




{kind=link}
As deep reinforcement learning continues to become one of the most hyped strategies to achieve AGI (aka Artificial General Intelligence) more and more libraries are being developed. But choosing the best for your needs can be a daunting task.
In recent years, we’ve seen an acceleration of innovations in deep reinforcement learning. Examples include beating the champion of the game Go with AlphaGo in 2016, OpenAI and the PPO in 2017, the resurgence of curiosity-driven learning agents in 2018 with UberAI GoExplore and OpenAI RND, and finally, the OpenAI Five that beats the best Dota players in the world.
Consequently, a lot of deep reinforcement learning libraries have been developed and it can be hard to choose the best library. We had this problem at Dataiku when exploring deep reinforcement learning usage in recommendation systems. Therefore, we needed to benchmark the different libraries to compare them, and wanted to share our rankings.


Deep Reinforcement Learning Library Criteria
In order to choose the right deep reinforcement learning library, we defined some criteria that we found the most important:
- State of the art reinforcement learning algorithms implemented
- Good documentation/tutorials and examples
- Works in your own environment
- Legible code that’s easily modifiable
- Regular updates and an active community
- Tensorboard is supported
- Existence of other features (e.g., vectorized environments)
A vectorized environment is a method to do multiprocess training; instead of training our agent on one environment, we train it on n environments (because by using more parallel environments we allow our agent to experience many more situations than with one environment).
In the first part of this post, we’ll analyze each deep reinforcement learning library based on these criteria. Then, in a second part, we’ll build a simple agent that learns to walk using the two best libraries.

KerasRL (2.3/5)
KerasRL is a deep reinforcement library built with Keras.
State of the art RL methods ✅ ✅ ❌ ❌ ❌
- Deep Q Learning (DQN) and its improvements (Dueling, Double)
- Deep Deterministic Policy Gradient (DDPG)
- Continuous DQN (CDQN or NAF)
- Cross-Entropy Method (CEM)
- Deep SARSA
Missing two important agents: Actor Critic Methods (such as A2C and A3C) and Proximal Policy Optimization.
Easy to start ✅ ✅ ✅ ✅ ❌
The code is full of comments which helps you to understand even the most obscure functions.
The code is really easy to read and demonstrates a good separation between agents, policy, and memory. There is documentation, but it remains incomplete. The explanations of each definable parameter are missing.
Easy to plug your own environment ✅ ❌ ❌ ❌ ❌
This deep reinforcement learning library is not agnostic, it was made to work with OpenAI Gym. Consequently, you need to modify the agent if you want to use your own environment.
Easy to modify the agents ✅ ✅ ✅ ✅ ✅
Very easy; all you need to do is create a new agent following another implementation and then add it to rl.agents.
Community and updates ✅ ❌ ❌ ❌ ❌
The code seems not to be maintained anymore (the last update was four months ago and there are a lot of waiting PR).
Tensorboard support ❌ ❌ ❌ ❌ ❌
Tensorboard support is not implemented.
Other features ✅ ✅ ✅ ❌ ❌
Includes a vectorized environment system.
KerasRL Consensus: It could have been the best RL library with Keras thanks to a very good set of implementations. Unfortunately, because of a lack of updates, new architectures, and visualization tools, you should definitely use another deep reinforcement learning library.
Tensorforce (4.1/5)

Tensorforce is a deep reinforcement learning framework based on Tensorflow. It’s a modular component-based designed library that can be used for applications in both research and industry.
Due to the separation of the reinforcement learning algorithm and the application (thus making it agnostic to the type of structure of inputs and outputs and interaction with the application environment), this deep reinforcement learning library has a big potential to be one of the best. But because they’re currently working on a major revamp, we need to wait and see.
State of the art RL methods ✅ ✅ ✅ ✅ ❌
- Deep Q Learning (DQN) and its improvements (Dueling, Double)
- Vanilla Policy Gradient (PG)
- Continuous DQN (CDQN or NAF)
- Actor critic (A2C, A3C)
- Trust Region Policy Optimization (TRPO)
- Proximal Policy Optimization (PPO)
This library misses the Soft Actor Critic implementation (SAC)
Easy to start ✅ ✅ ✅ ❌ ❌
Easy to start using simple examples. There is documentation, but it’s incomplete, most of algorithms are not detailed in it.
Easy to plug into your own environment ✅ ✅ ✅ ✅ ✅
Tensorforce provides documentation to help you plug into your own environment. Many environments are already present (OpenAI gym, OpenAI retro, DeepMind Lab, etc).
Easy to understand the code and modify it ✅ ✅ ✅ ✅ ❌
Because of the modular design, each part of the architecture is distinct (network, model, runner, etc). You can also easily modify your network by modifying network_spec. However, the code lacks comments.
Community and updates ✅ ✅ ✅ ❌ ❌
Currently, the team is working on a major revision of the framework (non-stable). There is a good community (2303 stars and 47 contributors)
Tensorboard support ✅ ✅ ✅ ✅ ✅
Tensorboard support is implemented.
OpenAI Baselines (2.2/5)

