





Navigating the labyrinth of modern business data is no small feat. Whether you're a customer service guru or a legal expert, you're all too familiar with the intricate (and often tedious) dance of sifting through endless documents to extract just the right information. And let's not even talk about stitching that data into a coherent, defensible narrative. But what if there was a smarter, more efficient way to maneuver through this maze? Enter Large Language Models (LLMs). They promise a lot, but can they really deliver when the terrain gets tricky? Let's explore the potential and pitfalls of using these language powerhouses in your data-driven world.
The Entrance: LLMs and Prompt Engineering as Your Starting Gear for Maze Navigation
Think of LLMs like ChatGPT as your Level 1 tool in navigating the data maze — a Swiss Army knife, if you will: fluent in multiple languages, packed with expertise across a vast array of topics, and deeply knowledgeable about almost all publicly available information. Whether you need quick explanations on quantum physics, a summary of a Shakespearean play, or assistance in crafting compelling storytelling for your brand, this is your versatile assistant, capable of answering a diverse set of questions with skill and ease.
But here's the catch: As pre-trained models, they have limits. While skilled at discussing history, literature, science, etc. based on their broad training, they lack knowledge of recent events, emerging trends, and undisclosed details. They cannot access your organization's private documents and data or tailor their answers to your industry's unique context. And in their desire to assist, LLMs can sometimes offer answers that seem plausible but are, in fact, hallucinations — convincing statements not backed by data. This is a significant caveat when accurate and credible information isn’t just a good-to-have, but a must-have. In your data-driven role, you often need specific, timely insights you can completely trust — not just plausible responses.
To overcome these limitations, you can employ prompt engineering, which involves crafting more complex prompts and incorporating relevant industry documents and data. However, this process requires careful selection of pertinent information within the vast sea of available data and can sometimes result in lengthy prompts. Nevertheless, this approach significantly enhances your ability to obtain precise answers tailored to your unique context.
While LLMs and prompt engineering provide an excellent starting point, the twists and turns of the maze you're navigating requires specialized equipment attuned to your business environment. To reach accurate answers, it's time to level up. The good news? Advanced solutions are emerging to take you further on your journey.
The Knowledge Forest: RAG Lights the Way
If you’re sitting on a goldmine of text documents — be it contracts, user guides, or endless PDFs — there's a compass to guide you through the maze: Retrieval Augmented Generation, or RAG for short.
Imagine your organization's documents are like a vast library. In this scenario, RAG acts as an ultra-efficient librarian: You ask a question, and RAG identifies the most relevant sections from various documents. These handpicked pieces are then coupled with your query and given to an LLM, which crafts an answer directly based on the information found in your documents. That's RAG in a nutshell.

Interested in the nuts and bolts? Check out this in-depth article we wrote on the topic.
First, it chunks your documents into bite-sized pieces, transforms them into vectors, and stores them in a cozy little place called a vector store. When you throw a question into the ring, RAG acts like your very own librarian. It scans the vector store to find the vectors — essentially the document chunks — that are closest to your query. These are then paired with your question and fed to an LLM like ChatGPT, which then crafts an answer directly sourced from your documents.
If you're wondering how to implement all of this without getting tangled in technicalities, Dataiku is rolling out a set of components that integrate this RAG technique right into your workflow. The visual embed recipe comes with a document parser and vector store baked in, and Dataiku even provides a template for an intuitive web app interface where you can simply ask your questions in natural language to instantly generate answers sourced from your documents.
