




{kind=link}
When performing hyperparameter optimization, we are really searching for the best model we can find within our time constraints. If we searched long enough, with random search we would get arbitrarily close to the optimum model. However, the more hyperparameters we have to tune, the larger our search space and the more infeasible this becomes, especially when we are working with larger real-world datasets and each model we test can take hours to train.

This is why in AutoML the best search strategies are those that can quickly hone in on the most promising regions of search space to explore, and therefore find better models in the limited amount of time available to train and test models.

One way to refine the search space is to study which hyperparameters are most ‘important’ and focus on them. For a given machine learning task it is likely that changing the values of some hyperparameters will make a much larger difference to the performance than others. Tuning the value of these hyperparameters can therefore bring the greatest benefits.
By studying the importance of the different hyperparameters over many datasets, we can try to meta-learn good values for the hyperparameters. For the most important hyperparameters we hope to reduce the search range and focus on the best values, while for the least important ones, we could fix them to a single value and thus remove entire dimensions from a grid search.
This is exactly what Jan N. van Rijn and Frank Hutter propose in their paper “Hyperparameter Importance Across Datasets”.
We think this is a really interesting approach to crafting a more targeted hyperparameter search when you have limited resources, and it has the potential to offer valuable insights to data scientists as well, so we decided to test it for ourselves on XGBoost to see what insights we could glean.
How Can You Identify Which Hyperparameters Are Important?
To determine which hyperparameters have the largest impact on the model performance, first you need to collect an unbiased dataset of performance evaluations with different combinations of hyperparameters by doing a random search on many different datasets.
Then, for each dataset you can use functional ANOVA to decompose the variance in the performance metric and attribute it to each of the hyperparameters and their interactions. This is a quantitative measure of the importance of each hyperparameter.
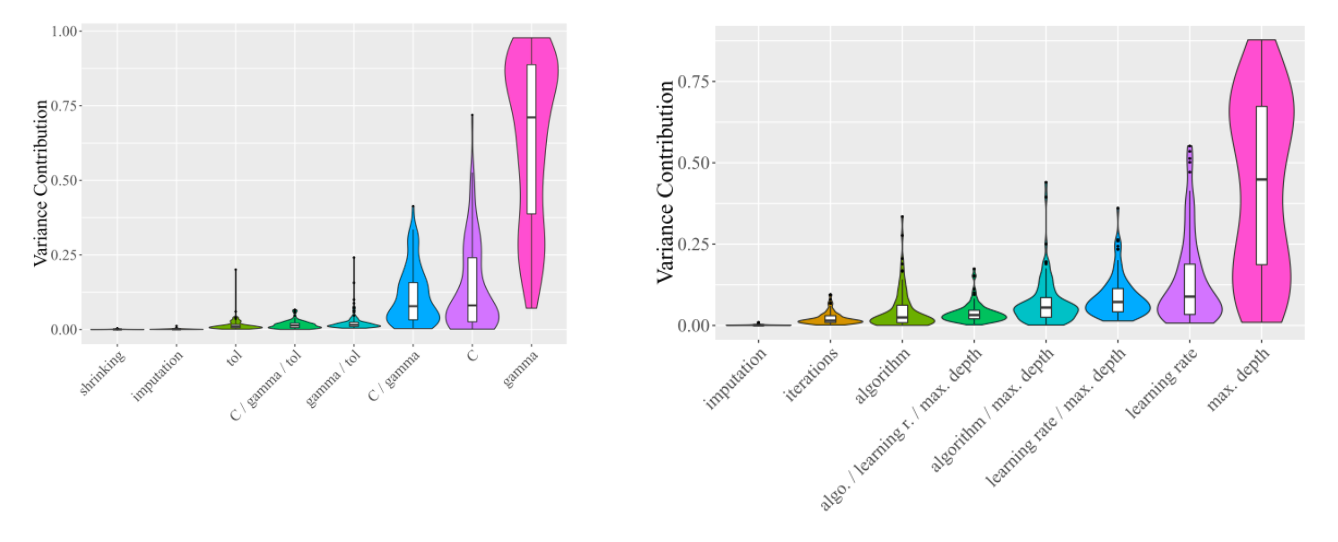
When you aggregate these variance contributions or importances over all the datasets, you can identify which hyperparameters are generally more important. To illustrate this point, in figure 1 the violin plots show the distribution of importances for each hyperparameter, ordered by the median. On the left are the hyperparameters for SVM with the RBF kernel where gamma is shown to generally be the most important hyperparameter, and on the right for the AdaBoost algorithm, max depth was found to be generally the most important hyperparameter.
Hyperparameter Importance Density Distributions
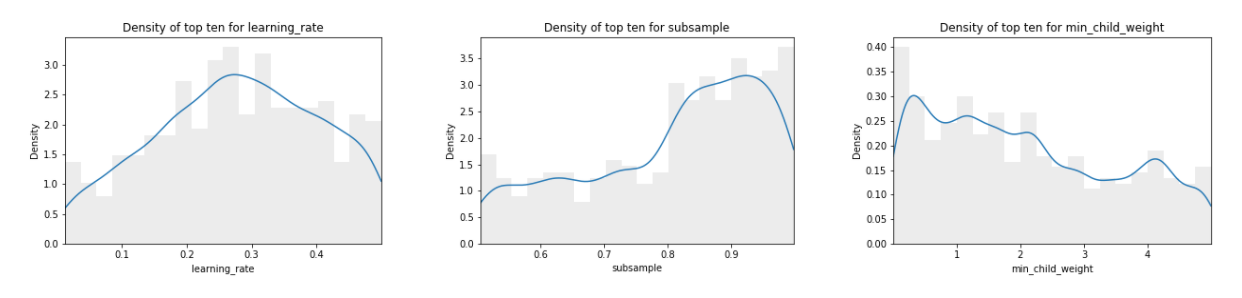
To study whether or not there are clear best values for each of these hyperparameters across all the datasets, the ten best models found during the random search are selected and for each hyperparameter independently, a 1-dimensional Kernel Density Estimator is fitted to these best evaluations to create density distributions. Examples of these density distributions from the algorithms studied in the paper are shown in figure 2. Since these distributions were used as priors to sample from for hyperband, they were referred to as priors.
More Random Forest Hyperparameters
Here at Dataiku we build the Dataiku Data Science Studio (Dataiku DSS), a collaborative data science platform that allows coders to collaborate with non-coder profiles to explore, prototype, build, and deliver their own data and AI products together. Dataiku DSS offers the possibility to train machine learning algorithms through a visual interface.
We were particularly interested in looking at the hyperparameters that we expose in the visual machine learning interface of Dataiku DSS, so we ran the experiments again while searching over different hyperparameters. We also extended the range for min samples leaf, as we expected that higher values would perform better for larger datasets. We evaluated 225 models for each dataset. For each combination of hyperparameters the model was evaluated using 3-fold cross validation for the metric AUC.
The hyperparameters and their values we searched over were:
- Min Samples Leaf: 1–60
- Max Features: 0.1–1.0
- Max Depth: 6–20
- Number of Estimators: 10–200
We again found the most important hyperparameter to be min samples leaf, followed by max features and number of estimators, the new violin plot can be seen in figure 3.
