




If performing benchmarks for ML evaluation could seem self-evident, it conceals how crucial and challenging it is to build them. How can we ensure enough diversity in the selected datasets? Which baselines should be included for fair comparison? Which metrics should be reported? In this article, we relate our experience in building an evaluation framework for Uncertainty Quantification (UQ) in ML.
TL;DR: Uncertainty Quantification pushes for trustworthiness in ML but lacks a golden standard for evaluation protocol. During the ML Evaluation Standards hosted by ICLR2022, we showed in “Towards Clear Expectations for Uncertainty Estimation” that requirements for UQ are unclear, stressing the need for a reliable benchmark to compare UQ methods.
In this blog post, we describe how we build our benchmark and draw some recommendations toward a more reliable evaluation. Last but not least, we share some thoughts on achieving reproducibility and progress that emerged from the workshop.

{kind=link}
Cold Case: How to Evaluate Methods for Uncertainty Quantification
One natural expectation for UQ method is to be able to detect ML models errors or hard to predict samples. Although the ML community regularly publishes papers in top-tier conferences on UQ, there is no golden standard for evaluating UQ methods, making the quantitative comparison difficult.
Retrospective: Why Building a Good Benchmark Is Hard
The experimental validation on real-world data, which we usually refer to as a benchmark, is what mainly drives ML evaluation. We challenge competing methods by evaluating their performance on the same task, and the winner takes it all. ImageNet — one of the most cited scientific papers of the last ten years — is a striking example of a widely adopted task, image classification, that became the golden standard for evaluating computer vision systems.
We learned the hard way through this cold case that building good benchmarks is not simply collecting or labeling data. It is a genuine scientific endeavor to bring compelling evidence of progress. In our case, we wanted to assess how to validate UQ methods on tabular data; a modality often overlooked in recent literature. As a retrospective, we describe some pain points we encountered and how we addressed them.
What do we want to assess? We very quickly found out that UQ has no agreed-upon formal definition. You can see in Table 1 that almost every paper has its specific evaluation protocol. More generally, the requirements for a suitable UQ method are unclear in the literature, making the quantitative comparison across methods almost impossible. That’s what motivated our choice of downstream tasks that are the most relevant to the practitioner.
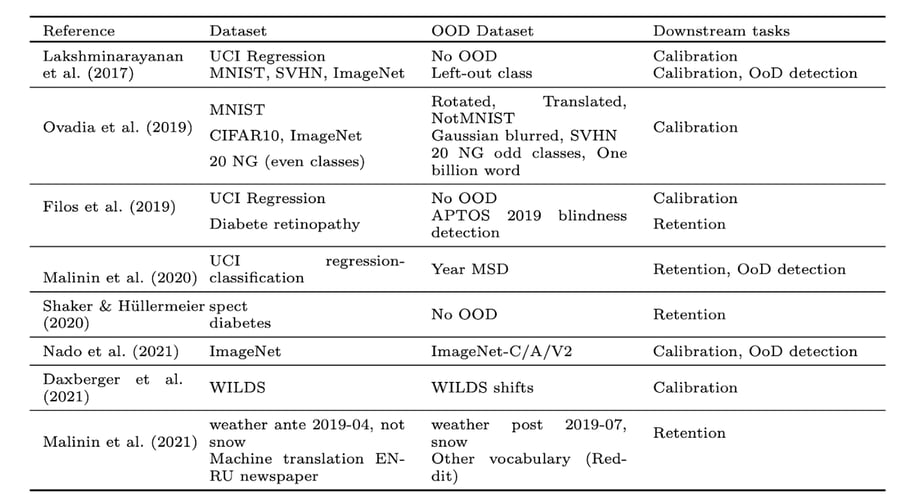
Evaluation metrics and tasks in SOTA work on UQ. Prior works in literature do not share a standard evaluation protocol, using different datasets or metrics, making it difficult to assess the actual progress of UQ for ML.
Does the benchmark measure what we want to assess? As our primary focus was on tabular data, we selected seven binary classification datasets from the U.C.I. repository. This is indeed a very limited sample of what a practitioner may encounter in practice, calling for carefulness about how our results generalize but we primarily wanted to propose a novel evaluation framework that could then be extended. Note that the success of ImageNet does not make it free from this pitfall! The computer vision community builds upon the assumption that better ImageNet performances imply better performance on other vision tasks. It is true at some level, as studied in this paper and this one, but we can’t take it for granted in general.
How to guarantee our results are reliable? Results reported in a benchmark are often an empirical quantitative assessment against a chosen metric, e.g., ROC-AUC for detecting errors. Given the many sources of variability of the result, e.g., a seed may promote a particular method, we must make sure an approach is genuinely accountable for an observed improvement. For our analysis, we carefully reported top-performing methods that were significantly better than competitors in the statistical meaning. To dive deeper into that question, we recommend this paper which investigates sources of variability in ML evaluation.
Panel on Reproducibility in ML Research
In our evaluation protocol, we did not find any evidence that supports using the latest — and potentially heavy — UQ methods on tabular data. In other words, we failed to reproduce findings that were primarily obtained in image classification with deep models.
This cold case shows that reproducibility goes beyond the availability of the code or the data.
“Reproducibility is to get better science […]; we should focus on the reproducibility of the findings, not a specific number.” said Gaël Varoquaux during a panel discussion at the workshop.
Pragmatically, it is more important to replicate the story we can tell behind the numbers — the finding that some UQ method outperforms baselines on many settings — than a particular number, e.g. an accuracy on ImageNet.
Progress Is Driven by the Fast Spread of Ideas
Promoting scientific rigor to meet higher evaluation standards seems to be at odds with the fast-growing body of ML literature as it requires more work, then leads to fewer publications. On the one hand, reviewers should be more selective when accepting papers for publication, for instance, by rejecting too incremental works, even if well-executed. On the other hand, as pointed out during the Incentive for Better Evaluation panel, this reasoning may be flawed because there is evidence — as reported in the NeurIPS 2014 experiment — that the ML community is terrible at foreseeing the potential impact of a work. To promote the fast spread of ideas, a group of researchers has created a new venue called Transaction of Machine Learning Research, where a piece of work should be published independently of a subjective assessment of significance as long as it is technically correct.
Conclusion
We are at a turning point where the increasing number of publications requires more rigorous evaluation to assess progress in ML. The prominent role of benchmarks can sometimes make us forget it remains a proxy of our true goal, not an objective by itself. If benchmarks were a perfect tool, we would not need to rely on subjective criteria when assessing work’s quality, such as claiming it is too incremental to be published. The growing number of events dedicated to these fascinating questions proves that our community has become more aware of this flaw and tries genuinely to fix it.