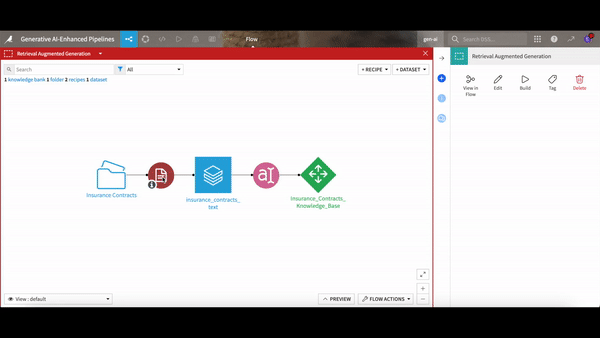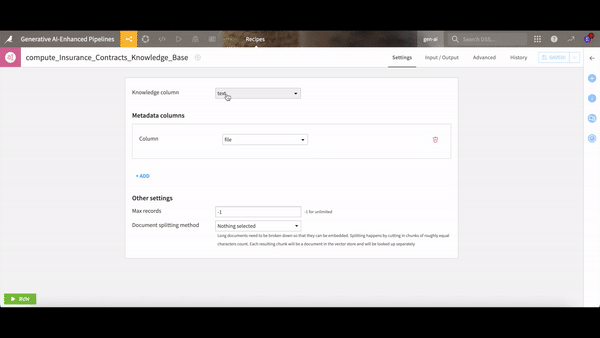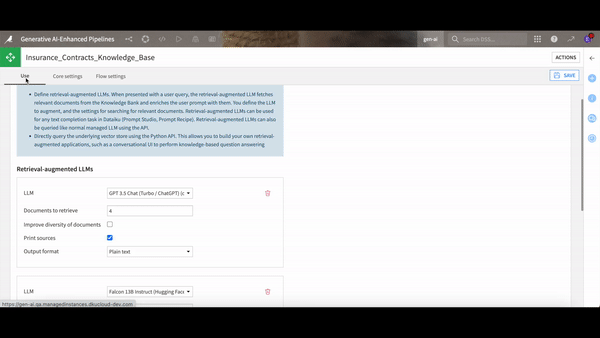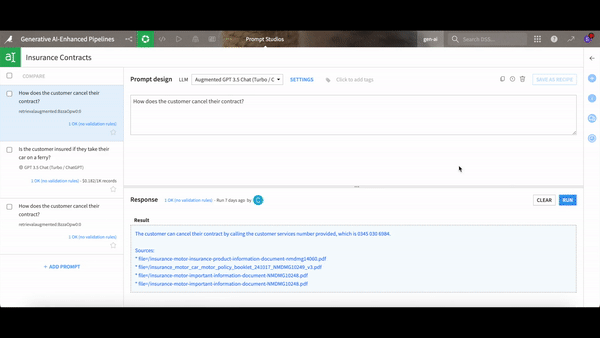
Dataiku’s built-in components extract the text from your documents, vectorize and store the information, and use it to enrich a foundational LLM.
Now picture this frustrating scenario: You're geared up, eager to unleash RAG on your data, only to realize you're not working with text documents but with datasets that span millions of rows. Why won't RAG work here? Because embedding tables as vectors isn't exactly its forte. It's time to uncover the maze's secret passageways. Let's delve into a technique called “Instruction-Driven Query Execution” that takes you beyond RAG's limitations and allows you to not only integrate LLMs with your tabular data, but also generate charts and dashboards to illuminate your path.
The Labyrinth: Tackling Advanced Challenges With Instruction-Driven Commands
As you navigate datasets rather than documents, you need a different compass to guide you. Enter instruction-driven querying.
The main idea is simple: You provide the LLM with your dataset's schema — think column names, types, and descriptions — and then specifically ask it to generate executable instructions for your query. These aren’t just any instructions; they're typically in Python or SQL, designed to run locally to pull the exact insights you're after. Just describe the information you seek in natural language, and the LLM crafts the exact code to produce charts, metrics, and visualizations attuned to your data. No coding needed from you — the LLM becomes the programmer, statistician, and data scientist all in one.
