




{kind=link}
The gap between research in the machine learning (ML) space and how people actually leverage ML in an enterprise context can be wide. Case in point: large language models (LLMs) and Generative AI. That’s why the Dataiku AI Lab seeks to build a bridge between ML research and practical business applications. This blog post is a glimpse into the team’s most recent ML Research, in Practice video series with special guest Luca Beurer-Kellner, one of the authors of "Prompting Is Programming: A Query Language for Large Language Models."

Today’s LLMs can do many things, from classification to question/answering, writing a story, generating code, and more. But they also have some key challenges that stand in the way particularly of enterprise applications.
For one thing, control can be a huge problem. No matter how good the input (i.e., the prompt), LLM responses may still go wrong in unpredictable ways. For example, you can use the same input multiple times and get different results. Or you build something, it works all nicely in your development environment — then suddenly in practice, some new input comes in and it all breaks down.
In addition to the fact that LLMs sometimes don't do what you ask them to do, even worse, sometimes they don't respond in the format you expect them to (a phenomenon called interface robustness). For example, say you give the LLM some arithmetic reasoning task and you expect it to answer as a number that can then be parsed in your code and processed further. This may work most of the time … but then sometimes it just fails. Of course, this is fundamentally problematic for building systems on top of LLMs.
The other major challenge is efficiency. LLMs are really, really large neural networks, which means either you have to pay someone money to run them for you on a GPU machine, or you have to run it yourself on a GPU machine — both are expensive.
Enter: LMQL
It is with these core challenges in mind that Beurer-Kellner, along with Marc Fischer and Martin Vechev, set out to answer the question: how could LLMs — and using LLMs — be framed and seen as a programming pattern or system?
What started as a research paper has now turned into a proper open source project. The team came up with LMQL, a programming language or a query language for LLM interactions.
According to Beurer-Kellner, “The basic idea is we start out with natural language prompting. You just put text into the model and you get some response, but we augment this by programmatic components, like for instance, basic scripting abilities, like control flow. For instance, you can have multi-step prompts, and you can have prompt templates.”
One of the core features of LMQL is the ability to constrain the model by constructing prompts in a programmatic manner and imposing constraints on the LLM’s response — for example, a response of a certain length, in a specific JSON format, numerical vs. text, etc.
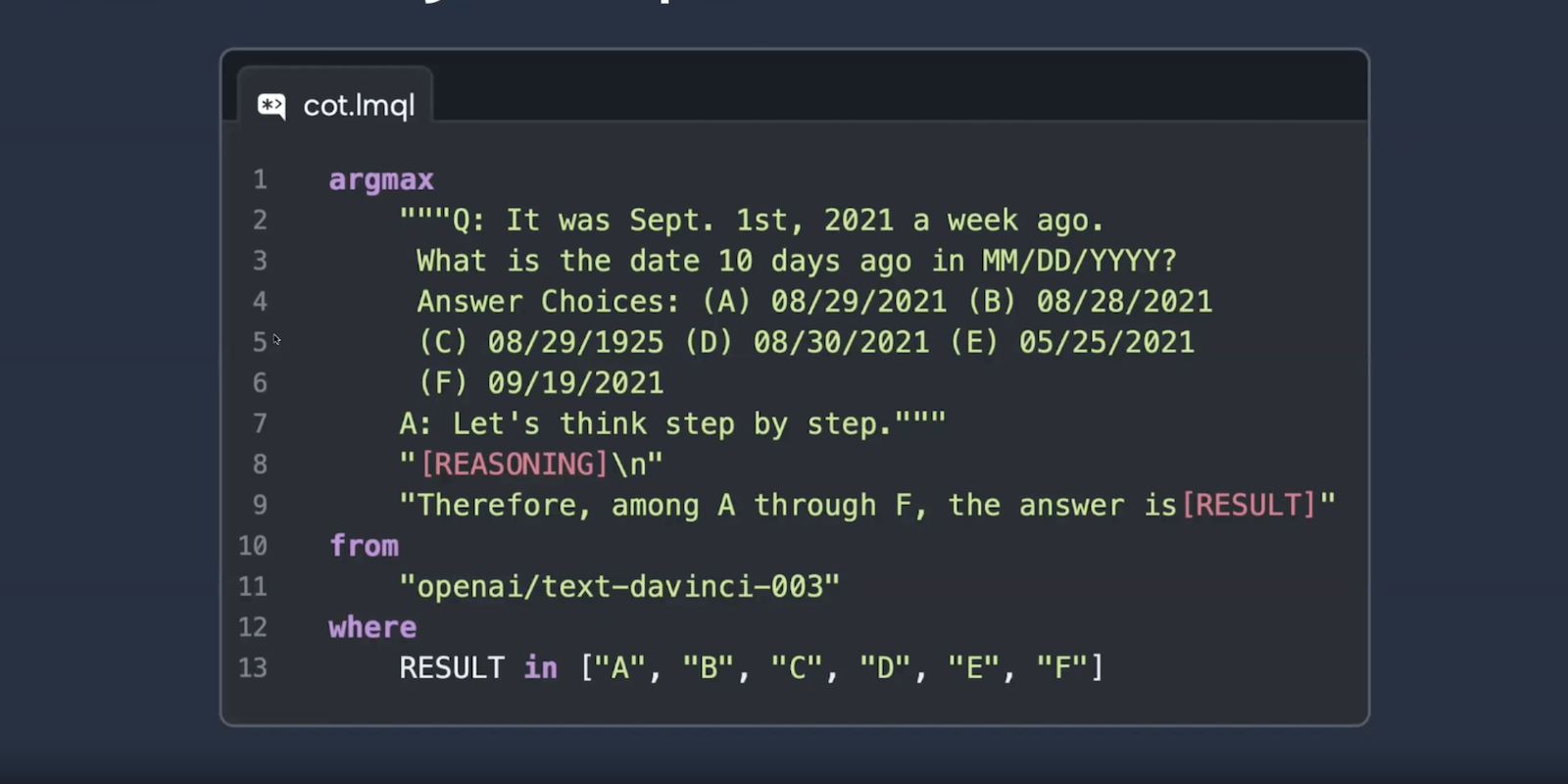
How LMQL Works
LMQL uses a form of text generation that is also known as constraint decoding. In a nutshell, standard LLM decoding is full vocabulary at each step, full choice for the model to do whatever it wants to get the magic box behavior. On the other hand, LMQL does not allow full choice at each step but actually limits the choices of the model in a reasonable way.
For a deeper dive on how LMQL works, as well as some real-life examples (including an example that augments a language model with the ability to use an external calculator tool to do its calculations), we recommend checking out the full video of the session: