




{kind=link}
Data architecture is the foundation of every company’s data strategy. However, there are many data architecture issues that can make life difficult for both data scientists and business users: poor use of space, inconvenient pathways, security, and clutter.
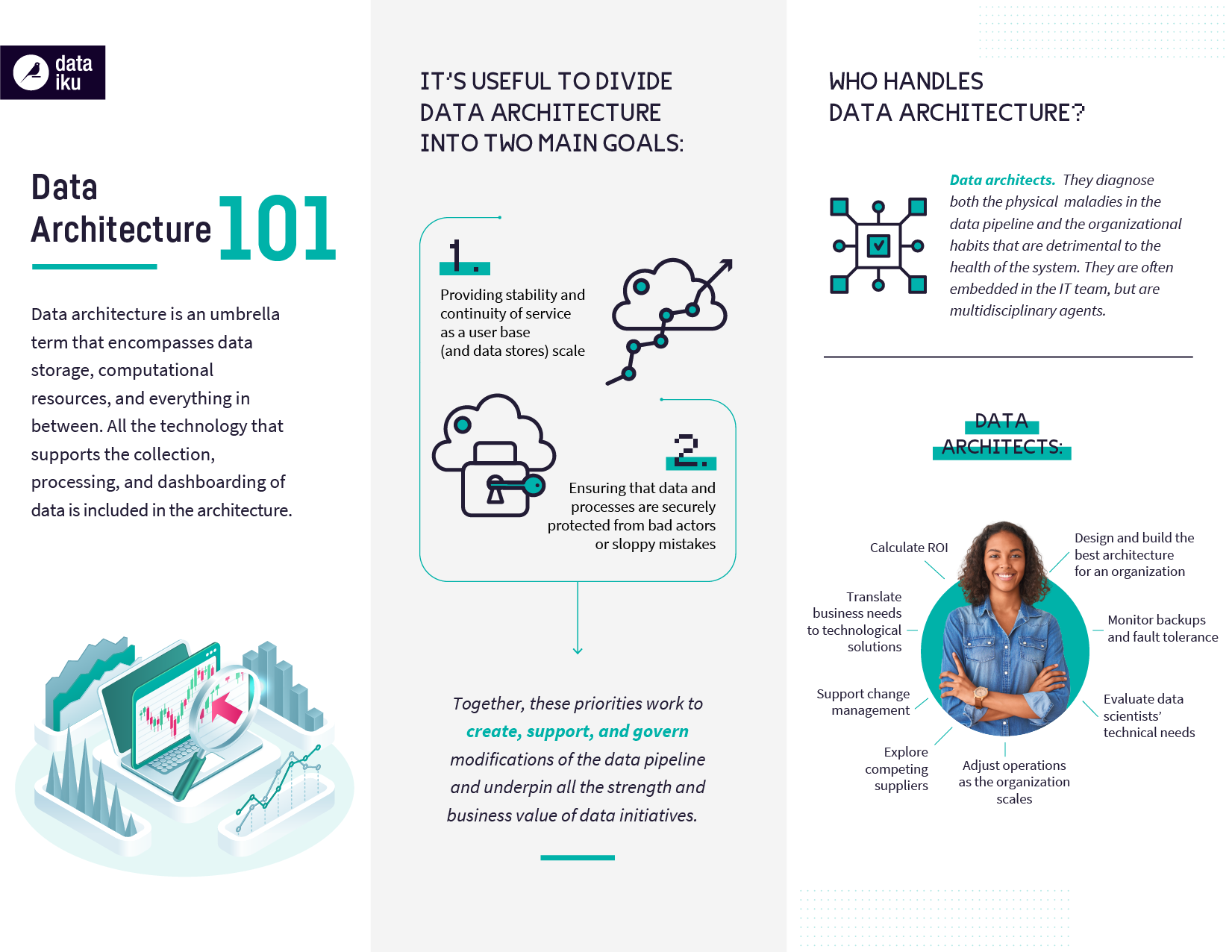
As an umbrella term, data architecture encompasses a lot: data storage, computational resources, and everything in between. All the technology that supports the collection, processing, and dashboarding of data is included in the architecture.

The “In Plain English” blog series is intended to make data science, machine learning, and AI topics accessible to non-technical experts. The infographic below does just that: It helps those teams understand the work data architects do and how data architecture can help — or hinder — the data strategy at an organization.
Then, discover some of the must-know data architecture terms, broken out by two of data architecture’s main goals. The first goal is providing stability and continuity of service as a user base (and data stores) scale. The second is ensuring that data and processes are securely protected from bad actors or sloppy mistakes.
These priorities work together to create, support, and govern changes of the data pipeline, and underpin all the strength and business value of data initiatives. Just like with actual architecture, a well-structured data architecture can make data science and analysis streamlined and efficient, while incompatible architecture makes every effort a Herculean task.
Data Architecture Key Terms: Scalability
1. Distributed systems segment the storage and compute resources of a system onto different machines that are able to run in parallel, thus speeding up work and minimizing the risk of single points of failure. The building blocks (storage and computation) of distributed systems are nodes and a cluster is a collection of multiple nodes.
Distributed systems are known for being both highly available (meaning the ability of a system to function continually without failure) as well as fault tolerant (the ability to maintain usage during the failure of a component).
2. Data partitioning is the act of splitting data into segments that are more easily maintained or accessed. For example, distributed systems partition data in order to improve scalability and optimize performance.
3. Data replication is the act of copying the same data multiple times to different systems. Synchronous replication happens when writing data to primary storage and a replica or backup simultaneously. Asynchronous replication means that data is copied to a replica or backup after it is already written to the primary storage location.
4. Hadoop is a popular cluster-based open-source framework for distributed storage. Different data processing engines or frameworks that can be used on top of Hadoop include (but are not limited to) Hadoop MapReduce and Apache Spark.
5. Storage resources are the data storage capabilities of an architecture and a main requirement for all data science operations. Along with compute resources, these are a good indicator of an architecture’s ability to scale.
6. Compute resources are the processing capabilities of a system that are available to perform computational work (e.g. execute programs, carry out analysis, etc.).
Data Architecture Key Terms: Security
1. AAA stands for authentication, authorization, and audit, which are the three pillars of data architecture security.
2. Authentication is the security process by which a user or process confirms its identity. This can occur in one location (as is the case with SSO) or through multi-factor authentication.
3. Authorization is the security process by which the system gives a user or process the ability to read and write data or execute programs within certain parts of a system. Depending on the user’s clearance level, this may represent a small section of data relevant to their processes or could include the ability to act as an admin and authorize other users.
4. Audit is the ability to trace and review everything that’s been done within the system.
5. Data lineage covers the entire path data takes from creation to storage to analysis. It also incorporates who “owns” what data at a given time, which is critical transparency for compliance regulations.
6. User permissions enable users to work with a certain set of data. They come in three stages: Read, where a user can consume the data stored in the system; Write, where a user can modify data; and Execute, where a user can execute commands and programs that can impact the database structure.
Data Architecture Recap
Data architecture isn’t just something for CIOs, IT leaders, or the enterprise data architect. While these people are often the ones responsible for diagnosing the issues in the data pipeline and the organizational habits that are detrimental to the overall health of the system, users on any team can benefit from understanding an overview of the ways their data insights are generated and how they align with business goals and priorities.