




In this article, which is a continuation of my three-part (1, 2) series on the topic, we will complete our journey to creating our data mesh, lifting those Dataiku-created data product services that we created earlier for exposing feature data and inference engines into a space where we can reliably discover those services, interact with, and choreograph them.
There has been a lot of ink spilled on what is and isn’t a data mesh and how an organization can build one. I’m not going to wade into that debate here, but I will call out that, from my understanding, a data mesh shares a number of principles with a microservices network (not the least of which is an architectural pattern). The important ones which Dataiku (and MuleSoft) can participate in is to allow organic, emergent, and self-service publication and consumption of data services. This allows a ubiquity and nimbleness of data in the organization, as compared to the heavily planned and slow-to-change data fabric of old. Some of the real challenges of allowing this sort of democratic data creation and consumption is that architects must ensure that these nodes in the data mesh are discoverable, easily consumable, composable, secure-by-design, monitorable, and scalable.
So You Want to Actually Use Your Data Mesh Services...
When, last we left our intrepid heroes, we had successfully pushed a number of these sorts of organic services into a Kubernetes (K8s) cluster where we can trust that they’re scalable and could interact with them from within the confines of that same K8s cluster, but that’s not where we want to leave it. We want to protect those services, publish them for discovery by my larger organization, and choreograph them into new and exciting mashups! All the promise of a data mesh, with all the security and operations robustness of a service mesh. Once again, I’m going to turn to a tool that I already know for this from my tenure at MuleSoft: the Anypoint Service Mesh (ASM), but the principles and many of the steps in this are applicable to any service mesh and API platform.
First, Some Housekeeping:
In order to expose these services to satisfy the needs for easy consumption, we need an intermediary to facilitate and control traffic to and from the services in the K8s cluster. For this, we’ll turn to Istio, as it’s a prerequisite to using the ASM, to both act as the controller and the gateway for our services.
Here, I’ll ssh into the Dataiku server I’ve been using all along, as it has already got all the K8s configurations and elements I need configured on the OS by the plugin, so let’s piggyback on that for our install. To configure the local environment to map my cluster to the local kubectl, I can use the AWS Command Line Interface to get a config:
aws eks update-kubeconfig --region region-code --name cluster-name

Now, as I allowed Dataiku to manage my cluster back in part 2 of this blog, I know it doesn’t have an external load balancer set up. We’ll need one to access the services from outside of the cluster and allow the service nodes to balance traffic. To install one, I follow these instructions from AWS to set up the policy which allows my cluster to create elastic load balancers, and install the controller for it into my cluster. (Note: Make sure your public subnets are tagged with kubernetes.io/role/elb = 1)
When I’m done I’ll have the following workloads in my cluster:
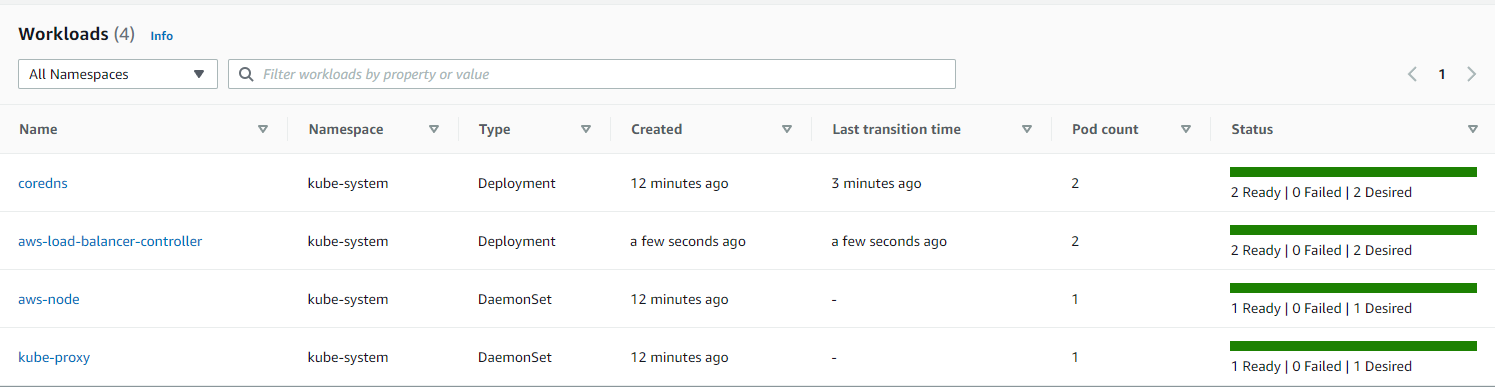
At this point, I can redeploy my API services from the last part, changing their service exposition to LoadBalancer to use that new cluster capability and see them from anywhere.

Redeploying the service gets me an externally-facing load balancer address which I can use to hit the service with clients and tools from outside of the cluster:

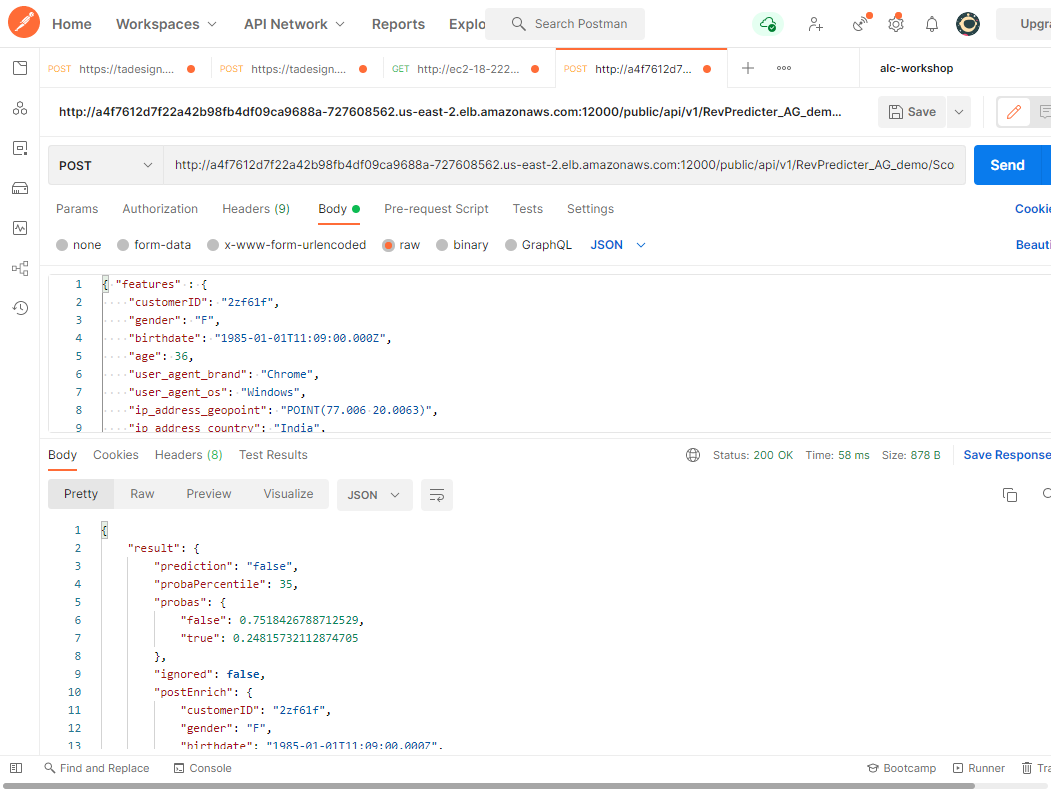
Ok, so that’s all well and good, but now I need to address the concerns of securitizing and monitoring these services. I’m especially going to want to manage access to these services if they’re going to face the internet. For that I have a relatively simple option directly in Dataiku which I'll start with while I try these out and choreograph them together into a new service!
Securing My Service:
From my API deployment, I’m going to create some keys that will be required to access the service:
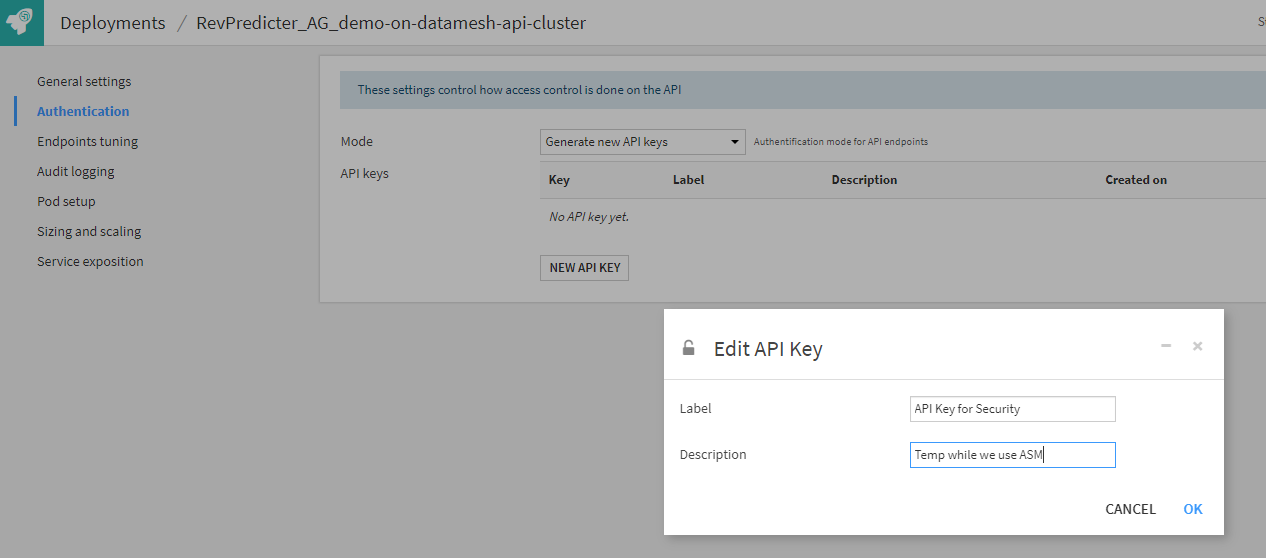
Clicking Save and update redeploys my service so that it now requires an API Key to access. To use this key, you can access the service with the generated API Key as the username in a Basic Auth scheme with no password:

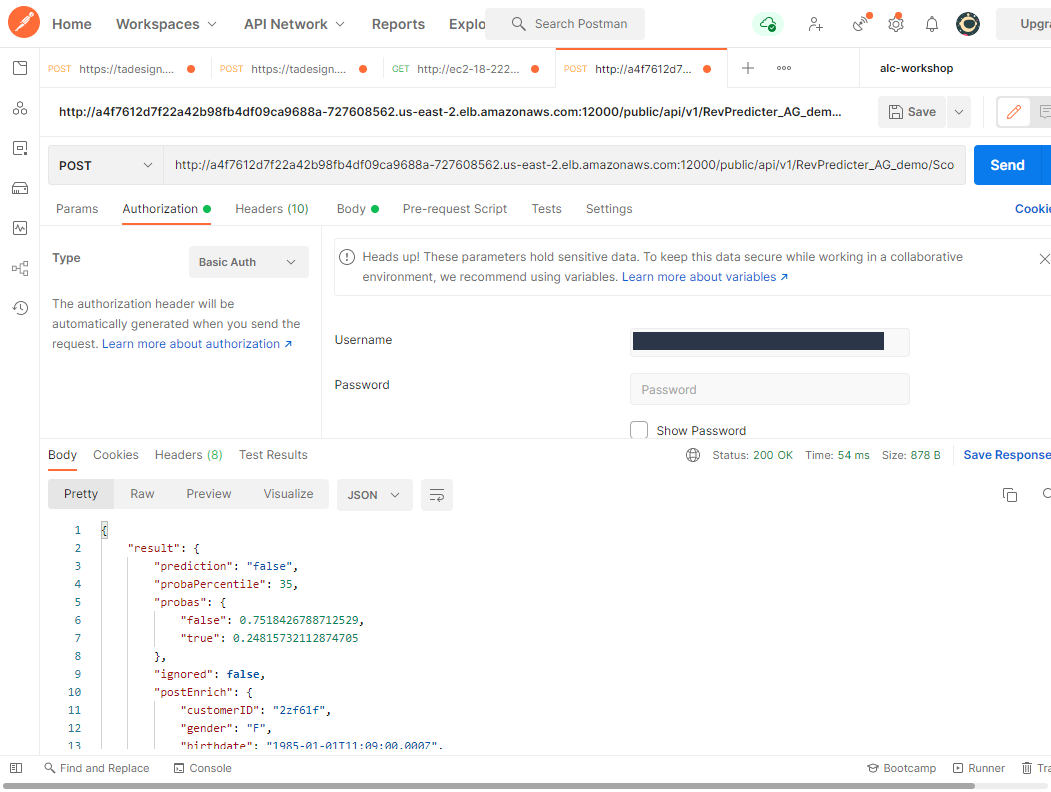
Now POST requests without the key will fail, but we can and should do better. Monitoring these services (and all the other services in the mesh) is critical, and a single pane of glass for all my services in the mesh is something we want to turn to an intermediary service mesh tool for. We’ll return to this later.
Extracting the Interface:
Now’s a good time to build our swagger API definitions. As these services are up and exposed to the internet, we can use SwaggerInspector to generate our interfaces and publish them in The Anypoint Exchange (see part 1 for a refresher on how to do this). When I’m done, I’ll have swagger for my two services published in my Anypoint Exchange. Now other members of my organization can find, experiment with, and use these services in their own tasks. We can now choreograph these services and others together into new and exciting usages!
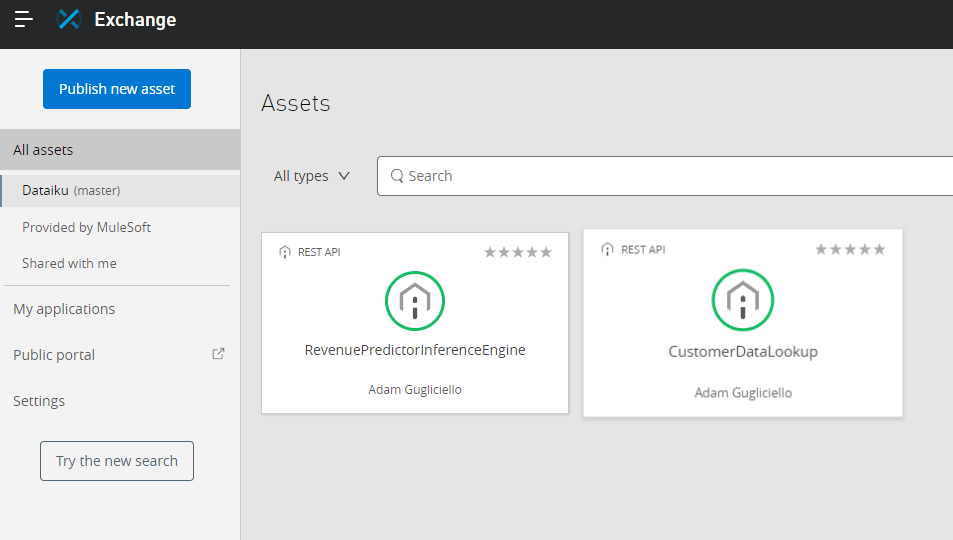
Calling the Dance:
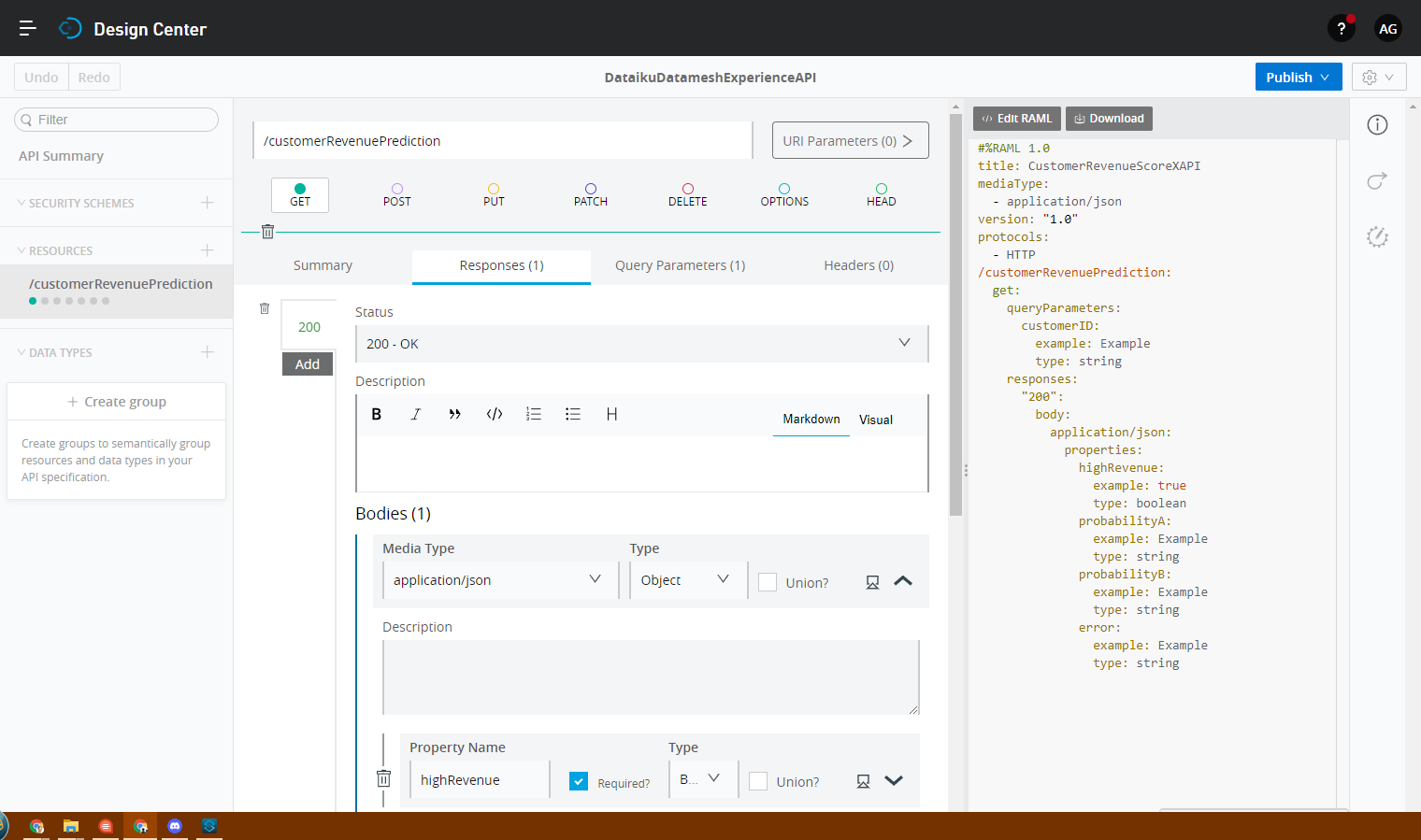
