




{kind=link}
Attention first originated in translation systems as a way to focus on parts of the input sentence, when generating words of the translated sentence. A typical reference one can go through is Decoding NLP Attention Mechanisms.
This blog post will shed light on an emerging extension of the attention mechanism which combines both text data and image data. Two specific architectures of such models answering general tasks will be exposed.
As Anderson & Co state in their paper “Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering”:
Problems combining image and language understanding such as image captioning and visual question answering (VQA) continue to inspire considerable research at the boundary of computer vision and natural language processing.
Use Case: Visual Question Answering
Visual Question Answering (VQA) is a popular application which commonly leverages attention on both text and image data. It is the task by which a model generates an answer based on an input question and an input image. This will be the use case we refer to throughout this blog post.
Illustrations of VQA-related applications involve a variety of rising areas, some examples of which are:
- Medical imagery: Recent research exposed VQA possibilities on decision support through enhanced diagnosis and medical image analysis.
- Video surveillance: Real-time surveillance monitoring is challenged by the integration of automatic responses to an agent’s questions in order to better react to possible threats.
- Assistance: A first step has been made in order to assist visually impaired people understand their surroundings. A new specialized dataset has been introduced in order to encourage research towards building a model which can answer questions from visually impaired individuals.
VQA is a challenging task, as it involves capturing the high-level interactions between a question and an image in order to predict an accurate answer.
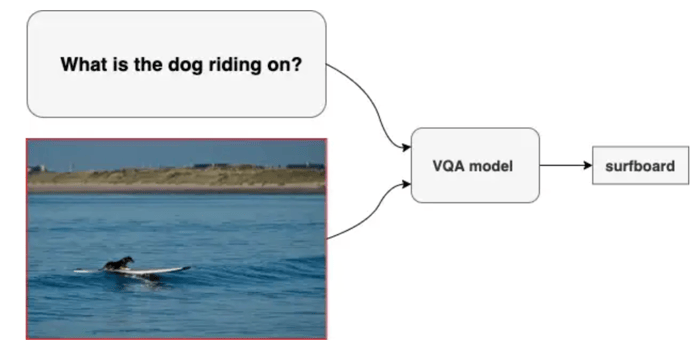
Example from VQA dataset
To successfully perform this task, one natural idea is to guide the attention of the model around the most informative regions of the image based on the asked question. But let’s cross that bridge when we get to it.
In order to illustrate VQA in practice, we will rely on the popular VQA-v2 dataset which contains open-ended questions about images. These questions require an understanding of vision, language, and common sense knowledge to answer. It is based on the famous COCO dataset where questions and annotations are added on top. Thereby, more than 120,000 images can be employed to illustrate our topic. Each image comes in general with four questions and answers from annotators.
1. Paving the Way for the VQA Model
One common strategy to address this use case is to simplify the paradigm by viewing it as a multi-class classification, more specifically a K-class classification. Then the choice of K remains essential, it is common for the VQA-v2 dataset to set K equals 1,000. In that case, frequently represented answers are retained and unlikely answers are put aside.
Most strategies leverage a combination of relevant image regions and text features. Both components are the inputs to a VQA model, and their numerical representation is crucial as it heavily affects the results.
For now, we will assume that the regions have been extracted from the image, and will detail the methodologies in a later section (1.4 Feature Representation). Similarly, we will assume that the input question is represented with a numerical vector.
- Picture/image representation: pᵢ for i ∈ M, where M is the number of extracted regions, each pᵢ has the same fixed dimension (2,048, for example)
- Question/text representation: q the vector representing the question with a fixed dimension (512, for example)
Let us now reflect on how to combine these image and question representations in the model. This is where attention appears on the scene!
1.1 Attention Mechanism on Image and Text
When someone asks you a question on an image, your attention will naturally go to the parts of the image which are relevant in regards to the question. This is what the attention mechanism in a model does.
The aim of the attention mechanism is to put more weight on relevant regions of the image, depending on the question. In order to achieve this, the image needs to be split somehow in different regions (in the example below, the part could be: the dog, the surfboard, the ocean, the background, etc.).
This can be done through different techniques which will be explored later. So attention, in a simple way, can be nothing more than weighting each image feature in the context of the question.
 Example with attention from VQA dataset
Example with attention from VQA dataset
Let’s shatter how attention weights are calculated for each image pᵢ in regards of the question q. These weight values should reflect the extent to which an image region and the question are linked or similar. One classical method resembles Additive Attention, also called Bahdanau attention:
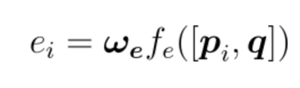
In practice, the function fₑ is implemented as a feed forward layer (FFL) which takes as input the concatenation of both representations to estimate their similarity. In addition, wₑ is learnable parameter.