OpenAI baselines contain one of the best implementations of RL agents with Tensorflow. But due to a lack of documentation or commented code, the difficulty to modify the agents, or add our own environments we decided to not use this version. We later found that there is a better fork called Stable Baselines.
OpenAI baselines is a very powerful library, but unusable for your own needs. It’s more like a perfect black box if you want to rapidly test with OpenAI gym, retro environments.
State of the art RL methods ✅ ✅ ✅ ✅ ❌
- A2C
- ACER
- ACKTR
- DDPG
- DQN
- GAIL
- HER
- PPO
- TRPO
OpenAI baselines does not contain their latest innovations such as the RND (Random Network distillation) agent.
Easy to start ✅ ✅ ❌ ❌ ❌
To start, use the Python command and the helper that defines all the parameter we can specify.
python -m baselines.run — alg=ppo2 — env=BipedalWalker-v2 — num_timesteps=2500 — num_env=1 — save_path=./models/bipedalwalker — save_video_interval=100
However, because of the lack of documentation, getting started can be tricky.
Easy to plug your own environment ✅ ❌ ❌ ❌ ❌
Because of the lack of documentation, implementing your own environment can be very challenging.
Easy to understand the code and modify it ✅ ❌ ❌ ❌ ❌
The lack of documentation and useful comments makes modification really difficult.
Community and updates ✅ ✅ ✅ ❌ ❌
There are good updates and continued development, but it’s missing many OpenAI papers (such as RND). There is also a good community (7565 stars and 99 contributors).
Tensorboard support ✅ ❌ ❌ ❌ ❌
Stable Baselines (4.6/5)
Stable Baselines is a big improvement upon OpenAI Baselines, featuring a unified structure for all algorithms (means that you can train a2c by calling a2c.train), a visualization tool, a unified structure for the algorithms and excellent documentation.
Moreover, they created rl baselines zoo, an amazing collection that contains 100+ trained agents
Stable Baselines was created at INRIA/ENSTA ParisTech, but now is maintained by four people, mostly PhD students.
State of the art RL methods ✅ ✅ ✅ ✅ ✅
- A2C
- ACER
- ACKTR
- DDPG
- DQN (both include dueling, double and prioritized experience replay)
- GAIL
- HER
- PPO
- TRPO
- SAC
Easy to start ✅ ✅ ✅ ✅ ✅
Easy to start an agent with 3 lines of code.
Edit: Now it’s only 2 !
from stable_baselines import PPO2
model = PPO2('MlpPolicy', 'CartPole-v1').learn(10000)
There is excellent documentation well detailed for each agent.
Easy to plug your own environment ✅ ✅ ✅ ❌ ❌
They provide good documentation about how to plug into your custom environment, however, you need to do it using Gym.
Easy to understand the code and modify it ✅ ✅ ✅ ❌ ❌
Because they are based on Baselines, modifying the code can be tricky. But because they provide a lot of useful comments in the code and awesome documentation, the modification is less complex than with OpenAI Baselines.
Community and updates ✅ ✅ ✅ ✅ ✅
There is a good community and the deep reinforcement learning library is constantly updated.
Tensorboard support ✅ ✅ ✅ ✅ ✅
Tensorboard support is implemented.
Other features (vec env…) ✅ ✅ ✅ ✅ ✅
- Custom environments
- Custom policies
- Common interface
- Ipython / Notebook friendly
- PEP8 code style
- Custom callback
- RL-baselines Zoo (contains a lot of trained agents)
TF Agents (4.3/5)
TF Agents is the newest kid on the deep reinforcement learning block. It’s a modular library launched during the last Tensorflow Dev Summit and build with Tensorflow 2.0 (though you can use it with Tensorflow 1.4.x versions).
This is a promising library because of the quality of its implementations. However, because this library is new, there are still some drawbacks such as the lack of documentation (even if there is a series of good tutorials).
State of the art RL methods ✅ ✅ ✅ ✅ ✅
- DQN
- DDQN
- DDPG
- TD3
- REINFORCE
- PPO
- SAC
Easy to start ✅ ✅ ✅ ❌ ❌
They created a series of tutorials that help you to create your agents. However, there is a lack of documentation.
Easy to plug our own environment ✅ ✅ ✅ ❌ ❌
Since the library is agnostic, it’s relatively easy to add your own environment.
Nonetheless, again, the lack of documentation is a predicament.
Easy to understand the code and modify it ✅ ✅ ✅ ✅ ❌
The implementations are really clean and the code is well commented.
Community and updates ✅ ✅ ✅ ✅ ✅
A growing community and a lot of updates.
Tensorboard support ✅ ✅ ✅ ✅ ✅
Part 2: Implement an Agent That Learns to Walk With BipedalWalker-v2
Based on our subjective benchmark, we will try to implement an agent that learns to walk (BipedalWalker) using the 2 top libraries TF-Agents and Stable Baselines.
BipedalWalker-v2 With TF Agents
BipedalWalker-v2 With Stable Baselines
Implementing an agent that learns to walk is simple with Stable Baselines:
What’s fantastic about working with Stable baselines is that its documentation is robust for when you want to go deeper and tune more hyperparameters.
stable_baselines.ppo2.PPO2(policy, env, gamma=0.99, n_steps=128, ent_coef=0.01, learning_rate=0.00025, vf_coef=0.5, max_grad_norm=0.5, lam=0.95, nminibatches=4, noptepochs=4, cliprange=0.2, verbose=0, tensorboard_log=None, _init_setup_model=True, policy_kwargs=None, full_tensorboard_log=False)