Good API practice calls for reducing the burden on the caller as much as possible, and MuleSoft recommends that you create layers of APIs to achieve this. I can design a much simpler Process API which takes customerID, looks up everything it needs, and returns a prediction from the inference engine:
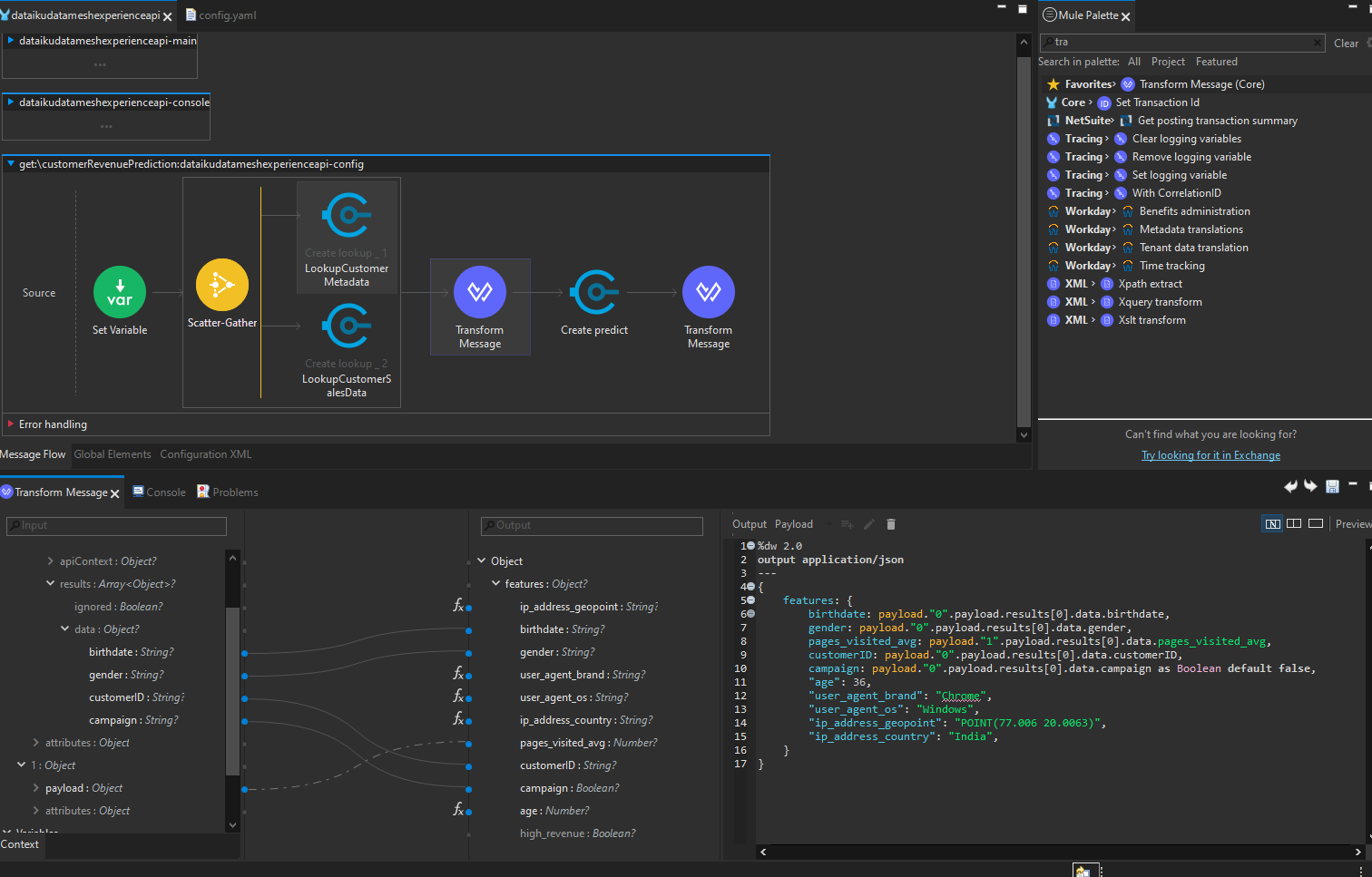
Implementing that API is a snap because I’ve documented and published the Dataiku-generated System APIs, now I can use MuleSoft’s Anypoint Studio to drag and drop the data elements from my feature-serving APIs and my inference engine together!
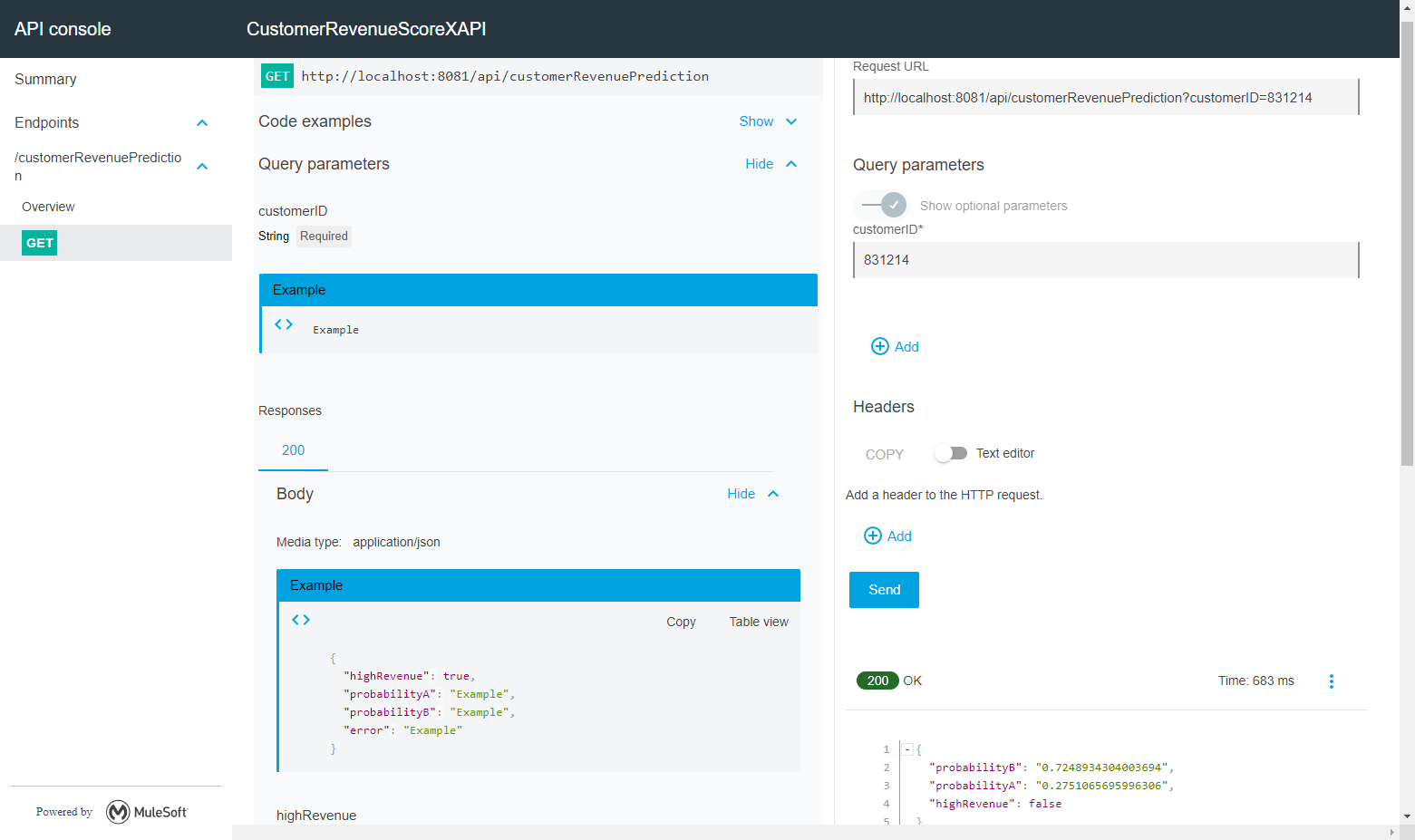
Deploying that service lets me choreograph all these services as well as any other services or SaaS platforms together into a new, easy-to-use mashup!
Here, we can have Dataiku provide the data and inference engine System APIs, as well as the K8s cluster management which allows us to lift data into the mesh. Together, these provide the AI intelligence to use all of your data, and MuleSoft provides choreography and a platform to discover all the services that one might want to mix and match together!
Securing and Monitoring the Mesh:
