




{kind=link}
This version of Technoslavia has been replaced with Technoslavia 2020 - check out the latest version!
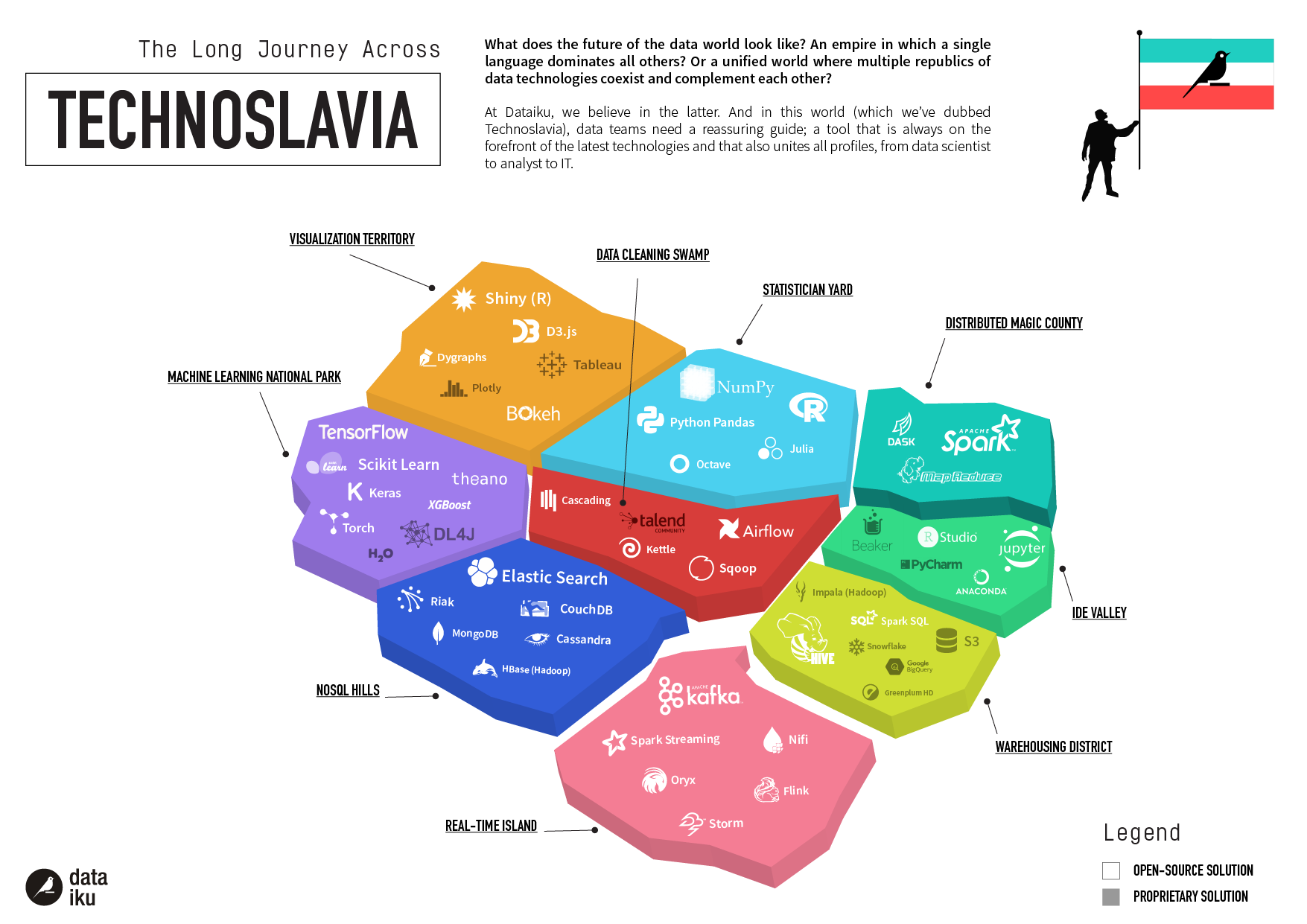
Open source has always been a part of the data science landscape (as we explored here in 2015 and here in 2017). And while every tool in Technoslavia has some free offerings, we’re taking this chance to highlight the dominating force of open source in the ecosystem.
We commissioned a report from 451 Research on the popularity of open source data science tools. They found that open source tools govern our Machine Learning National Park (and, side note: our Technoslavia predictions thus far have been pretty spot on).
We’ve added two (very different) players to Technoslavia following the 451 Report: Jupyter and NumPy.

Jupyter
If you combined your favorite text editor, Google Drive, and LaTeX, you’d get Jupyter. Originally known as IPython, the Jupyter Notebook is a smart online text editor that enables a single document or application to leverage text, equations, visualizations, and live code in dozens of languages. It is a versatile platform that enables collaboration between peers in almost every domain: from biology to machine learning.
The best aspects of Jupyter are its flexibility and usability. There are virtually no limits to what you can incorporate into a Jupyter file, and the open source community is continually expanding its capacities. The files are also supremely usable and can be directly uploaded to GitHub without conversion. As an individual or at scale, this a great open source editor to use for your next project, which explains why 451 determined that this is the most popular machine learning tool for enterprises in their new open source report.
Jupyter is not adept at communicating with other steps in the data pipeline. Data ingestion and project production are notoriously difficult and require tricky hacks for Jupyter to scale at all to operationalizable products. This is a point at which open source data science fails, and it’s definitely something to keep in mind when looking for other tools: it cannot offer complete data pipeline support and communication.
NumPy
NumPy is a specialized Python library for operations dealing with arrays, matrices, and high-level math functions like Fourier transforms. The successor to Numeric and Numarray, NumPy can operate at speed on both small and large matrices and arrays. This functionality makes NumPy essential for numeric computing in Python. As a flexible open source library, NumPy has a diverse group of developers continually working to improve its functionality: Version 1.15.2 was released last month in response to user feedback. The team at 451 found that NumPy was the second most popular machine learning tool, which fits with its more specialized use cases.
Open Source Overview: Critical Resources
As technology by and for its user community, open source provides integral value to the landscape of Technoslavia. While open source benefits from a host of developers, sometimes they still become deprecated as the core team moves on to other projects.
It is critical that data science teams use a combination of open source tools since one alone is never enough. To leverage Jupyter, data scientists need to leverage other tools to make their work reusable for others on their team. They must also find workarounds to stitch together work in Jupyter with other steps in the data pipeline (like putting the project into production). To truly take advantage of NumPy, data scientists must engage with optimization tools like (the now deprecated) Theano to ensure speed at scale.
No single open source tool can do it all. Read the 451 Research Paper to explore the right open source tools for your data science needs. And consider trying Dataiku 5.0, a tool that prioritizes seamless integration with a variety of open source tools at every stage in the data pipeline.