




As businesses increasingly turn to conversational AI to improve productivity and user experiences, building effective retrieval-augmented generation (RAG) pipelines has become essential for tapping into organizational knowledge. At Dataiku, we’ve been listening closely to our customers, and many of our latest product updates are designed to streamline RAG workflows to make them simpler, faster, and more flexible to develop and maintain.
In this blog, we’ll walk you through the latest enhancements to our prebuilt RAG components — tools that are already helping hundreds of our customers create production-ready Q&A applications in record time. From smarter text chunking to efficient knowledge bank updates to support for more vector stores, here’s everything you need to know about what’s new and what lies ahead for AI builders!
Prebuilt RAG Components That Deliver Results
Dataiku’s suite of prebuilt components — text extraction, embedding tools, integrations with popular vector stores, and a ready-to-go front-end chat interface — has made it remarkably easy to deploy RAG-powered applications.
Take Dataiku Answers, for example. Nearly 100 organizations have implemented this packaged feature to deliver conversational Q&A systems in just days, serving thousands of end users with seamless chat-based experiences. But early successes are just the beginning. As customers tackle more complex use cases, they’ve told us what they need next. Here’s how we’ve delivered.
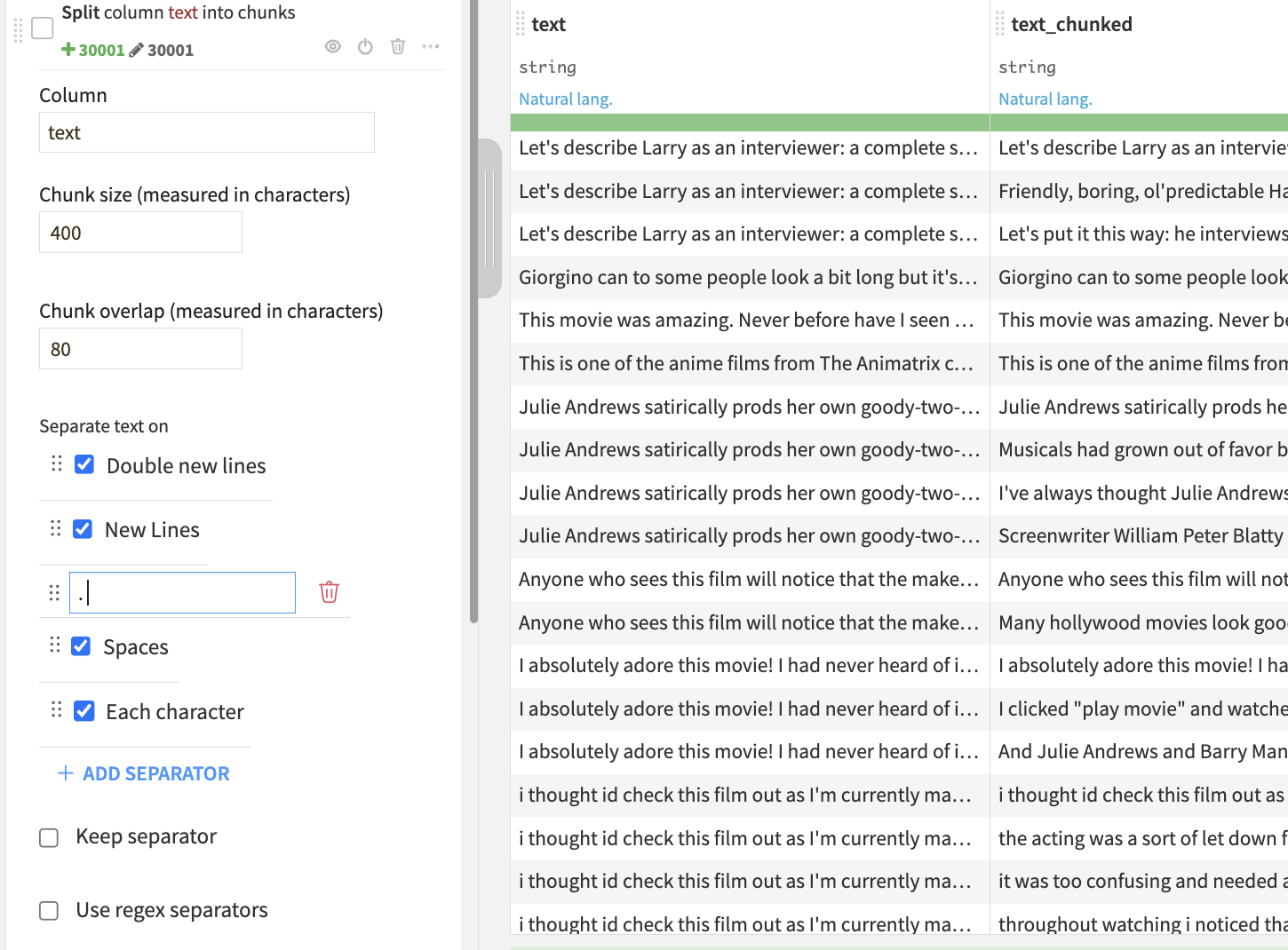
1. More Flexibility and Control Over Text Chunking
Text chunking is essential to the classical RAG approach. Effective chunking aims to break long texts into smaller, meaningful pieces that reduce unnecessary “noise” and are concise enough to fit within an LLM’s context window, while still being robust enough to preserve the precise and relevant information needed for accurate retrieval and responses. A good chunking strategy ensures that critical information isn’t lost, and that there are no mid-sentence cuts or ignored section headers.