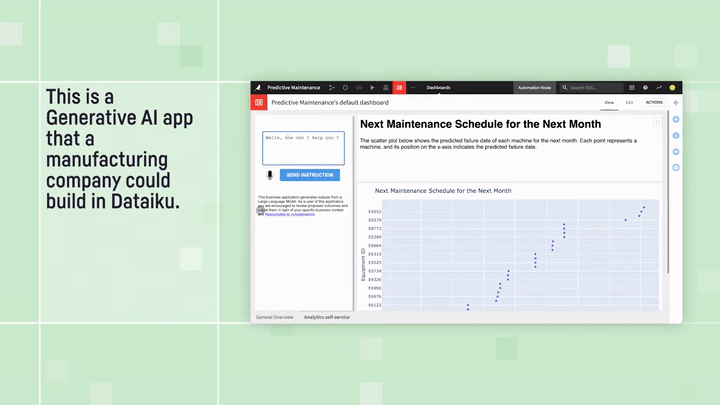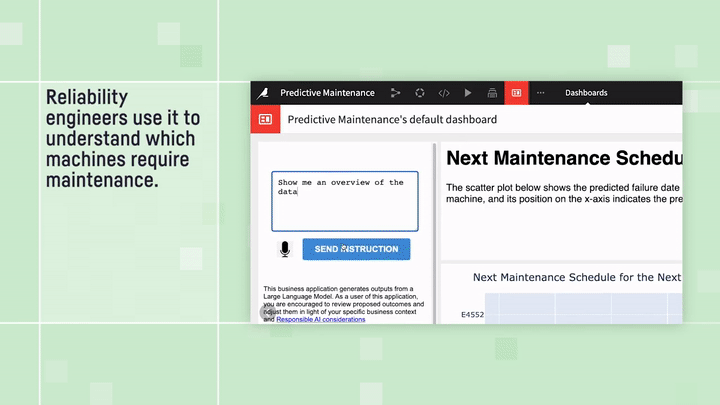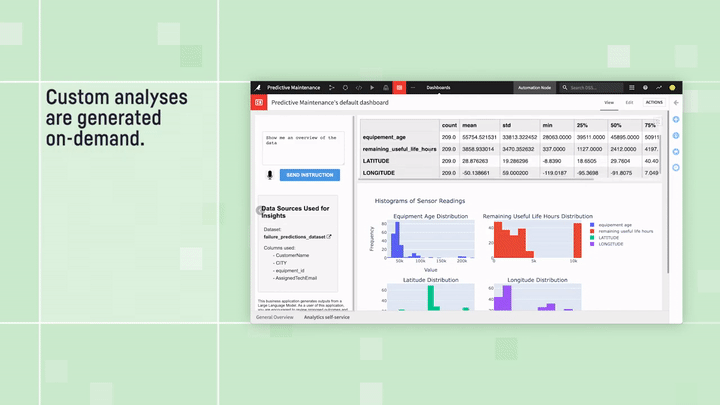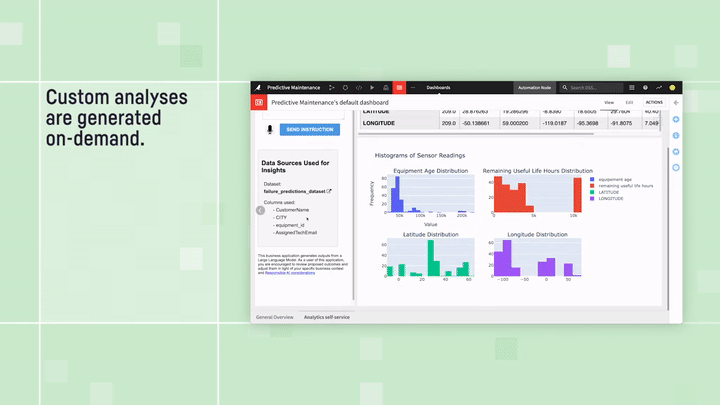
Predictive Maintenance Analysis: “text to dashboard” example
Safety first, of course. Dataiku ensures a secure experience, offering code execution that scales across various infrastructures and Python APIs to give you seamless access to datasets, models, recipes, and dashboards. Plus, all code is executed under profiles with controlled security measures, ensuring no accidental data mishaps.
