




{kind=link}
When working on group data projects, one of the most common challenges that teams face is difficulty sharing work in a transparent and efficient way. In this blog post, we will demonstrate how a collaborative data science platform, such as Dataiku DSS, can help alleviate some common pains around disparate technical skill sets, lack of visibility into teammates' logic and processes, and project communications and oversight by project owners.
Imagine playing on a sports team where players on the field are all simultaneously following their own individual interpretations of the game strategy, and each is making only the moves that align with his or her own personal strengths, but without coordination with others. I imagine there would be a lot of missed passes, failed shots, and frustrated players and coaches. Let's see how this analogy applies to data science.
From the outside, the perception of data science projects is that the teams are comprised of — no surprise here — data scientists.
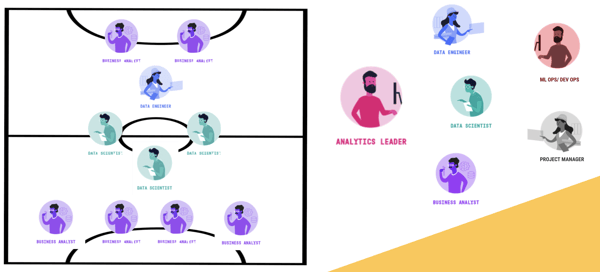
In reality, when working on shared data projects, we have a lot of different players: the analytics team lead, the project manager, business analysts, data engineers, data scientists, MLOps, DevOps, and so on. So conceptually, the field may look more varied than originally anticipated. Different positions serve different purposes, just like in sports.
One of the most common challenges that teams face is difficulty coordinating work in a transparent and efficient way. Sometimes that's because each person is working independently on his or her own machine with local copies of files. Maybe it's because some people have deep domain expertise but no formal data science training, and vice versa.
Other times, the challenge is that some team members prefer to use low or no-code visual tools to work with data, while others prefer a code-first approach. In the end, each person has a hard time understanding — much less replicating — what, exactly, other people are doing in their particular parts of the workstream.
In all these cases, the impact of these disconnects can lead to inefficiencies at best, and lower-quality outcomes and data products at worst.
See This Example at Work in Dataiku DSS
At Dataiku, we believe that collaborative data science is not only possible, but absolutely critical to organizations that want to scale AI. By embracing the different strengths and technical skill sets of various contributors and enabling them to consolidate their work in a governed and organized way, we ease these types of pains, and allow teams to develop data products both faster and more effectively.
Dataiku provides an end-to-end set of capabilities that allow data analysts, data scientists, and other profiles to access and prepare data, build and deploy machine learning models, and visualize and operationalize results, all in a single, centralized platform.
The image below shows an example of a Flow, the heart of a Dataiku DSS project and the visual representation of a very simple data pipeline.
Dataiku DSS not only offers a guided visual interface for those who prefer to point and click their way through data tasks, but also supports a full range of features for those who prefer to code — such as notebooks in a variety of programming languages, code environments, and APIs.
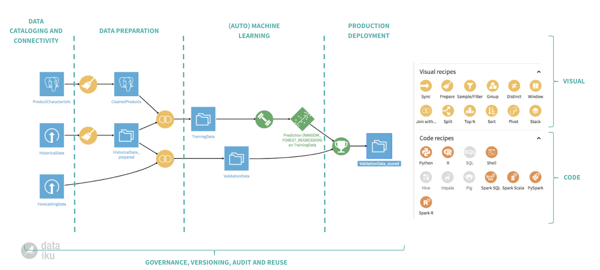
Regardless of which approach you choose, all the transformations and logic are automatically documented and visible to everyone, so that there's no ambiguity about what's happening to your data as it moves through the pipeline. It's like having a built-in color commentator!
Despite the comprehensiveness of Dataiku DSS as a data science and orchestration tool, some of our customers' favorite features are not technical at all! They're about housekeeping and administration, believe it or not. They love the Dataiku DSS features that:
- Facilitate collaboration, project communication, and oversight by mission owners.
- Foster efficiency and reuse, as we recognize teams will have new technologies, new people, and new processes coming online all the time. For example, when a new team member joins a project mid-stream, they can quickly get up to speed by reading the project wiki or inspecting the Flow to understand the design of the pipeline.
- Allow for visibility and governance, so there is a visual representation of all the transformations data undergoes, and users’ actions are logged so teams know who did what and when.
The features outlined above are just a few of the ways Dataiku can reduce the black-box effect, help different personas seamlessly contribute to the same project, and keep communication flowing. In the end, the team dynamic we want to foster is one where all the players use the same playbook, doing their part towards a shared goal and a win!