What’s new: We’ve added a “Split in chunks” processor to the prepare recipe that contains advanced options to customize the chunking process. You can configure chunk size and overlap, specify separators, interactively visualize results, and apply additional processing steps before embedding. For instance, you may wish to filter out chunks that are too tiny to be useful. With this point-and-click, no-code processor, anyone on the team can easily modify the chunking process to fit your use case’s needs.
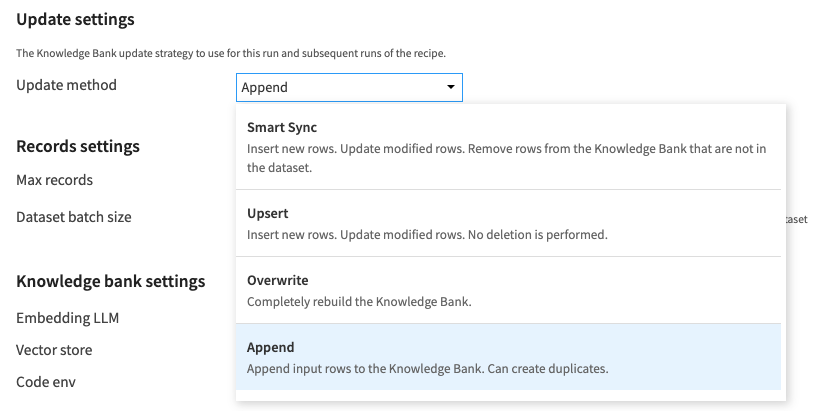
2. Smarter Knowledge Bank Updates
Many RAG use cases involve long, slowly evolving document collections like financial reports, research papers, or legal documents. Rebuilding the entire knowledge bank every time is both expensive and time-consuming.
What’s new: With intelligent update modes like append, smart sync, and upsert, you can now update only the documents that have changed, or add to your knowledge bank incrementally. This means you avoid reprocessing unchanged data, cutting embedding costs and reducing delays.
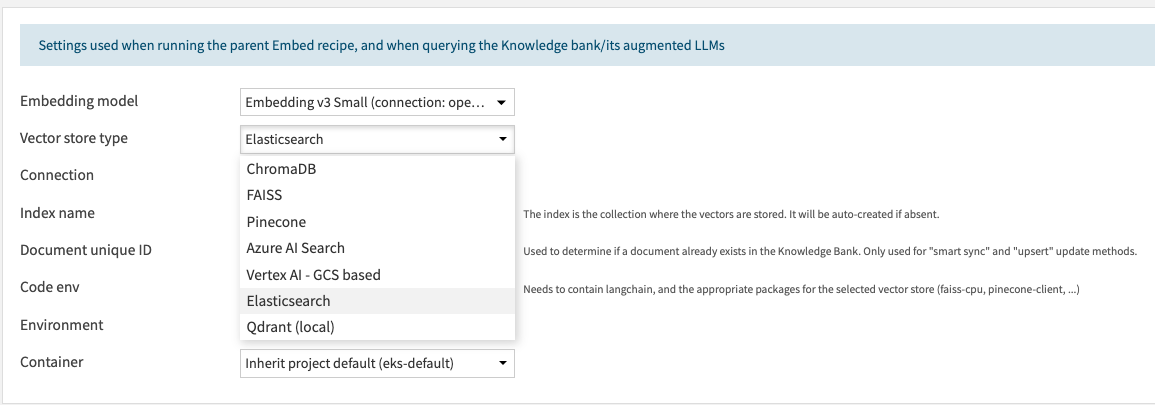
3. Expanded Vector Store Support
Organizations want flexibility in choosing the best vector store for their stack and use case, and Dataiku remains committed to keeping your options open.
What’s new: We’ve added support for Azure AI Search, ElasticSearch/OpenSearch, and Vertex AI Vector Search, alongside existing options like FAISS, ChromaDB, and Pinecone. Whatever your stack, Dataiku has you covered.