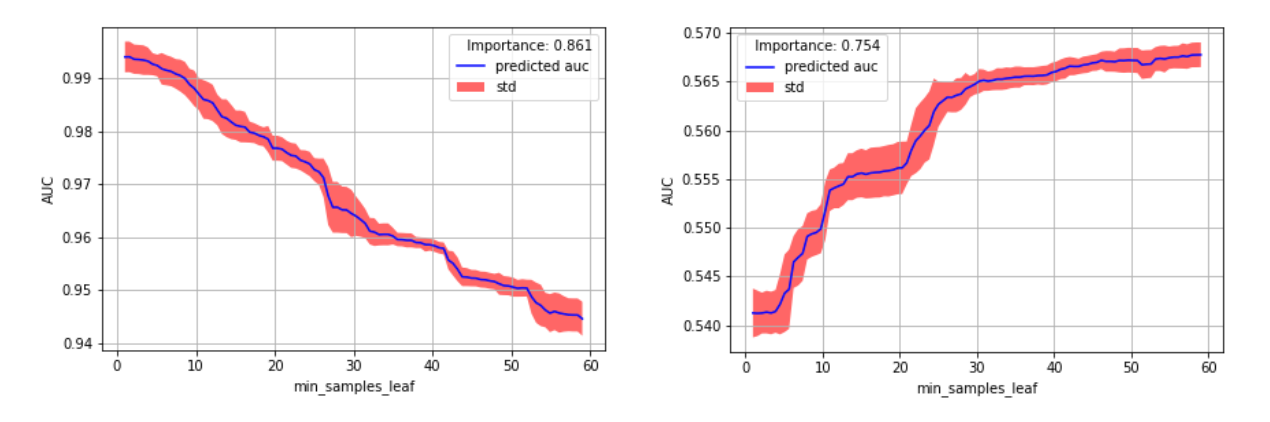
We found that min samples leaf had a higher importance than the original experiments because the range was larger and very high values in some cases could seriously degrade the performance. However lower values were not always better, as can be seen by comparing the two datasets in figure 4.
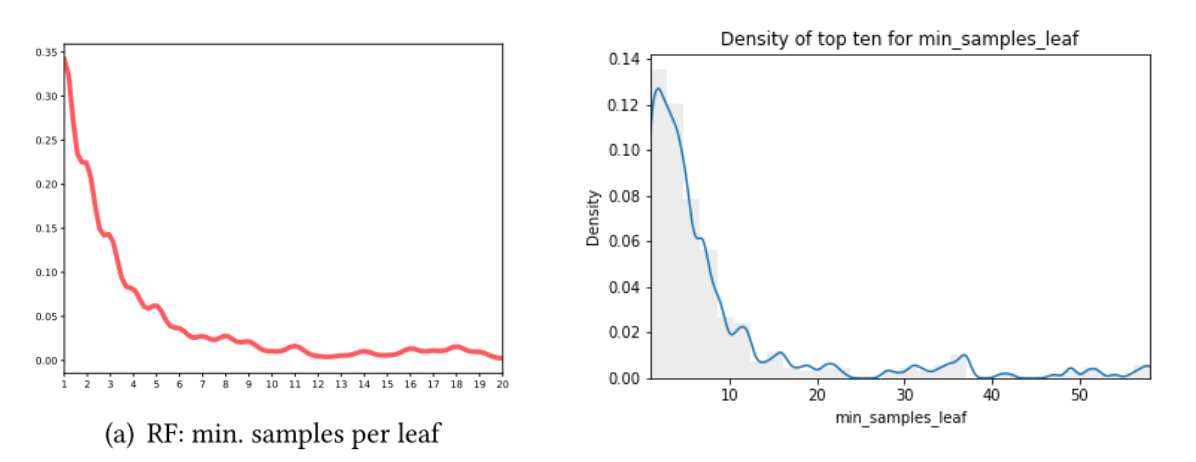
We created the density distributions to explore the best values of this hyperparameter over the full set of datasets and recovered a similar shape to that in the original experiments. This is shown in figure 5.
XGBoost Experiments
XGBoost is an algorithm with a very large number of parameters. We are using the implementation with the scikit-learn API, which reduces the number of parameters you can change, and we decided to restrict our study to those available to tune in Dataiku DSS. The hyperparameters and their ranges that we chose to search over are:
- Booster: Gbtree, dart
- Cpu tree method: Exact, hist, approx
- Max Depth: 3–20
- Learning Rate: 0.01–0.5
- Gamma: 0.0–1.0
- Alpha: 0.0–1.0
- Lambda: 0.0–1.0
- Min child weight: 0.0–5.0
- Subsample: 0.5–1.0
- Colsample by tree: 0.5–1.0
- Colsample by level: 0.5–1.0
The technique for fanova relies on training a model to predict performance, as they detail in the paper [1], this requires a minimum number of evaluations, which increases with the number of dimensions in the search. Since we were searching over 11 hyperparameters, we increased the number of evaluations per dataset from 225 to 1500 to improve the quality of the underlying model. All models were evaluated on AUC averaged over 3 fold cross validation, and training was stopped after 4 early stopping rounds.
