




{kind=link}
Let's face the reality: Data quality, despite its paramount importance, is often unloved and undervalued in many organizations. It is seen as excessively technical, demands a great deal of tedious effort and time to manage and, ultimately, leads to a lack of enthusiasm for taking up this crucial responsibility.
In the fast-paced business environment, data quality may not always receive the attention it deserves. With data continuously being generated and processed at a staggering rate, ensuring its accuracy, completeness, and consistency can be overwhelming. Moreover, the complexities associated with data integration and governance further contribute to the reluctance to embrace the data quality dimension wholeheartedly. So, how can teams rekindle the flame and passion for data quality? And move from a general disinterest in data to a lasting love of fixing it?

Data Quality: Not Just the Tip of the Iceberg
Data quality issues, akin to an iceberg, are often more complex than they seem. Top executives may see data issues as manageable on the surface, but data analysts, data engineers, and data scientists know it's an iceberg concealing deeper complexities. It’s no surprise that data quality remains a perennial challenge as poor data still endures despite technological, governance, and team efforts. Ironically, data quality has never been more crucial for a company's digital success: Sharing and distributing wrong and poor data will trigger a snowball effect that could lead to costly repercussions, potentially becoming the bane of the business.
Putting Desire Back at the Heart of the Process
In the marketing world, the AIDAR (Attention, Interest, Desire, Action, Repeat) model is a well-established method used to engage potential consumers and ignite their interest in a product. Interestingly, this model finds relevance beyond marketing in the context of data quality. So, let's explore what it takes to reignite the passion and appreciation for accurate and reliable data from the prism of the AIDAR model.
#1 Awareness: Showcasing Data Quality Issues as Critical Business Challenges
Engaging key stakeholders, including top-level management, data analysts, and users, is vital in comprehending the far-reaching consequences of poor data quality on organizational performance.
Poor Data Has a Business Impact:
Presenting the issue from a business (revenue, cost, risk) standpoint with supporting evidence and conducting workshops and case studies can help anticipate problems. Demonstrating real-world scenarios where data quality issues led to costly mistakes or missed opportunities enables proactive measures to prevent similar occurrences in the future.
The Revenue Impact:
Customer data tends to be at the forefront of data quality problems due to its paramount importance for companies. For instance, during CRM migration, duplicate entries of crucial customer profile information in Salesforce can impede the effectiveness of customer marketing campaigns and hinder the availability of essential insights necessary for successful upselling tactics.
The Cost Impact:
Consider a scenario where the billing system fetches customer billing addresses from the CRM which are erroneous. This can lead to immediate disruptions in cash flow, underscoring the critical importance of data accuracy in ensuring seamless business operations.
The Risk Impact:
In the context of GDPR, poor data management poses a risk of non-compliance. For instance, if customer consent for data processing is not properly documented or is outdated, or sensitive data is left uncontrolled, the company may face severe penalties and reputational damage.
#2 Interest: Quantifying the Business Impact of Data Quality Issues
Understanding the impact of a quality defect is not simply about identifying the number of datasets that contain a specific number of anomalies. Rather, the crucial challenge lies in evaluating the operational cost associated with this defect.
When dealing with anomalies in datasets, it is essential to go beyond mere quantity analysis. While knowing the extent of anomalies is valuable for assessment, it is equally important to consider the practical consequences of these defects on operational processes. The operational cost refers to the potential negative effects of these anomalies on various aspects of an organization's operations, such as productivity, efficiency, accuracy, and overall performance. Highlighting specific instances of data quality failures and estimating their financial and operational impact create a compelling case for action.
A good example of quantifying business impact is the impact of bad data on the effectiveness of a marketing campaign. Here is an example of how poor data could impact the marketing funnel of an organization and how data quality can positively impact the bottom line.
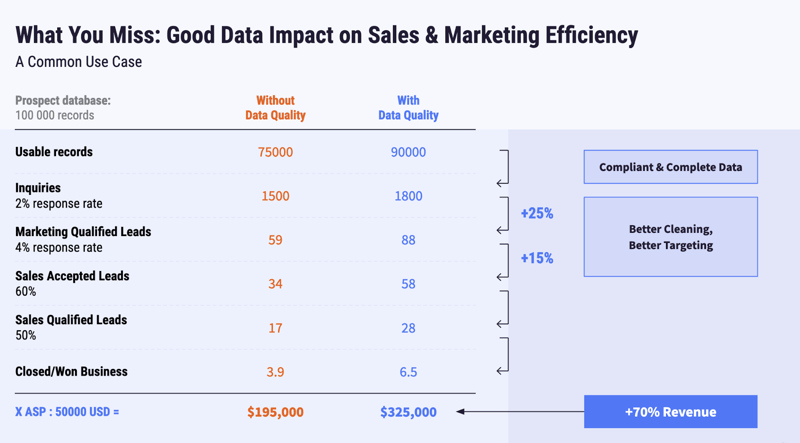
Examples like these speak for themselves and can help convince the executive committee to implement a global strategy.
#3 Desire: Establishing a Data Quality Strategy With the Right Team
This step involves developing a comprehensive data quality strategy that addresses the root causes of the issues identified during the awareness and interest stages. When it comes to data quality, small streams often make big rivers: A data quality strategy should not focus on trying to boil the ocean but on setting concrete, achievable objectives with a business focus.