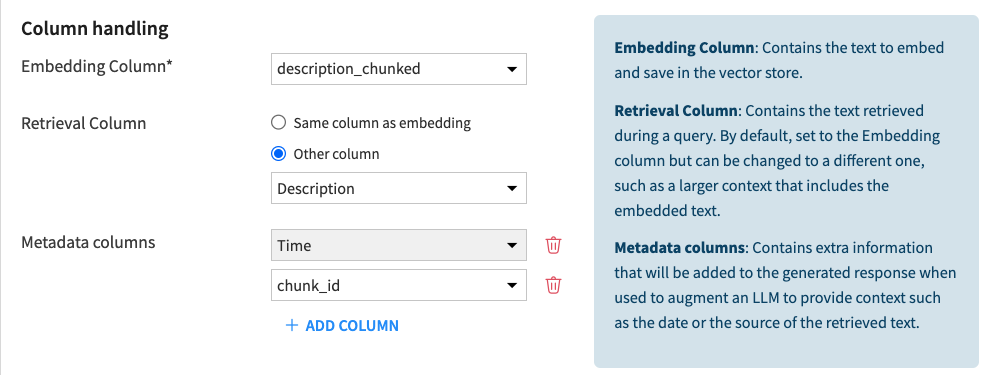
4. Better Context With Parent-Child Retrieval
One method to improve the accuracy and quality of LLM responses involves sending more context to the model than the embedded text chunks alone provide. For example, consider legal or technical documents; they often have an outline-like structure and contain many headers and subheaders that organize the content into logical sections. Although the semantic search step of RAG retrieves the most relevant embedded “child” chunks for a user’s query, you can often get better responses by including the “parent” text to which those chunks belong as additional context in the underlying prompt.
What’s new: We’ve added the ability to assign a retrieval column whose text is passed as context to the LLM. This is useful for instances where you want to send more comprehensive context than just the excerpted chunk. This ensures responses are accurate and well-informed without exceeding context limits.
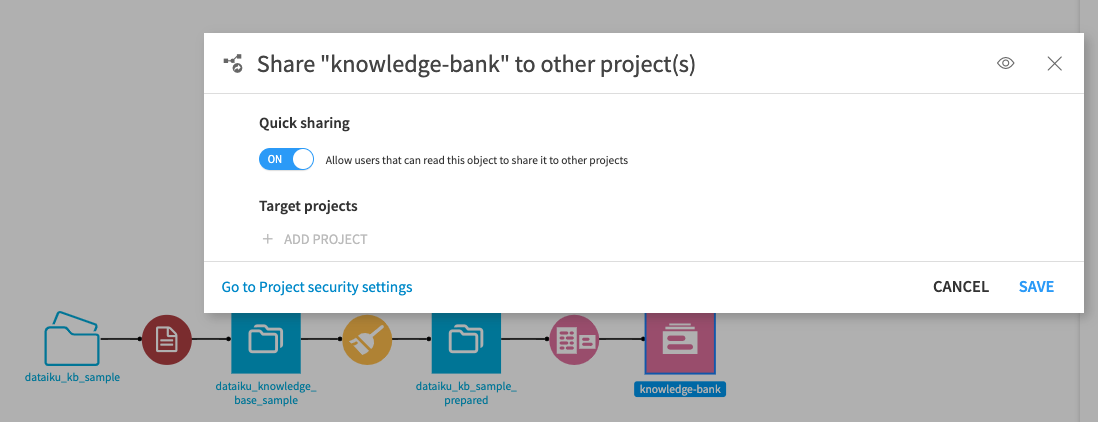
5. Shareable Knowledge Banks
Different teams often work with the same datasets and document collections, which leads to duplicated efforts and wasted resources if individual project teams build redundant knowledge banks for their RAG applications.
What’s new: Share and reuse knowledge banks across projects to ensure consistency and reduce storage and runtime costs. This feature is especially useful for enterprises with multiple RAG applications that pull from the same corpus of data.
{kind=link}
What's Coming Next: New RAG Features on the Horizon
Our commitment to improving RAG processes doesn’t stop here. Let’s take a sneak peek at some upcoming exciting additions to your RAG toolkit:
Hybrid Search
Classical RAG uses a semantic search approach to retrieve the most relevant chunks for a query, but combining semantic search with keyword matching can be one way to improve the quality of retrieved source information. This is particularly true for domains with specialized jargon that the LLM might not have been exposed to during its training.
What’s coming: A hybrid search option available with Azure AI Search and ElasticSearch/OpenSearch vector stores that blends vector similarity with keyword matching, boosting retrieval precision.
Embed Recipe for Multimodal Documents
Many documents are more than just text; they often include complex tables, charts, and images packed with critical information. However, processing these diverse formats for RAG applications has traditionally required multiple tools, steps, and custom code.
What’s coming: With Dataiku’s embed documents recipe, you can seamlessly extract and embed information from text, tables, and images in a single step, leveraging vision-language models (VLMs) for image data and LLMs for text. Choose the best processing method for your documents, ensure data such as tables aren’t split incorrectly, and generate retrieval-friendly image summaries — all without writing a single line of code. This streamlined approach improves retrieval accuracy and makes building multimodal RAG applications faster and easier than ever.
Why It Matters
RAG pipelines are quickly becoming the backbone of conversational applications, powering smarter, more accurate responses. With Dataiku’s latest enhancements, you can:
- Build and deliver RAG-based AI systems faster.
- Save on processing costs and time.
- Deliver more accurate and context-aware results.
Whether you’re new to RAG or scaling up advanced use cases, these tools make it easier to turn your organizational knowledge into a competitive advantage. Start exploring these features today and watch your conversational AI take off!