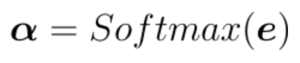
Afterwards, transforming these similarities into weights is a matter of normalization that can be easily performed with a softmax activation layer.
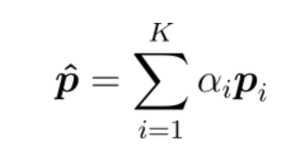
The final step is to apply these weights to the image region vectors, and the result is an attention-based representation of the input image. FFLs may be necessary to align the dimensions of each stage. The detailed architecture of attention is described in the following figure:
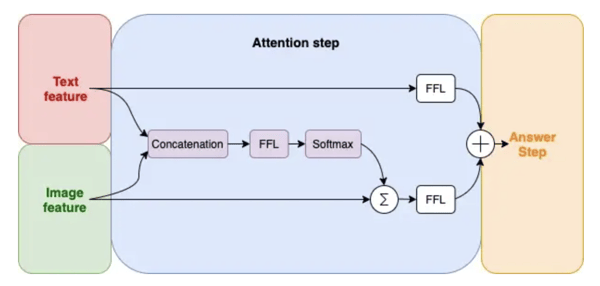 Detailed architecture of attention step
Detailed architecture of attention step
In practice, here is one implementation based on TensorFlow:
Once the attention mechanism is defined, don’t forget that it is only a piece of a whole neural network architecture to crunch VQA.
1.2 VQA Architecture
After reviewing the core idea of attention mechanism on image and text, we must define the representation of those elements. Since the main architecture of a VQA model will ingest the feature representation, it must be as meaningful as possible and performance may heavily depend on it.
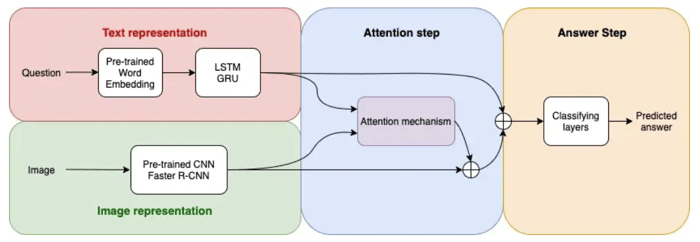 Architecture of an attention-based VQA modem
Architecture of an attention-based VQA modem
1.3 Answer Step
Before the final layers (multilayer perceptron, for example) produce the answer, one last task is to combine the question feature and the attention-based image feature. In order to accomplish that, straightforward options such as element-wise addition or product can be used. More sophisticated techniques have been developed such as multimodal attention fusion.
1.4 Feature Representation
After defining a first architecture to handle VQA models leveraging attention, feature representation must come to light.
We have to select a proper representation for the textual feature and once again it is ordinary to start from a pre-trained model. For instance, benefiting from a pre-trained embedding such as FastText, Word2vec, or GloVe is a first great idea to come up with embedded texts. On top of that, recurrent neural network like LSTM or GRU layers can transform the previous representation to a more information-focused one.
Then concerning the image feature, its representation can be the result of a spatial transformation through an appropriated CNN network. Training such a network from scratch is feasible but requires time and ressources. In that case, pre-trained CNN on popular reference datasets such as ResNet-50, MobileNet, VGG-16, trained on ImageNet are good candidates to produce informative image representations.
More advanced techniques from the field of object detection are the way to go in order to reach state-of-the art performances. These techniques aim at extracting multiple informative regions from a single image. As an example, the Faster R-CNN model draws bounding boxes on detected objects of the image. These techniques emphasize particularities of the image without leveraging any prior context from the question. This is referred to as bottom-up attention
Reaching this stage, you now know how to implement a simple attention-based architecture for VQA and it is not rocket science. In addition, many other researches have experimented advanced integrations of attentions. Let’s have an overview of a more state-of-the-art architecture: encoder-decoder.
2. Multimodal Encoder-Decoder Network
Before reading this section, prior knowledge on encoder-decoder models is mandatory. Thus, walking through this blog post about Transformer, which adopts an encoder-decoder architecture, is recommended.
Encoder-decoder, as a deep learning structure, relies on the mechanism of attention by weighting the significance of each input data. Once again, this technique was initially developed for NLP use cases but can be extended to VQA problems.
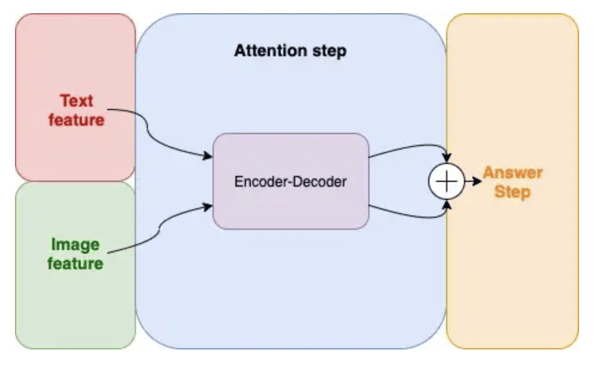
The good thing is, all other stages of the VQA may remain the same. Hence, the only modification we will discuss is focused on the attention strategy.