And if your data is a bit more free-form — say, a collection of customer reviews — you're not out of luck. You can employ "structure" patterns to turn that unstructured text into a neat dataset. This allows you to take advantage of the Instruction-Driven Query Execution method, after your data has been classified, tagged, or organized.
Want to dive deeper into that? Check out our in-depth article on using LLMs at scale on your unstructured data.
Customer Review Analyzer: text structuring example
You've upgraded your toolkit with RAG and instruction-driven queries, but the winding maze ahead contains a mix of documents, datasets, and other challenges requiring a fusion of tools. The next level is integrating these into a custom-designed intelligent guide who knows when and how to apply each tool to illuminate the way.
The Inner Sanctum: Master Agents That Unleash Full Maze Potential
The winding maze stretches onward, filled with a myriad of twists, turns, and mixed data types. Documents, datasets, websites: You need a guide capable of dynamically selecting the right tool for each challenge. Enter AI agents — your custom-designed master orchestrator.
Much like a knowledgeable explorer, AI agents determine the optimal approach for a given situation by combining reasoning with action. Need to answer a question using internal documents and a dataset? The agent dispatches a RAG-based tool to quickly retrieve relevant texts and calls on instruction-driven queries to generate custom analytics code. And when facing an unfamiliar challenge, the agent can iteratively try combinations of tools, expanding its capabilities over time.
Dataiku offers a complete set of capabilities to leverage emerging frameworks such as ReAct and LangChain. Take a look at our LLM Starter Kit to see examples and start building advanced LLM chains.
To create your intelligent guide, AI frameworks like ReAct allow combining reasoning with action. The AI agent first reasons about the best approach, like using RAG for documents or query generation for structured data. It then takes that action and observes the result. By iterating between planning and doing, the agent can dynamically select and orchestrate the right tools for each maze challenge. What's more, you can easily construct custom tools for your agent to leverage, be it a proprietary data parser or internal API wrapper.
The Elephant in the Maze: Fine-Tuning an LLM on Your Data
As you stand on the edge of the data maze, you might think that fine-tuning an LLM on your organization's internal documents is the obvious next step. After all, it sounds like the holy grail for those familiar with traditional models. But be cautious — this route comes with its share of challenges.
Firstly, fine-tuning is a resource-heavy endeavor. It’s not just about the computational costs but also about the time and expertise needed to set up a balanced training dataset. Plus, the model will require frequent updates as new documents or changes roll in.
Secondly, fine-tuning is a double-edged sword when it comes to learning. Go too far, and the model might forget its general knowledge, becoming overly specialized in your industry's jargon. The balance between retaining worldly wisdom and acquiring the specifics of your documents is hard to strike.
Lastly, even with a fine-tuned model, you'll still need to verify the information it provides. Unlike RAG, which cites its sources, a fine-tuned model leaves you to do the homework of ensuring its answers aren't hallucinations.
That said, fine-tuning isn’t without its merits. It can be an effective approach for specific needs, like teaching the model a new style of writing or enabling it to better understand domain-specific terminology, jargon, and context. For this reason, Dataiku is developing additional components to simplify the process of fine-tuning LLMs, whether open-source local models or LLM API services, to suit your particular purposes.
The Path Forward: Assembling the Right Toolkit
In the complex world of modern data, the journey is less about following a single, straight path and more about navigating a diverse terrain. No single tool can conquer every challenge; instead, we need a versatile toolkit where various instruments work in concert, each offering its unique strengths when faced with different data landscapes.
As we forge ahead in this pioneering work, we must also cultivate Responsible AI practices, taking care to audit for biases, ensure transparency, and firmly establish human oversight. By integrating the right tools and grounded principles, we can reshape how knowledge is synthesized across data sources to deliver ethical, consistent and auditable insights. The path forward holds endless potential, but it requires adopting a nuanced toolkit coupled with Responsible AI values to guide us.
In the grand scheme of things, we are but explorers in the vast expanse of the data universe. But equipped with a robust toolkit, a spirit of innovation, and a commitment to Responsible AI, we're more than ready to navigate the path ahead. The journey continues, and we're excited to see where it leads.