Then, you can visualize the results during the training by launching Tensorboard.
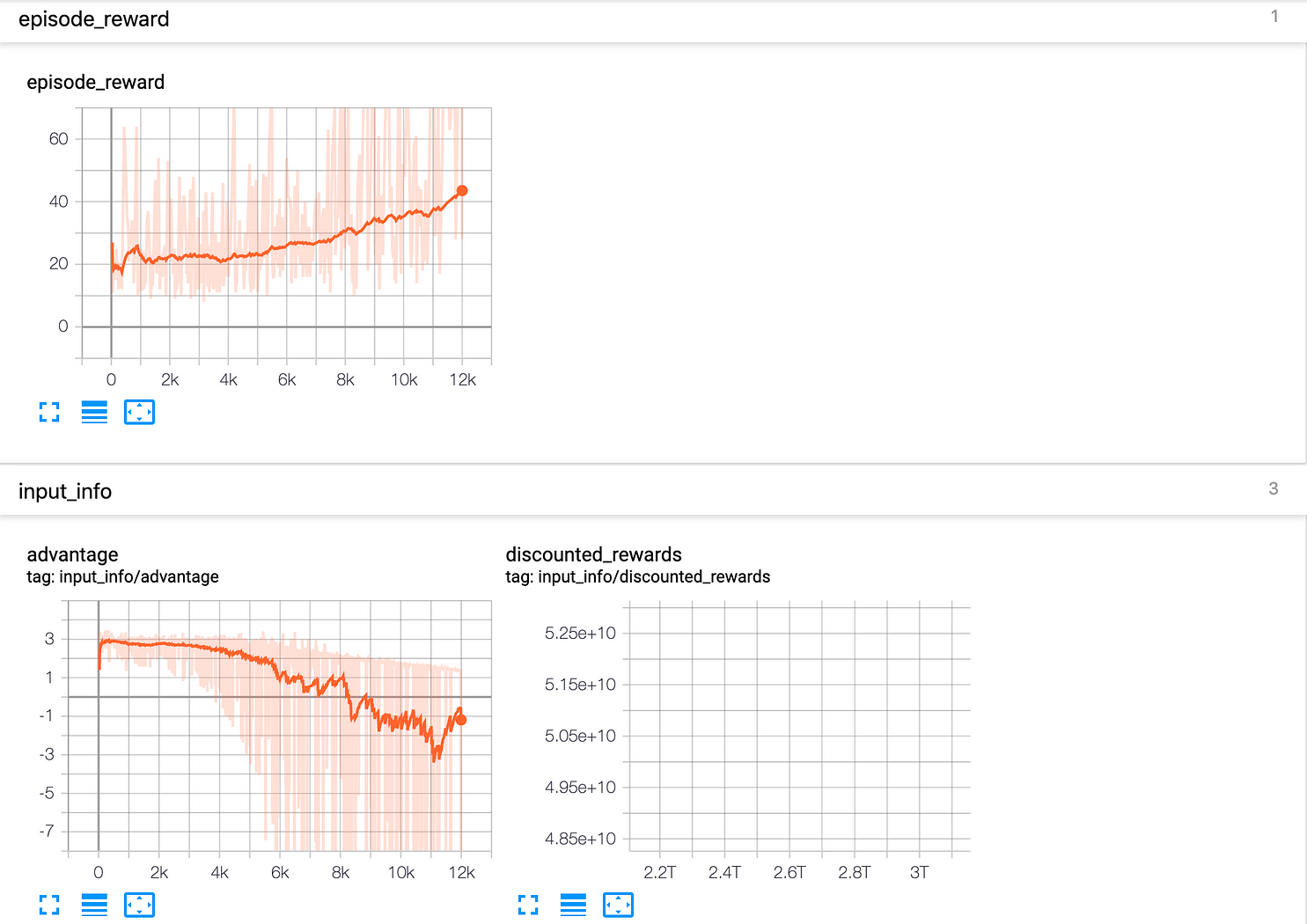
Bonus, by using RL-Benchmark Zoo, you can use a pre-trained agent in a variety of environments.
python enjoy.py — algo ppo2 — env BipedalWalker-v2 — folder trained_agents/ -n 5000
To conclude, Stable Baselines and TF-Agents are the best deep reinforcement learning libraries you can use. At Dataiku, for now, we decided to use TF Agents because of the modularity of the code and the fact that we can simply modify the models.