In figure 6 is shown the violin plot of the importances over all datasets, learning rate was found to be generally the most important, followed by subsample and min child weight.
Important Hyperparameters for XGBoost
From our experiments we found that:
- For learning rate, higher values of 0.2 and above tended to perform better.
- For subsample, the density was increased above 0.8.
- For min child weight, there is increased density at lower values. A setting of 0 means no minimum weight is required on the sum of the instance weight in a child, therefore no regularization. This means the algorithm can be much slower, and thus setting this parameter to 1 (which is the default value) represents a good trade off between performance and training time.
What Are Our Takeaways From This Experiment?
This is a very interesting technique that can help data scientists build intuition about the effect of changing the hyperparameters for an algorithm, not only generally, such as in studies on benchmark sets of datasets, but in particular for a given task, as the effect is data-dependent.
It can help you to tune your algorithms faster by focusing on the hyperparameters that bring the largest performance improvement. Generally, that is min samples leaf for random forest and learning rate, subsample and min child weight for XGBoost.
Why Is Min Samples Leaf for Random Forest Almost Always Better Set So Low?
While doing this study, we were surprised to find that higher values of min samples leaf did not bring higher performance as often as we expected. This subject has already been discussed in the scikit-learn community and it may be due to the way this parameter has been implemented in scikit-learn. While the expectation may be that the way this parameter would behave would limit the depth of the trees, in reality it simply does not consider splits that would leave fewer than the minimum number of samples in a leaf, and so the algorithm could choose a worse split instead of halting the splitting.
How to Set the Number of Estimators?
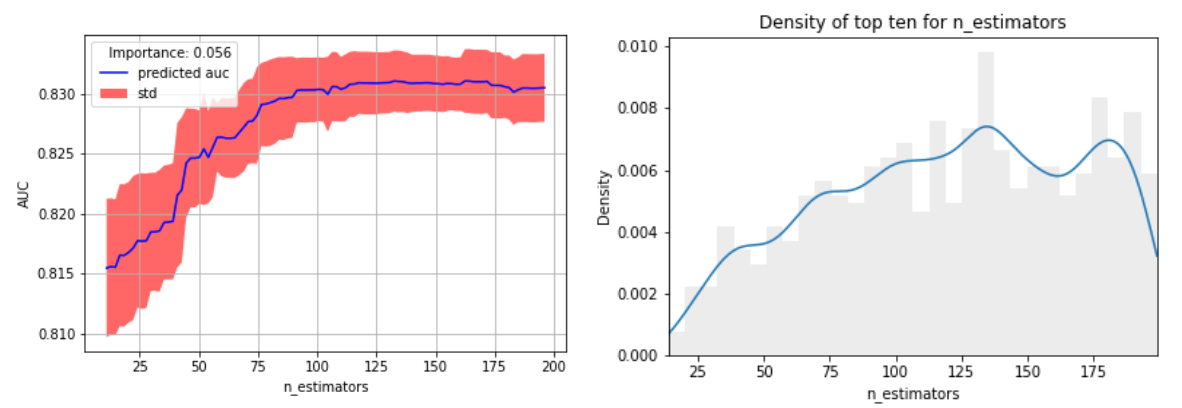
We found the number of estimators for random forest to be only the third most important hyperparameter. We were interested to see what would be a reasonable number of estimators that would be likely to give good performance.
By looking at the marginal performance for each dataset as well as the distribution of best values across all datasets, we see that while 10 estimators frequently led to lower performance, once the number of estimators reached 100, the performance was relatively stable. In figure 8 is an example of the characteristic shape of the marginal performance on the left and the density distribution of best values over all datasets on the right.
Given that the training time increases with the number of estimators, a sensible default value for this hyperparameter would appear to be 100. This provides empirical evidence for the change of the default from 10 to 100 estimators in version 0.22 of scikit-learn.
The Importance of a Good Benchmarking Set
Finally, we found that even though the OpenML-CC18 benchmark set is conceived to be more challenging, some datasets were still too easy. Therefore, tuning the algorithm had little effect on these tasks, so they were removed from the results. We are working on further curating our benchmark set of datasets to be more challenging.