I could easily declare victory here, but I want to do one better and allow MuleSoft to gate and govern the services in my Dataiku-managed K8s cluster with their service mesh so I can apply fine-grained security policies and better understand how my services work together. To that effect, I need to add a few more things to my cluster:
I’ll download the latest version of Istio that is compatible with Anypoint Service Mesh to my machine:
curl -L https://istio.io/downloadIstio | ISTIO_VERSION=1.11.5 TARGET_ARCH=x86_64 sh -
Which unpacks it and is all ready to go for installing it into my cluster:
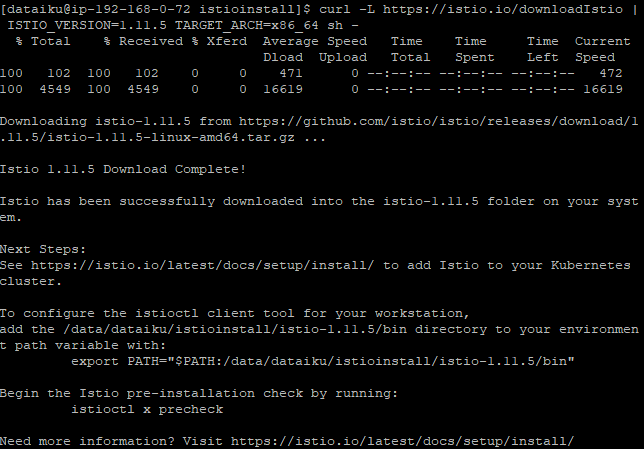
Then, we do the things they tell us to.
export PATH="$PATH:/data/dataiku/istioinstall/istio-1.11.5/bin"
istioctl x precheck
istioctl install

With that complete, we can mark the default namespace to include Istio sidecars. These sidecars get attached to the containers and allow the Istio to act as a proxy and inject functionality into the middle of that traffic, MuleSoft’s Anypoint Service Mesh uses this to attach access control policies to the traffic.
kubectl label namespace default istio-injection=enabled

When we update and redeploy our services, they will all get Istio sidecars automatically attached. Now, we can install the MuleSoft service mesh controllers, which will serve to gate and govern our services. And then, we’ll create an adapter which connects the Istio sidecars to my Anypoint Platform:
./asmctl adapter create --namespace=default --name=adapter --clientId=05b161b2da584822b470872e6bc1fb72 --clientSecret=038D03907e0848a58b2B1cba04d16B56 --size=small --replicas=1

Ok! With that little bit of plumbing complete, our K8s is now ready to take orders from Anypoint about how these services should be accessed and to measure and monitor them on our behalf. If we configure those APIs like we did back in part 1, we can now attach the services to the API definition, the main difference here being that when we create the API Management entry in the Anypoint platform, we’re going to choose the Service Mesh option.
