




{kind=link}
Time and time again, we hear how organizations are increasingly investing in AI, but struggling to generate (and maintain) actual business impact from their analytics and AI projects. With their heads down on a scaling AI journey, how can they sift through what’s actually worth the resources versus what’s purely hype?

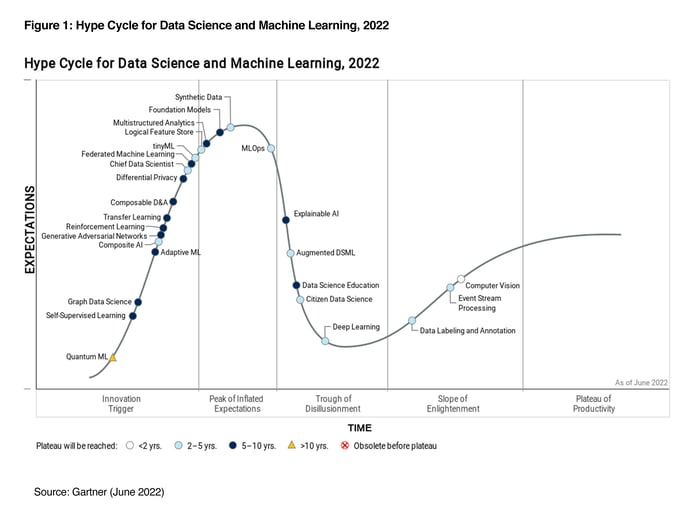
The Gartner Hype Cycle for Data Science and Machine Learning highlights what data science and ML concepts have high or transformational benefits, their business impacts, key drivers, obstacles to implementation, and more. In the Gartner view, the darker the color of the concept on the Hype Cycle (see the image below), the more attention data and analytics leaders should pay (generally) to the innovations.
This article highlights “hot takes” from a myriad of subject matter experts at Dataiku and their thoughts on some of the concepts featured on this year’s Hype Cycle for Data Science and Machine Learning. Which ones are worth investing in now and which ones are just hype? Read on to find out!
Citizen Data Science and Data Science Education
This section provides insights from Shaun McGirr, Dataiku’s RVP of AI Strategy, EMEA.
Our Summary of the Gartner View
In the 2022 Hype Cycle, Gartner has placed both Citizen Data Science and Data Science Education just after the steepest downward slope of the trough of disillusionment, and both are assessed as relevant to 5%-20% of the target audience. Data Science Education is described as the "best answer to further narrow the data science talent gap" because it directly increases talent supply, while the "functional knowledge of citizen data scientists adds a dimension of efficiency, efficacy and depth" on the demand side of the talent gap.
They note vendors and higher education institutions have brought an "overwhelming number" of competing offerings to market, lowering the cost of acquiring foundational knowledge, while noting that true gains are realized only when this knowledge is applied in practice, not the classroom. To convert education into business impact, Gartner notes the importance of leadership buy-in to the upskilling effort, ensuring collaboration within and between expert and citizen data scientist communities, and creating career pathways so the recently upskilled stay with the organization.
Dataiku’s Reaction
Our experience providing the technology behind many successful Citizen Data Science programs (e.g., GE Aviation, NXP), and backing the programs of leading educators (e.g., Toulouse Business School, HES-SO), broadly supports the Gartner assessment of these trends. Demand for data science talent far outstrips supply, powering the continued expansion of educational offerings outside employment, but these cannot alone close the talent gap, and so most data-mature organizations are considering or already investing in solving that problem internally.
Where our opinion would differ is in the placement of one of the trends on the Hype Cycle itself. This is largely driven by our observation that organizations' approaches to Citizen Data Science more closely resemble either "Innovation Trigger" or "Slope of Enlightenment" behavior. Relatively few have actually crossed the trough, and did so quickly, but for the majority Citizen Data Science is still a theory with great potential but little practical action. While this might put the "average organization" in the Trough of Disillusionment, no organization can be there for long, as the business cases for Citizen Data Science tend to be proven (or disproven) quickly.
We do agree that Citizen Data Science will reach the Plateau of Productivity faster than Data Science Education (2-5 years vs. 5-10), because the former is the true economic driver of demand for talent, generated out of organizations' need to accelerate their digital and data transformations.
How Can Organizations Increase Speed to Value and Breadth of Applicability Through These Trends?
