




{kind=link}
Natural language processing (NLP) is all the rage right now. Once a relatively niche topic, in the past few years landmark new models and applications have brought NLP to the center stage of real-world enterprise data science and AI.

NLP Basics
NLP is a branch of machine learning and AI which deals with human language, and more specifically with bridging the gap between human communication and computer understanding. NLP sounds like a very niche thing, but it’s actually incredibly prevalent. You’ve probably encountered an NLP system in your day-to-day life without realizing it.
Some common examples of NLP use cases are:
- Question answering (search engines)
- Speech recognition (Siri, Alexa)
- Machine translation: translating from one language to another (Google Translate)
- Information extraction: pulling relevant details from unstructured and/or structured data (like important info from health records, relevant news that could impact a trade for a trading algorithm, etc.)
- Sentiment analysis: detecting the attitude (positive, negative, neutral) of a piece of text (used by businesses on their social media comments or for customer service, etc.)
How NLP Works
Here are the NLP basics in three easy-to-follow steps:
1. Cleaning and preprocessing the data. Before it can be processed by an algorithm, the textual data must be cleaned and annotated (labeled). Cleaning usually involves text normalization (converting to lowercase, removing punctuation, etc.), removing parts of speech without any inherent meaning (also called “stop words” — such as a, the, for, etc.), simplifying and converting words to their roots (through stemming or lemmatization — see below), and converting the text to smaller units called “tokens.”

Two common techniques for cleaning text by cutting off suffixes ("stemming") or stripping words to their root ("lemmatization")
2. Vectorization. After preprocessing, the text data is transformed into numerical data, since machine learning models can only handle numerical input. Traditionally, the two main vectorization techniques that have been used most widely are Count Vectorization and Term Frequency-Inverse Document Frequency (TF-IDF).
- Count vectorization involves counting the number of appearances of each word in a document or document section (i.e distinct text such as an article, book, a paragraph, etc.).
- The TF-IDF approach takes the logarithmic function of the size of the set of documents, and in how many documents a word appears. This is then multiplied by the term frequency to get a score. If the TF-IDF score is high, it means that it is good at discriminating between documents.
- A third technique called word embedding has nowadays become the dominant approach to vectorization. Embedding is a type of word representation that allows words with similar meaning to have a similar representation by mapping them to vectors of real numbers. Unlike older methods, word embeddings are able to represent implicit relationships between words that are useful when training on data that can benefit from contextual information.
The Future of NLP
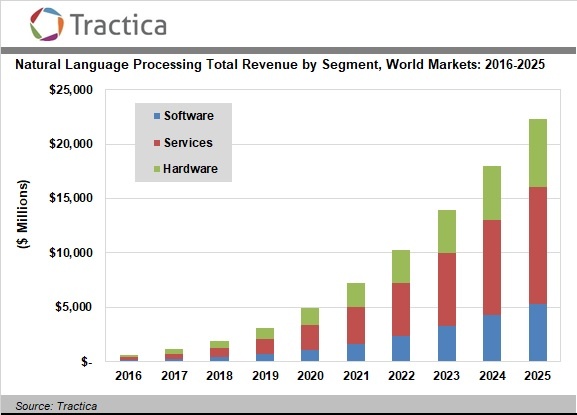
NLP is a quickly growing field (just look at machines like Alexa and Echo); a Tractica report predicts that NLP software solutions taking advantage of AI will see a market growth from $136 million in 2016 to $5.4 billion by 2025.
With landmark breakthroughs in NLP architecture such as the attention mechanisms, a new generation of NLP models — the so-called Transformers — has been born.
Given the rate of developments in NLP architecture that we’ve seen over the last few years, we can expect these breakthroughs to start moving from the research area into concrete business applications.