




{kind=link}
We’ve previously explored what large language models (LLMs) are, how they can be used in an enterprise setting, and how the technology’s usefulness can be tested inside your organization. We’ve also delved into how ChatGPT and open source LLM technology can be leveraged in the Dataiku platform. In this blog article, we’re taking a closer look at our OpenAI GPT integration and how it makes GPT technology even more accessible with Dataiku.
Leveraging Tech Innovations Through Dataiku
ChatGPT has garnered an immense amount of attention since its release in 2022. LLMs represent not only a huge step forward in the AI toolset but also a huge step forward in how “regular” people think about technology.
Fortunately, whether through built-in features, plugins, or code elements, Dataiku has always made it easier for users of all types to access and incorporate the latest cutting-edge technologies into their projects. From cloud ML services to open source algorithms and pre-trained models, GPT and LLMs are just the most recent example of Dataiku’s commitment to being a reliable data science framework that doesn’t change, even as technologies do.
No-Code Access to GPT Models
We recently updated our Natural Language Generation plugin to incorporate the latest GPT models and have released it as the OpenAI GPT plugin. This updated component uses the expressive power of generative AI to enable users to perform pre-defined or customized NLP tasks. Its setup and usage is straightforward.
Setup:
- Set up the OpenAI GPT plugin, adding your OpenAI API key obtained when signing up for the service.
- Select the OpenAI model you wish to use. By default, GPT 3.5 Turbo (the same model used in the ChatGPT application) is used, but GPT 3 and GPT 4 are also available.
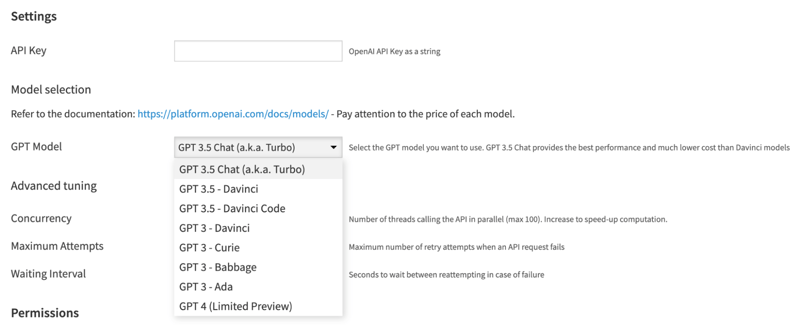
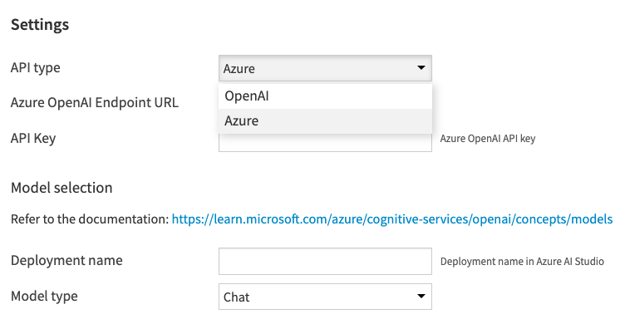
If you prefer to use Azure OpenAI’s service instead, you can select Azure and choose from chat or completion model types.
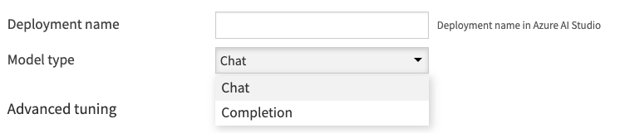
Usage:
- Prepare your input dataset as usual. This can be done using Dataiku’s visual data preparation tools or the programming language of your choice.
- Select the dataset containing the inputs, and click on the “OpenAI GPT” icon in the right panel or from the +Recipe menu in the top right corner of the Flow.
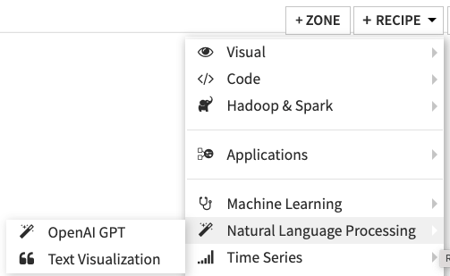
3. Use the visual recipe for text classification, Q&A, text summarization, or the catch-all recipe for open-ended text generation tasks. For text classification use cases, you may provide some examples of inputs and the corresponding desired output (few-shot modeling) or omit examples altogether (zero-shot modeling).

