




{kind=link}
In a survey of 400 global data leaders, nearly a quarter of respondents (24%) cited a “lack of quality data or ability to easily access the right data” as their most present barrier to delivering more value from analytics and AI.
It’s clear that data quality is a continuous challenge for organizations for many reasons, but these are the ones we observe time and time again:
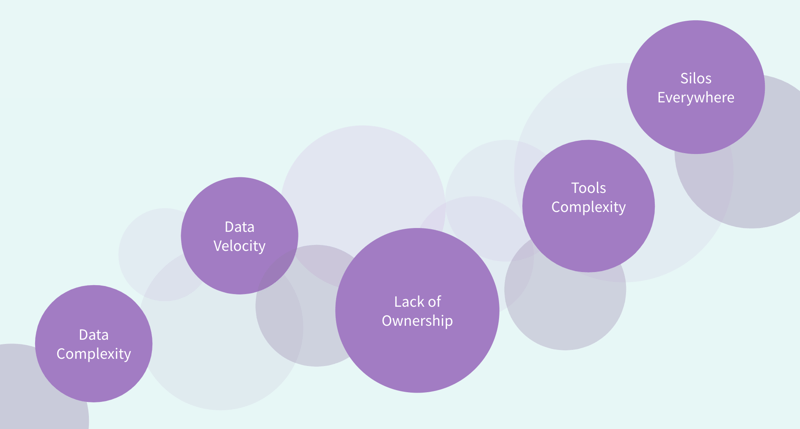
So, how can data leaders “fix” their broken data quality efforts? This article rounds up some of the solutions (and how Dataiku can help) and, hint, it’s urgent: The longer teams wait, the more it will cost. According to “Making Quality Work: A Leadership Guide for the Results-Driven Manager” (Labovitz, Rosansky, Chang), verifying the quality of a record at the point of entry costs the business $1 (prevention cost). Cleansing and deduplicating a record at later steps costs the business $10 (correction cost). Continuing to work with a record that is never cleansed costs $100 (failure cost).

Discover Data With Ease
Are you constantly asking yourself, “How can I quickly find common issues in my datasets? How can I go deeper in data analysis to understand deeper problems? How can I stop wasting so much time fixing datasets and start reusing trusted components?”
Industry statistics used to cite that data preparation took up to 80% of time dedicated to a data project. According to an Anaconda survey, that number was reduced to 45% of data scientists’ time, including data loading and cleaning. Despite this improvement, data discovery, fixing errors, and data preparation all remain time-consuming steps that need to be optimized to truly scale AI and avoid project failure.
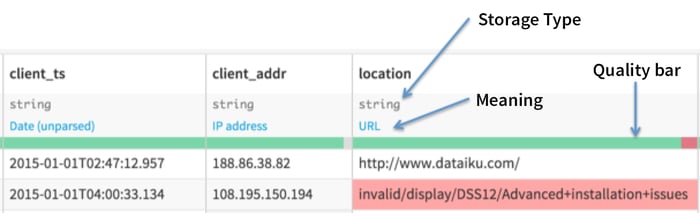
If the answer to any of the questions above is yes, then Dataiku can help you. Dataiku enables users to discover data quality on their whole dataset or choose sampling for best performance in interactive exploration, so teams can gain a visual and permanent understanding of data quality issues. By default, the explore views for a dataset shows a data quality bar, which shows which rows are valid for their meaning.
Dataiku also offers exploratory data analysis to proactively identify and rectify data flaws, leading to improved ML models, reliable algorithms, and informed business strategies. Finally, the Dataiku Feature Store enables teams to leverage existing trusted data and streamline the process of building, discovering, and utilizing critical data. The most relevant data is readily available, eliminating the need for arduous and repetitive data preparation. This empowers data scientists and other practitioners to effortlessly tap into a trove of valuable features, enabling them to focus their expertise on crafting powerful models and making impactful insights.