Encoder-decoder structure is divided into two parts, the first one is the encoder and the second one the decoder. Each part is based on a cascade of self-attention (SA) blocks and guided-attention (GA) blocks.
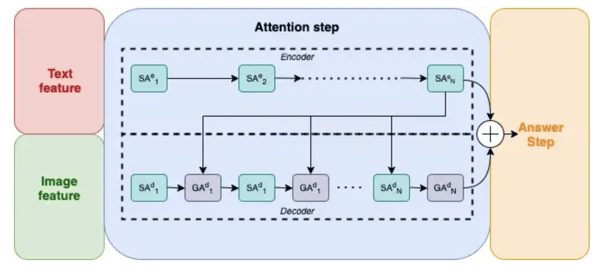
Encoder-decoder decomposition
The idea behind this structure is to firstly weight the relevance of each word within a question thanks to the self-attention mechanism. Then, the final encoded question is combined with the image feature through the guided attentions mechanism by alternating with self-attentions. Let’s now deep a little deeper into these two techniques.
2.1 Self-Attention & Guided Attention
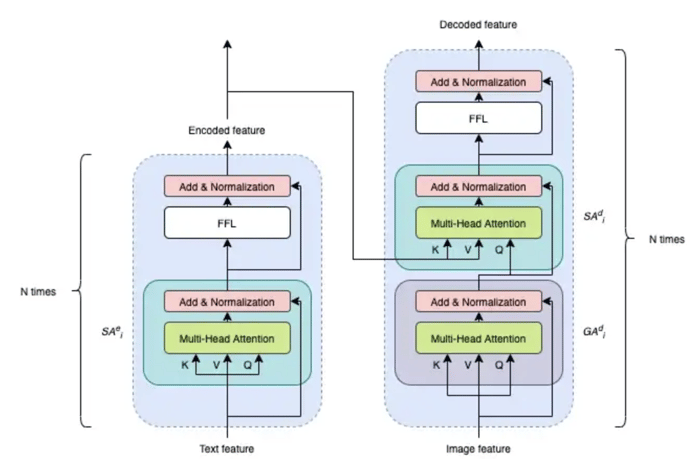 Encoder-decoder architecture
Encoder-decoder architecture
Multi-head attention is the core operation to put attention to the right information in SA and GA blocks. Composed of multiple of heads, each head is operating a scaled dot product to capture different attention on several relations. A head takes as inputs three features: the Key (K), Value (V) and Query (Q).
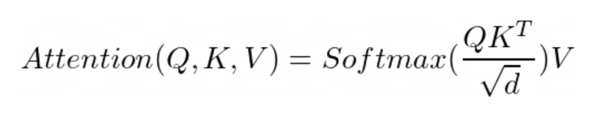
In the case of GA block, Key is associated to the question and the Query to the image representation. Both elements serve to compute the weights which will be apply to the Value, namely the image feature.
These components serve to compute the similarity between image and text representation before applying it to the image feature. It is similar to the first presented architecture on attention.
Attention weights are divided by the square root of d (commonly the dimension of the K) in order to stabilize the training. Each head then reuses this mechanism with projection matrices.
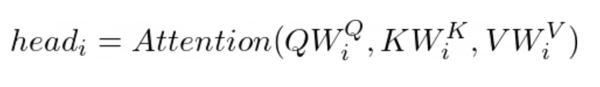
Multi-head attention simply consists of h parallel heads with a unique projection matrix.
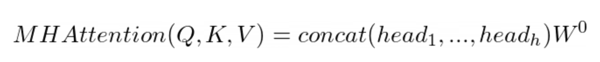
Concerning SA blocks, Key, Query, and Value all represent the same information to enhance. It is either the question in the encoder or the image in the decoder.
- SA block is the main component in the encoder. It aims at encoding the question in order to reflect each word of the question in relation to all other words
- In the decoder, SA block is firstly taking as inputs information related to the image regions. Then, alternating GA and SA blocks allow the network to focus on the relation between the relevant regions of an image conditionally to the encoded question.
Here is one example implementation based on TensorFlow where encoder and decoder only contains one block of attention but it can be easily extended to multiple blocks of attention layers:
So, this ends our overview concerning encoder-decoder architecture for VQA. After getting to the bottom of this neural network approach, the technique is now out in the open. It can be easily applied to a variety of use cases.
Conclusion
Throughout this blog post, we covered most of the essential concepts of the attention mechanism applied to the VQA use case. From a simple architecture to a deeper and more state-of-the-art one, nothing beats attention which contributes to reaching increasingly high performance in this field.