Benefits of Using GPT From Dataiku's Platform
With four dedicated visual recipes for text generation tasks, Dataiku makes GPT accessible to non-coders in a scalable yet transparent way. Teams can apply generative AI in bulk to full datasets (versus feeding individual queries into the ChatGPT sandbox application) while preserving both the query and outputs as part of the project Flow. Moreover, Dataiku’s plugin also adds several additional benefits versus using the API directly.
For example, although you can specify a classification task in a general text prompt (e.g., “Classify tweets in one of the following product categories: ‘spam,’ ‘legit’”), Dataiku’s dedicated task for text classification optimizes your query with behind-the-scenes scaffolding that ensures cleaner, more reliable outputs. This not only keeps you from having to make iterative, repeated queries to improve the quality of the results — which quickly spirals up costs — but also reduces the amount of post-processing to attain the outputs you wanted.
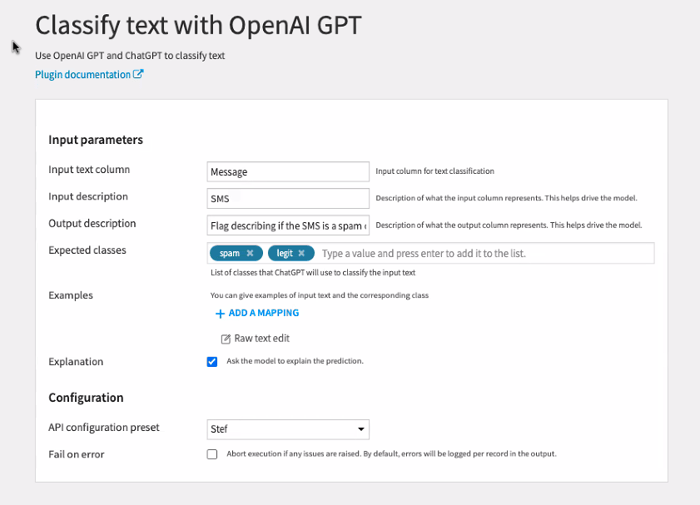
Cost savings is another tangible benefit of using these visual recipes from Dataiku. Each call to the GPT API has a small but real cost, as users are charged for each text payload to and from the service. Whether at scale or with longer documents, the bill can quickly add up.
As mentioned above, repeated queries are a fast multiplier for costs. For cases where you want to generate multiple different responses based on the same text corpus, the Answer Multiple Questions visual recipe means you can generate multiple “answer” columns while only submitting the input text once. This results in instant savings.
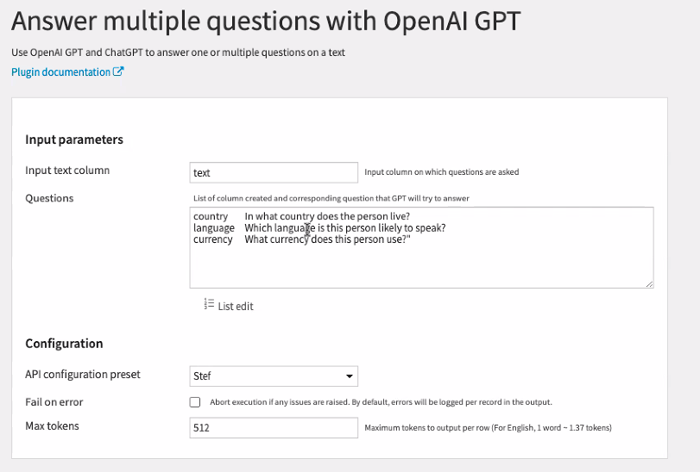
As an aside, if you want to use a private LLM instead of an OpenAI model, you have the flexibility to do so using a code recipe in Dataiku. This still gives others visibility into the steps that will allow them to trust both the method and the outputs.
To see a sample application of the GPT recipes, connecting to open source LLMs with Python, and augmenting an LLM with external tools via an agent, check out this project in the Dataiku Gallery.