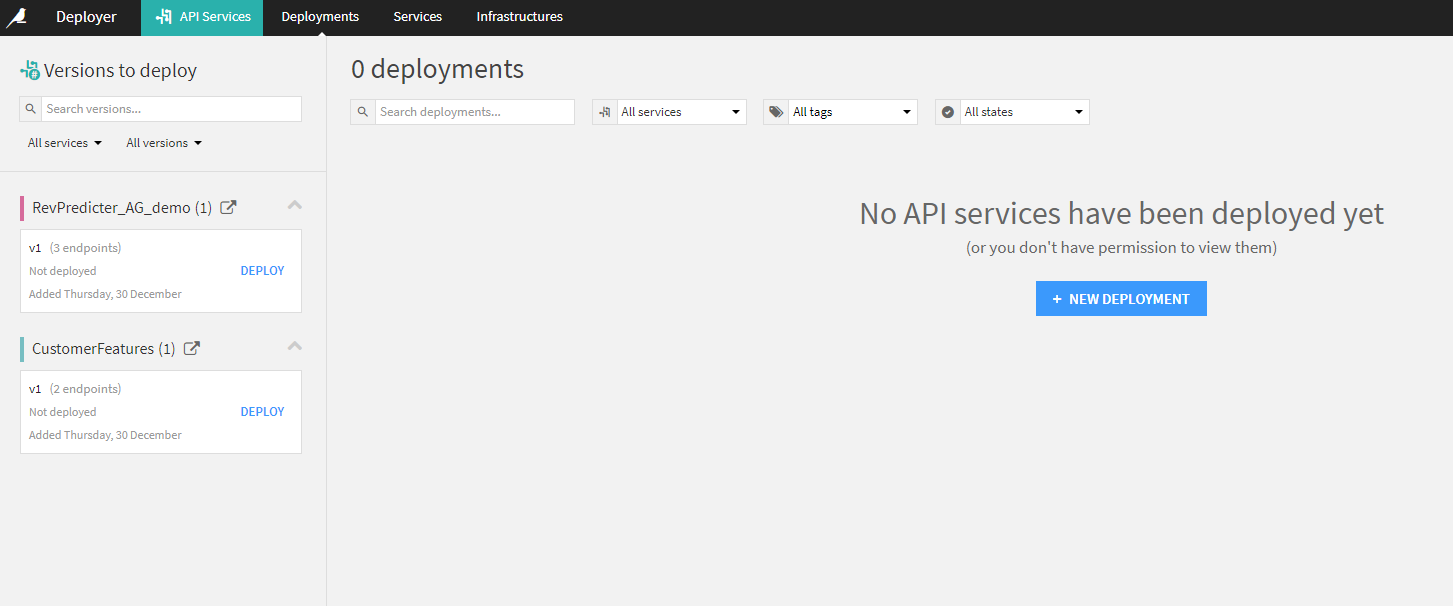
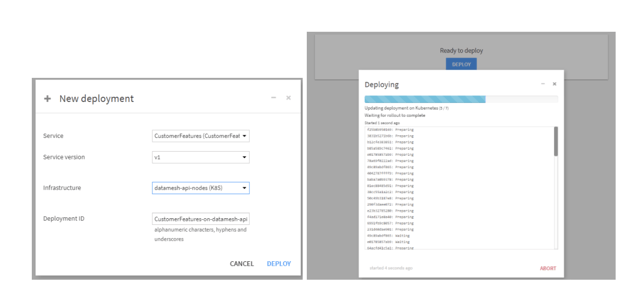
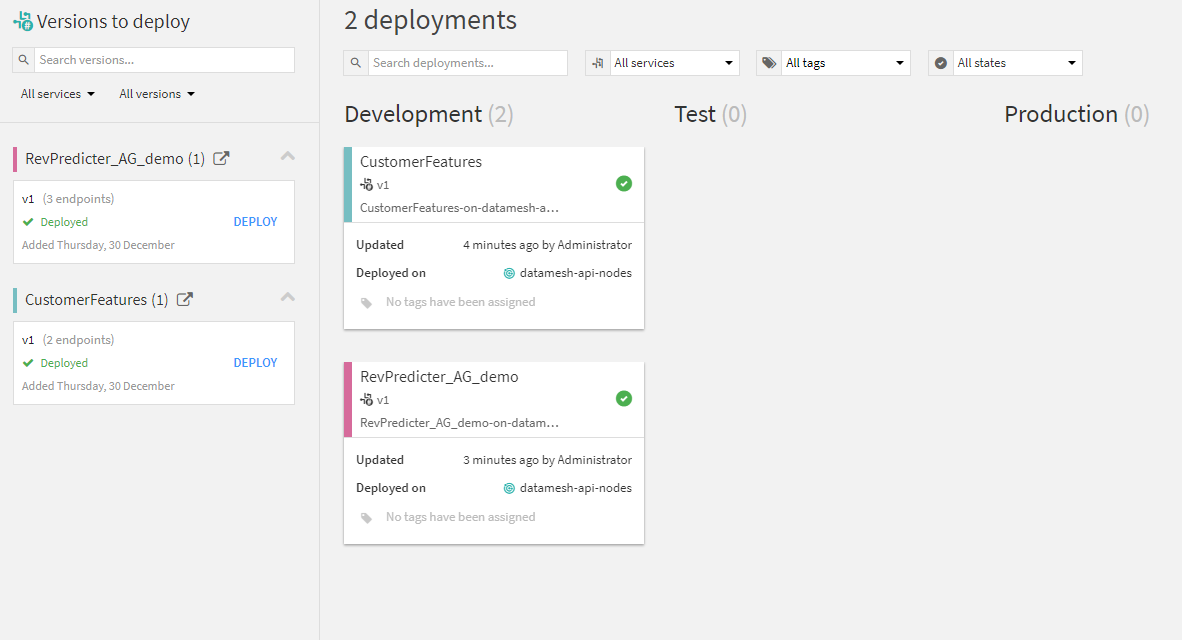
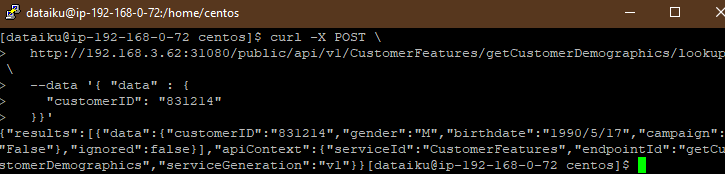
And now with my services deployed, I have the beginnings of a service mesh. I can even try the services in place:
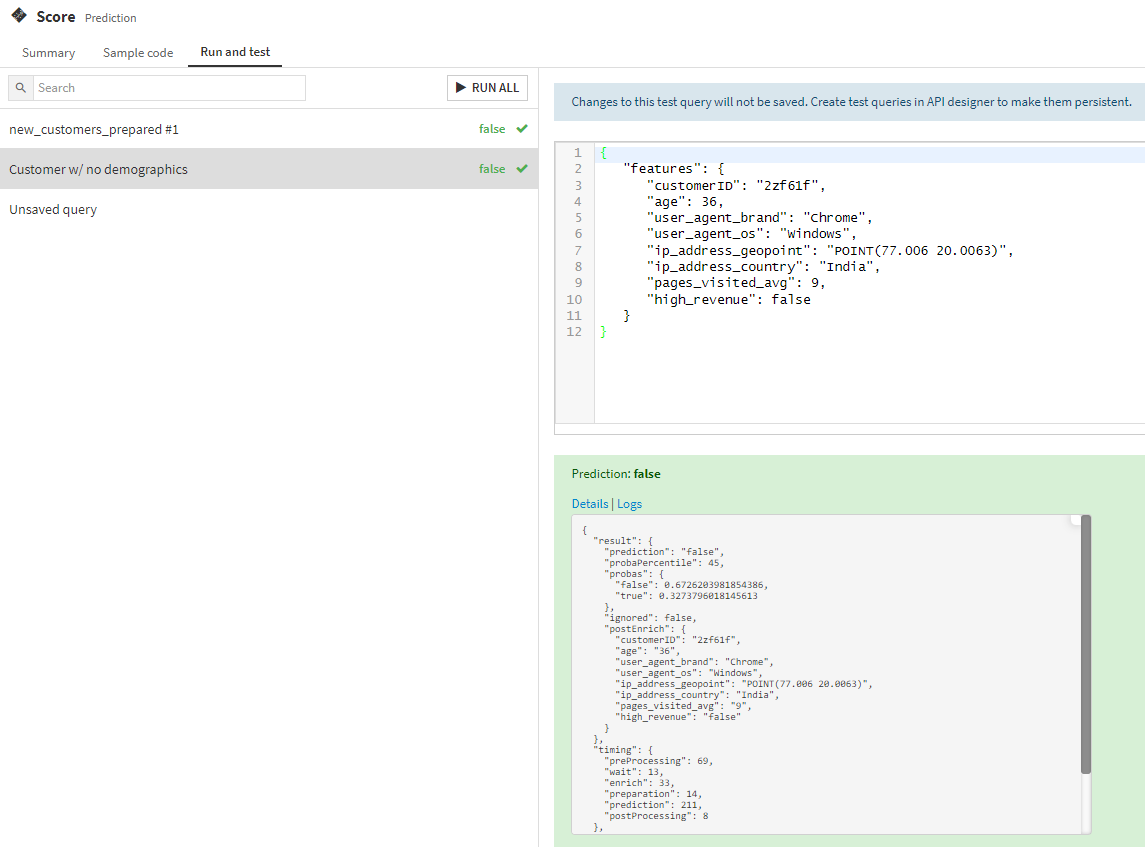
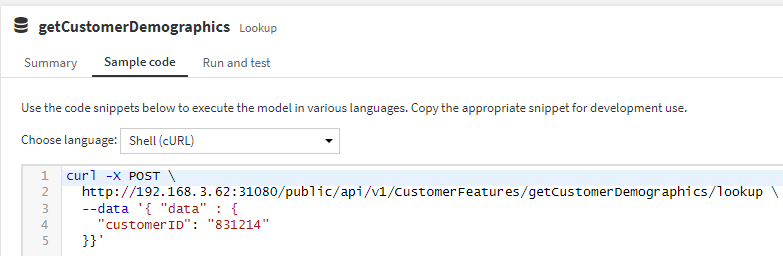
{kind=link}
Now, I’ve created — with clicks, not code — a deployment of both a live and automatically refreshing reusable feature store which can be used to access the data features created while I was preparing this data for my ML project, but also the inference engine itself. We’re well on our way to creating a reusable data mesh, but we need to better control how these services get exposed and to choreograph these services together into a coherent whole, all of which we’ll cover in our next post.