The analysis from AI/ML is only as good as your data — it’s the age-old saying, right, garbage in, garbage out. There’s a lot of data being created, but at the same time, there has been a lot of focus on cleaning and organizing data in the best way.”
-Masood Ali, Senior Director of Data Strategy and Governance, Royal Bank of Canada, MIT Technology Review Insights, produced in partnership with Dataiku
Make Data Reliable Together
Are you wondering how you can do data preparation tailored to your own skills? Or how to ensure data quality to deliver the most efficient model? This step epitomizes analytics and AI democratization — bringing technical and business teams together and giving data and domain experts equal capabilities on the same platform.
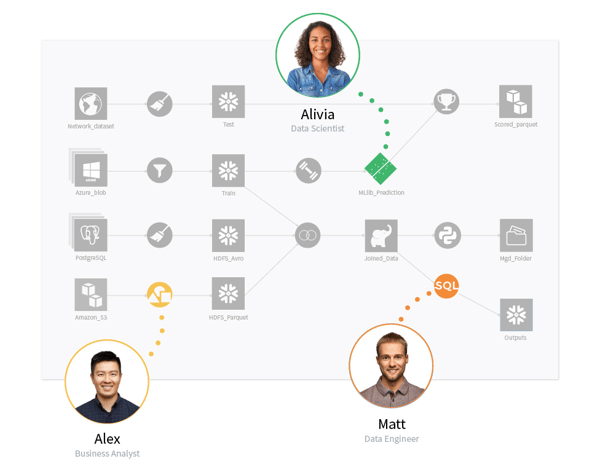
Dataiku provides a visual grammar that makes data quality a team sport. The Dataiku flow provides a visual representation of a project’s data pipeline and is the central space where data and domain experts view and analyze data, add recipes to join and transform datasets, and build predictive models. The visual flow also contains code-based and plugin elements for added customization and extensibility.
The platform also allows teams to do data prep with visual simplicity. It provides easy-to-use visual interfaces to join datasets, group and aggregate, clean, transform, and enrich data, all with a few clicks. They can even incorporate the latest Generative AI techniques without code. However, if technical experts would rather code, they can do that using familiar languages such as Python, R, and SQL.
Control & Share Trusted Data at Speed
Eager to leverage your team to enrich your data? Want to stop bad data from polluting your pipeline and start monitoring data quality?
With scenarios, alerts, and checks in Dataiku, teams can define and monitor data quality and ensure continuous data integrity. These settings enable users to proactively monitor and measure the evolution of datasets, folders, and models within the Dataiku flow as well as easily compute metrics like missing values or model accuracy.
Dataiku also provides a Data Catalog — a central place for analysts, data scientists, and other collaborators to share and search for datasets across the organization. From the homepage, teams can search for data in three categories:
- Data collections: Curated groups of datasets and information about those datasets in order to reuse them in their own projects
- Datasets and indexed tables: Teams can search for any dataset used in projects on their organization’s Dataiku instance.
- Connections explorer: Users can browse their organization’s remote connections such as BigQuery, Hive, or SQL server connections. Then, they can browse, filter, and preview the tables on a connection and import select stables into their Dataiku projects.
ML and AI Won’t Scale Without Data Quality
Chad Sanderson, LinkedIn data quality influencer and Chief Operator at Data Quality Camp, said, “Machine learning and AI will never scale without data quality. Teams that believe they can invest in science without infrastructure are in for a painful surprise. Data science teams … ensure you have a clear set of constraints in place that can be translated into upstream contracts which facilitate ownership, change communication, and expectations, otherwise, you’ll spend 10x more time on maintenance downstream than optimization and good science.”
We echo those sentiments. Without data designed for scale (or collaboration across data assets), teams can face pretty catastrophic (and costly!) issues. It’s always been true that solving data quality problems is hard work, but we’re now in an era where the topic needs to become part of everyday, ordinary thinking. Remember: data quality does not mean perfect data. It means data is fit for purpose (i.e., use cases that you want to apply that data to).