Form Business & Technical Duos:
As written earlier, technical data quality and business issues are two sides of the same coin. Therefore, it seems appropriate to engage teams similarly. Implementing pods, which are two-headed teams composed of representatives from departments affected by data quality issues on one side and technical data & analytics departments on the other, will facilitate effective management of both aspects of data quality.
Pods will identify use cases by engaging with respective departments to ensure that needs and concerns are incorporated into the strategy. The data strategy should be measurable to prove it has an impact: It’s crucial to establish well-defined data quality metrics and Key Performance Indicators to monitor progress and gauge the efficacy of data quality initiatives.
#4 Action: Implementing Data Quality Improvement Initiatives
With a well-defined data quality strategy, it's time to act and execute the planned initiatives.
Tools Must Adapt to Collaborative Strategy, Not the Other Way Around
In the same way that data quality pods were built to tackle data problems, they need a common space to work together on the same datasets, based on individual expertise and fostering a unified understanding. As we said, it’s often frustrating to discover data, clean up, and share data if the tools can be disparate, too technical, and unsuited to a collaborative approach.
Opting for tools that are user-friendly and easy to learn is vital. Moreover, it's essential to ensure these tools seamlessly interface with the data systems established by the IT department. To know more about action steps to operationally solve data quality and how Dataiku can help, check out this blog about the key operational steps to make data better together. This blog is an essential resource for exploring and understanding how Dataiku empowers data workers to delve deep into data discovery, data cleansing processes, and the sharing of trusted insights.
Celebrating Team Success and Achievements
Once data is trusted, it’s equally important to recognize team efforts: Celebrate data quality successes, highlight trusted data as significant achievements, and showcase the positive impact of data quality improvements to sustain the organization's commitment to data excellence.
|
Unilever's Journey With Data Quality: Enhancing Consumer Insights as a Team Unilever aimed to establish personalized digital relationships with its 3.4 billion consumers worldwide, which required understanding individual consumer behaviors, interests, and demographics across 38 Digital Hubs. However, they faced challenges like the large size of consumer data, unstructured data arriving from various digital channels, lack of common consumer identifiers, and the need to enable non-data experts to leverage this data while adhering to data privacy policies. Unilever tackled the data quality challenge collaboratively using Dataiku. They employed a lean team to create primary data pipelines, automating data cleansing, standardization, and accuracy. Using Dataiku's capabilities, they joined consumer data sets to form a Unified View of Consumers (UVC) and built a simple web app, Audience Creation Tool (ACT), empowering non-technical users to create consumer audiences. Unilever's approach led to impressive outcomes. They saved approximately 175 hours per month of data engineering and data scientist time, reduced audience creation time by 98%, and improved data accuracy by 50%. The UVC increased descriptive data points per consumer by an average of 87%. Moreover, democratizing data access enabled anyone in the organization to execute an audience, enhancing collaboration and efficiency. Dataiku's versatility played a pivotal role in achieving these results, enabling Unilever to overcome challenges and foster a data-driven strategy effectively. |
#5 Repeat: Fostering Improvement and Encouraging Reuse Through Automated Monitoring
Data quality improvement is an ongoing process, not a one-time endeavor. The business and technical teams in charge need to refresh the existing data and address various other use cases. This involves updating and maintaining current datasets to keep their accuracy and relevance, as well as exploring and implementing additional data-driven use cases to meet additional business needs.
At the core of a data quality practice lies the establishment of a culture committed to continuous monitoring and improvement. Regular data audits and the meticulous design and review of systematized data quality metrics are key pillars in this endeavor. It also means designing and operationalizing feedback loops with data observability and automated monitoring to identify emerging issues and opportunities for enhancement.
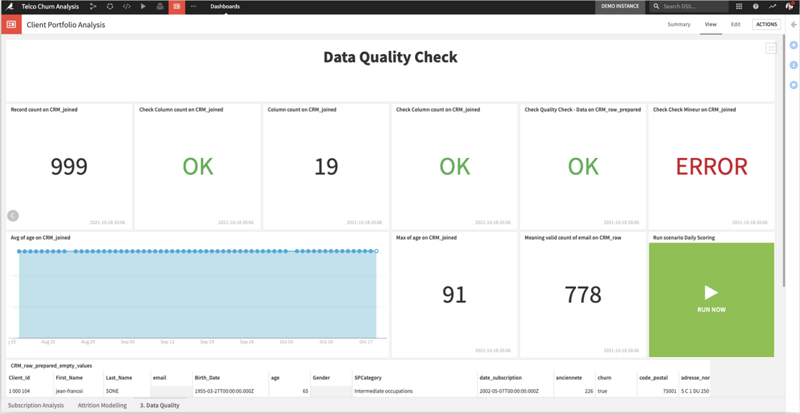
Figure 1: Metrics in the Dataiku platform automatically assess data or model elements for changes in quality or validity, and checks ensure that scheduled flows run within expected timeframes and that metrics deliver the expected results. Configurable alerts and warnings give teams the control they need to safely manage data pipelines without the tedium of constant manual monitoring.
The Value of Data Lies in the Use of It
To amplify the value effect, data must be accessible and utilized. This entails creating a reliable, centralized data catalog where trusted data is readily available for reuse and exploitation by as many individuals as possible. This key step will empower other business departments to derive greater insights, build data products and unleash the true potential of data, culminating in a profound appreciation for data within our organization — a state we affectionately call "data love."