The Gartner user recommendations for both trends make sense to us, but we would synthesize and sharpen them into a set of "acid tests" you can apply to your organizations' efforts to win the war for talent through upskilling.
- Can you name a specific individual in your organization, whose work and aspirations you understand, who could be one of your future Citizen Data Scientists? Too often such initiatives are built around a theory that these people must exist, without data leaders ever having met them.
- Is your business case for Citizen Data Science backed by an investment case to create the necessary support functions to make it happen? Too many Citizen Data Science initiatives are technology-led exercises where data leaders believe choosing a low-code tool is the end game, forgetting about the significant people and process change (and therefore leadership buy-in) needed to make upskilling an everyday value driver, not just a Friday afternoon hobby.
- Do you have a story for how upskilling through Citizen Data Science will deliver a capability that transforms the organization? As the use cases tackled by the newly upskilled will, by definition, be less well-understood by central data teams, a story for your stakeholders that relies on delivery of just a few key use cases is risky. Instead your story should explicitly quantify the long-term value of the change in human capital that you will unlock, which itself improves the quality and quantity of delivered data products over time.
MLOps
This section provides insights from David Talaga, Product Marketing Director at Dataiku.
The technology approach of covering MLOps capabilities is indeed one of the first aspects to be considered. Organizations tend to tick the box of all the capabilities needed to operationalize machine learning projects. However, the offer is quite deep, and many technologies offer unbalanced sets of capabilities associated with different stages of MLOps.
According to the Hype Cycle report, “Organizations tend to think of MLOps as a technology or procedure; instead, it is a way of working that involves different personas coming together to productionize an ML workflow.”* Few, however, are able to actually meet the complete requirements of a new way of working in MLOps, where it involves multiple personas with different skills and backgrounds.
Several challenges arise:
-
How to create this new way of working through new, intra-project collaboration services?
-
How to equip business practitioners and citizen data scientists with self-serve capacities to discover and cleanse data on their own whilst integrating into the new way of working?
-
How to ensure that people in the business have the right indicators to study the business impact of a drift in an ML model?
-
How to provide clear insights to risk managers so that they can make an informed choice when approving model deployment in respect of a governance framework?
Organizations need to think beyond technology to focus on simplicity, flexibility, and ease of operationalizing criteria within a platform. That’s critical to cover all the stages of industrialization of sourcing, from the discovery of data to the monitoring of models and their re-training on more recent data when necessary.
With multinational insurance company and Dataiku customer Aviva, a specific team (the Digital Operations Management Engine) was set up to address significant IT operational challenges, dealing with huge IT assets, numerous processes, and multiple support teams. In a project aimed to optimize historic incident management data and log details, Dataiku’s MLOps capability helped in quickly getting the working model in time.
Another example of MLOps in practice comes from ZS, an Indian management consulting and technology firm focused on transforming global healthcare and beyond. ZS partnered with a life sciences and pharmaceutical organization to help orchestrate 100+ data science models projected to bring in annual incremental growth of $200 million. MLOps came into the picture when Dataiku was chosen as the central platform for all model deployments. The decision was taken notably because of Dataiku’s user-friendliness for multiple personas, from data scientists and business analysts to domain subject matter experts. Today, over 10 models have been deployed on the Dataiku platform with added MLOps utilities like model health monitoring, data drift analysis, and many more.
Foundational Models
This section provides insights from Krishna Vadakattu, Sr. Product Manager at Dataiku.
As is reflected by the positioning beside the apex of the curve, there is perhaps no better subject to epitomize the Hype Cycle for Data Science and Machine Learning in 2022 than Foundational Models.
To their credit, much in the way convolutional neural networks revolutionized computer vision and opened the floodgates to deep learning research, large language models have delivered a step change in natural language processing performance, heralding a new era of data science and machine learning for unstructured data based on transformer architectures.
Early enterprise use cases have been identified that could support knowledge workers, from analysts to engineers — asking questions to data sources conversationally (databases and documents) or writing technical documentation based directly off code. Whilst these feats would be interesting enough on their own, the application of such models is made more impressive by the lack of training and development required to immediately deliver on such tasks and receive value.