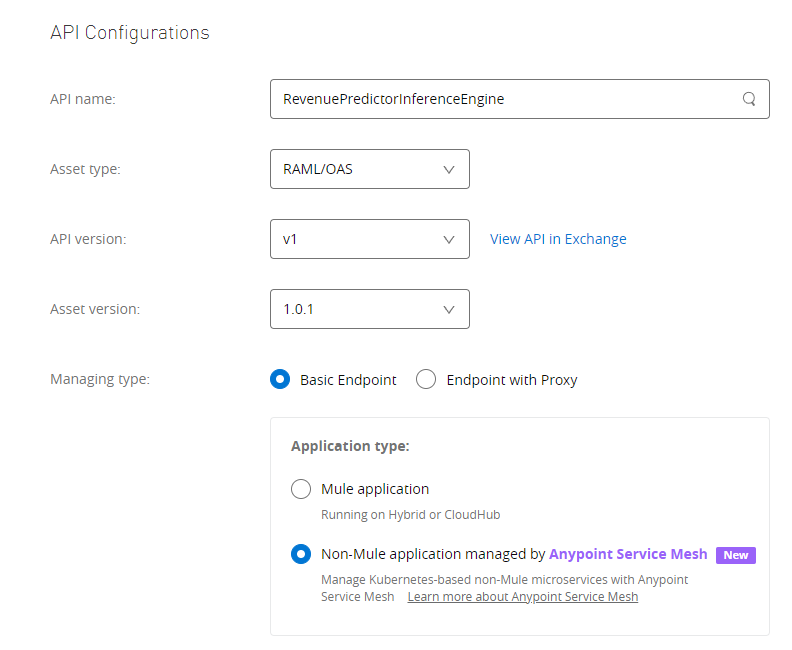
Once again, this lets us get the API ID we need to bind the services in our K8s to the platform for governance:

In a bit of preventive debugging, we’ll switch our services over to Arbitrary YAML service exposition, so that we can correctly name our ports in accordance with the Istio specification:

And we can now bind our service to the Anypoint Platform:
./asmctl adapter binding create \
> --name=revpredictbinding \
> --namespace=default \
> --adapter=adapter \
> --apiId=17595112 \
> --serviceName=revpredicter-ag-demo-on-datamesh-api-cluster

And after a short while, the API Management in Anypoint will show that the service is ready:
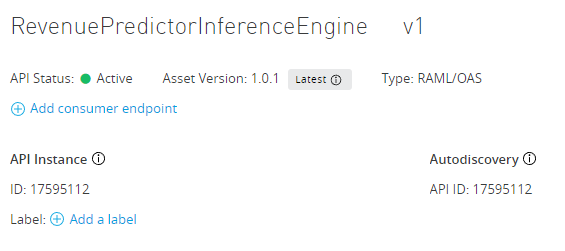
We can now apply rate limiting to it (or any other Anypoint Policy) to control access to these services! Additionally, all traffic to these services is now monitored and collected, errors and