




Often when companies get started with data projects (especially when the initiatives come from the C-suite or from the top down), they bite off more than they can chew and end up with less-than-optimal results. But organizations can avoid this frustration by taking a cue from the lean startup thinking popularized by Eric Ries and applying the principles of the Minimal Viable Product (MVP) to data projects.

{kind=link}
MVP & the Role of Time
When it comes to getting value from data, time is a critical component for several reasons. First and foremost because today, most companies are in a race to put their data to use — this means waiting to operationalize a machine learning or AI-powered system gives competitors more time to get there first.
Another important reason is that data projects simply take time to develop and perfect — like most other products, they won’t be 100% right on the first try. And given the fluid and dynamic nature of data (and of customer or user behavior), that time to perfect simply cannot happen in a sandbox or design environment: it needs to happen in real time on real data. A data team could spend a year developing and honing what they think is the perfect model in a sandbox, but then observe that model perform in unexpected ways when it gets into a production. That team would have thus wasted a year.

That’s why data projects fit well into the MVP methodology. If the best way to see how a model performs is in production, then the key to successful data projects is getting models into production early, adjusting, and pushing new models often.
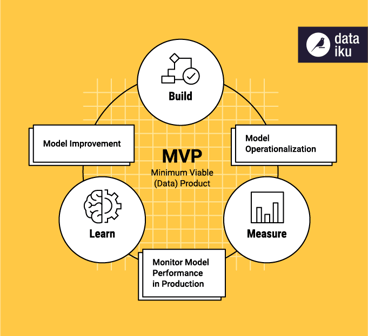
MVP Principles for Data Projects
There are a few key principles from MVP thinking that apply particularly well when thinking about how to approach data projects (especially first data projects):
- Stay grounded in concrete use cases. It’s easy, when it comes to data initiatives, to get carried away, buying all the latest and greatest technologies right off the bat and then figuring out how (or where) to use them later. But by not basing technology purchases in actual current needs for that technology, companies can end up with lots of fancy — not to mention expensive — tools that they can’t really practically use.
So even before talking about data projects, it’s good to think about an MVP also for the data team and for data infrastructure. One of the purposes of an MVP is to be able to test a hypothesis with minimal resources, which means not making huge investments in data infrastructure until it’s clear what the needs are for a specific project.
- Start small and simple, then work up to a bigger vision. A data team’s directive from executives might be to launch, for example, real-time price optimization company-wide. That is a tall order that will take lots of time to build completely, and even when complete, might not work as expected in a production environment on real data. Instead, how can the data project be broken down into smaller pieces, operationalized as an MVP, and then expanded to meet the larger goals?

In the previous example, that might mean putting a smaller-scale version of the real-time pricing model in production for use by a small subset of brick-and-mortar stores or one part of the e-commerce site. Once the model’s performance is monitored and evaluated, it can be adjusted to make improvements, then expanded once it’s optimal.
This prevents the team from spending too much time on development upfront, reduces friction, and also reduces the potential impact on the larger business if the first iteration of the model in production ends up negatively affecting revenue.
An MVP is a down payment on a larger vision.”
Johnny Holland
- A/B test in production. The purpose of A/B testing different models is to be able to evaluate multiple models in parallel and then comparing expected model performance to actual results. This is a quick way to test multiple approaches of MVPs to get to that larger vision faster. However, offline testing is not sufficient when validating the performance of a data product, and here are a few reasons why:
In use cases such as credit scoring and fraud detection, only real world tests can provide the actual data output required. Offline tests are simply unable to convey real-time events, such as credit authorizations (e.g., is the credit offering aligned with the customer’s repayment ability?).
A real-world production setup may be different from your actual setup. As mentioned above, data consistency is a major issue that results in misaligned productions.
If the underlying data and its behavior is evolving rapidly, then it will be difficult to validate the models fast enough to cope with the rate of change.
Read more on the ins and outs of A/B testing in production here.
MVP and POC
There is perhaps no other setting where abiding by the MVP way of thinking is more important than when running a data science proof of concept (POC); all of the above principles (and more) apply, but the stakes are higher because generally there is something (whether the team or a tool/technology) being evaluated.