That being said, as Gartner notes, it would be wise to exhibit caution directly relaying outputs of these products to end users in the enterprise as they may not be aware of the bias and limitations inherent in these assets. These models have been trained to learn and infer patterns across a large corpora of information. They absorb some of the knowledge and thereby reflect some of the authors’ biases; similarly, they have learned to mimic and relay convincing responses, rather than comprehend a true understanding of the underlying concepts and relations.
To skip past the trough of disillusionment and accelerate towards the slope of enlightenment, businesses would do well to incorporate established foundational models into their existing natural language tasks today, for immediate performance benefit. Early contenders for reaching the plateau of productivity could be in text-heavy workflows such as customer operations, where there are opportunities for augmenting the capabilities of workers involved in document review, data entry, and Q&A activities.
It is unlikely to be worthwhile yet for many organizations to delve into domain adaptation of these artifacts, as there remains a substantial burden on technical resources (data, compute, and talent) to achieve significant benefits over the out-of-the-box models shared by the tech giants. It would be prudent to take advantage of the early, low-hanging fruit, before moving on to more sophisticated use cases in a few years’ time, as these barriers to entry are rapidly being diminished.
Explainable AI
This section provides insights from Maxime Appé, Technical Product Manager at Dataiku.
After two years around the peak of the curve (see Data Science & Machine Learning Hype Cycles 2020/21), Gartner sees Explainable AI, or XAI, starting its descent towards the trough of disillusionment, and for good reasons.
XAI has had its fair share of publicity in recent years. Without diving into details at length (as the topic is already exhaustively described in many papers), two key elements can be mentioned. First, the deployment of legal frameworks and regulatory requirements towards a more transparent and responsible use of AI helped reach a consensus on motivations, such as providers’ accountability, consumers’ trust, reproducibility, and robustness. Simultaneously, development of new techniques has taken interpretability forward a giant leap: glass-box models (interpretable by design, e.g., linear, tree-based models) gained wider acceptance and “black box explainers” (model-agnostic methods, e.g., SHAP, LIME) are more systematically used.
In spite of these driving forces, XAI is currently undergoing criticism about certain shortcomings and still has a long way to go before reaching enlightenment and mainstream market adoption, as clearly stated by Gartner. But legal, ethical, and practical motivations are not going anywhere; these shortcomings are also clear opportunities for the future.
To explain this idea, we can cite the famous concept in AI called the interpretability-performance trade-off. It inevitably leads to the underlying conclusion that explainability is applied at the expense of effectiveness and hinders the development of advanced techniques, such as multimodal machine learning, transformers, or generative AI (the positioning of Multistructured Analytics, Foundational Models, and GANs on the Hype Cycle speaks for itself). Why settle for that? Why not aim for a win-win situation where AI is both leading-edge and explainable? Powerful techniques, such as Integrated Gradients, are emerging and paving the way for promising research efforts.
XAI is also criticized for not “reaching” end consumers and decision makers in ways they can balance with domain knowledge (interpretable is not explainable, as rightly put by Gartner). Putting business context back at the heart of AI development is crucial for global market adoption and represents a major opportunity for XAI to shift from post-hoc to ad-hoc analysis, from factual to actionable. In other words, the question becomes: “Now that we know why this prediction was made, what do we do next?”
Looking Ahead
As organizations prepare for the new year and begin to iron out their plans for scaling AI in 2023 and beyond, it is our hope that these insights on key data science and ML techniques are helpful not only during that preparation stage but during actual implementation as well. According to Gartner, “The two most prominent drivers within data science and machine learning are:
- Speed to deliver value from investments with the pace at which businesses operate
- Applicability to be relevant to the requirement, while providing transparency and wider usage across the enterprise.”*
At Dataiku, we believe that a systemized approach to AI requires empowering all people (including the business) in a central place, governing the lifecycles of all AI projects, and accelerating the time it takes to deliver AI projects from months to days. So, no matter what novel techniques from the data science and ML landscape organizations choose to experiment with, it’s important for them to keep their fingers on the pulse of which ones are taking hold in the market (and their bespoke challenges) in order to stay ahead and generate tangible business value in the months and years to come.
*Gartner - Hype Cycle for Data Science and Machine Learning, 2022. 29 June 2022, Farhan Choudhary, Peter Krensky. GARTNER and Hype Cycle are registered trademark and service mark of Gartner, Inc. and/or its affiliates in the U.S. and internationally and are used herein with permission. All rights reserved.