traffic patterns are available, and we can intelligently predict and manage scale for these services as they are consumed or sunset them as they fall out of favor.
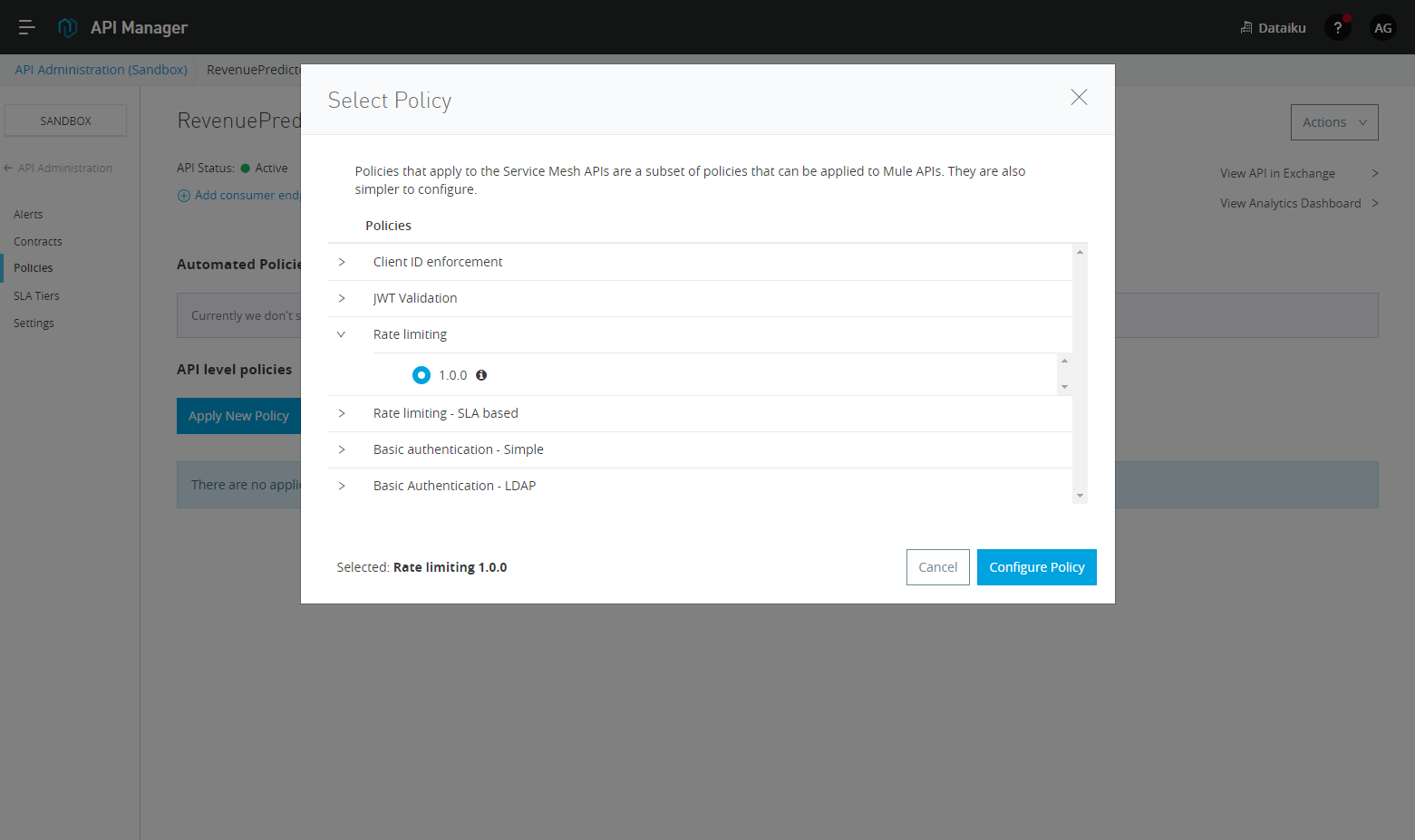
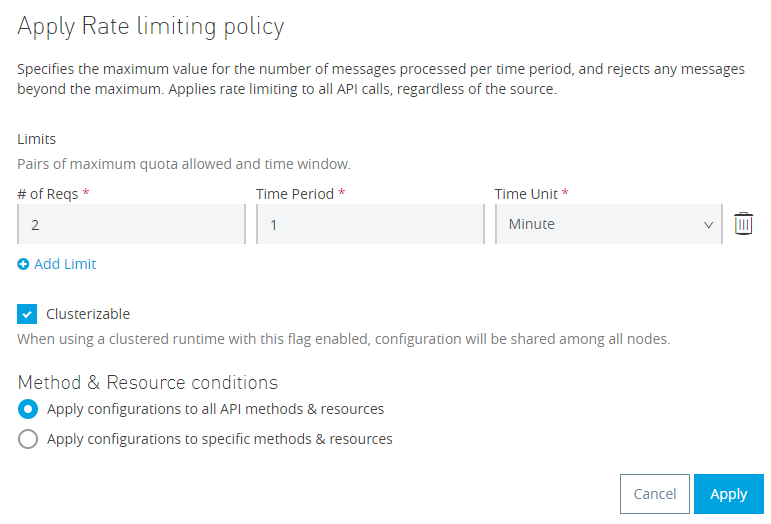
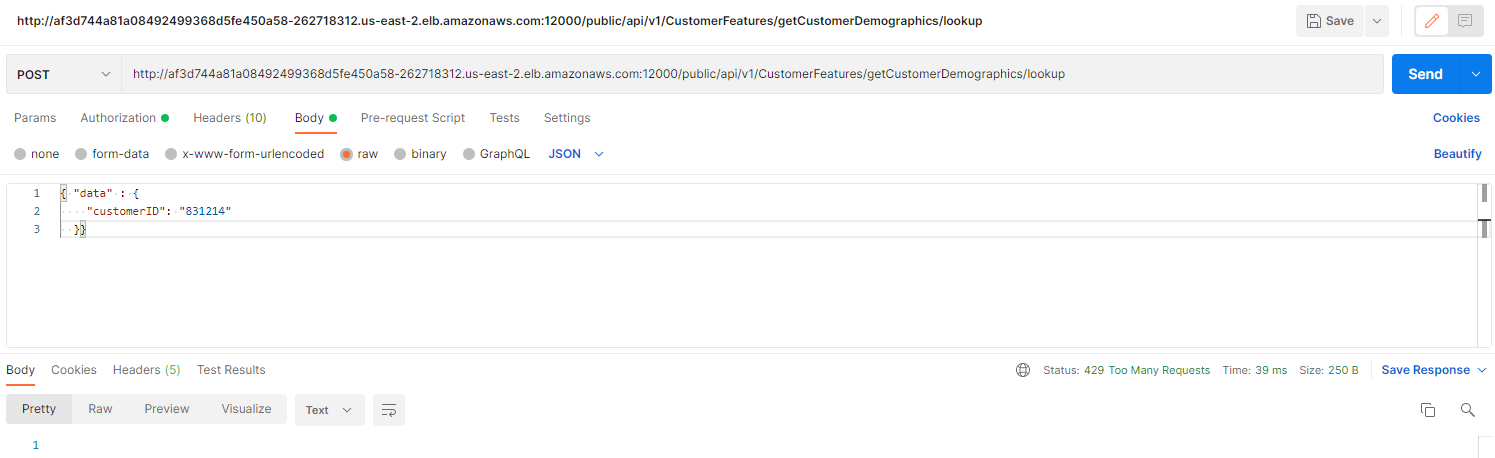
And if we hit it faster than our two times in a minute, we’ll get a response of: 429 Too Many Requests.
{kind=link}
Success! We have now exposed the data services and inference engines together to my data mesh, choreographed them into a new service for ease of consumption, and injected security, controls, and analytics such that we can feel confident about allowing these services to be used by our larger network. All of the principles applied here with MuleSoft on EKS are portable to whatever service mesh and API management tools and cloud compute vendor, but I leave adapting these as an exercise for the reader. Happy meshing!