




In January, our Dataiku Lab team presented their annual findings for up-and-coming machine learning (ML) trends, based on the work they do in machine learning research. In this series, we're going to break up their key topics (trustworthy ML, human-in-the-loop ML, causality, and the connection between reinforcement learning and AutoML) so they're easy for you to digest as you aim to optimize your ML projects in 2021. We've already tackled trustworthy ML, so up next is a summary of the section on human-in-the-loop ML, led by research scientist Alexandre Abraham. Enjoy!
Alexandre Abraham:
Last year we talked about learning with small data. We evoked how weak labeling could be used to perform mass labeling of samples instead of the traditional one by one labeling approach. Although most of you remember, I remind the others that weak labeling consists of massively labeling samples using rules that may be noisy (i.e., not valid for all samples).
Our hunch ended up being true as the major actor in this sector, Snorkel, turned its methods into a service and started its company Snorkel AI. One of the missions they advertise is related to information extraction from documents since this is what human annotators are very good at — giving rules for language-related matters. So why do we think that human-in-the-loop ML can still be a trend and in what way?
Setting the Stage
Let’s go back to the 70s when expert systems were the norm. In order to solve a problem, experts were asked to design rules and the result was a model for which the domain of action and the behavior was well known. Then, machine learning arose. By having models learn on data, we improved their accuracy at the cost of understanding. However, their straightforward interpretability allowed to easily validate some of their behavior and even correct them by tuning the loss or setting weight limits on some features.
Complex Models Can Make Inexcusable Mistakes
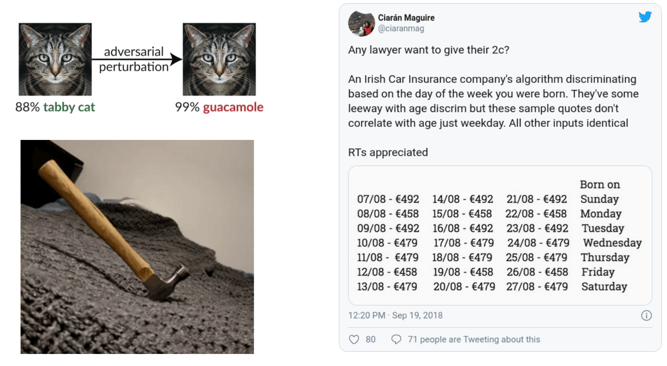
But now that deep learning has become more common, we have witnessed the emergence of a totally unexpected problem: inexcusable mistakes. In fact, the deep learning models are so complex that they can end up failing in the most uncommon ways and debugging them can be tricky. Simona already showed you the cat that becomes guacamole with adversarial noise being added. On the right you can see a model estimating insurance policy prices that displays a 10% different based on the day of the week the client was born. And finally at the bottom you see a very famous example that tends to drive object detection algorithms nuts: the hammer on the bed that is tricky because hammers are not usually seen in this kind of context.
So how can this problem be tackled? Well, why not using the tried and tested old methods? Yes, it can be tackled using expert systems. More precisely, and to build upon what we said last year, we want to do more than simply ask an oracle to label data. Experts have more elaborate knowledge and this is not the most efficient way to use their time. Snorkel has proposed to use human-defined rules to generate pseudo labels, which is a first step toward integrating rules into models.
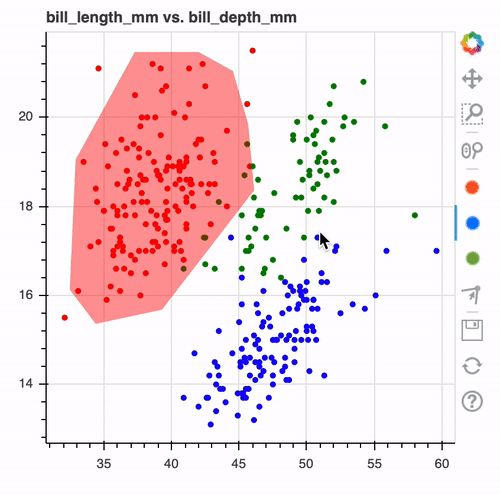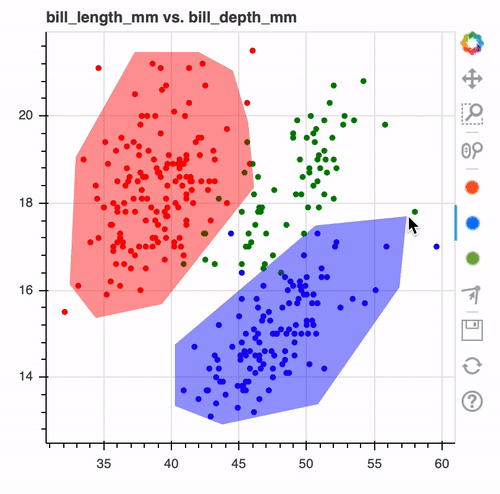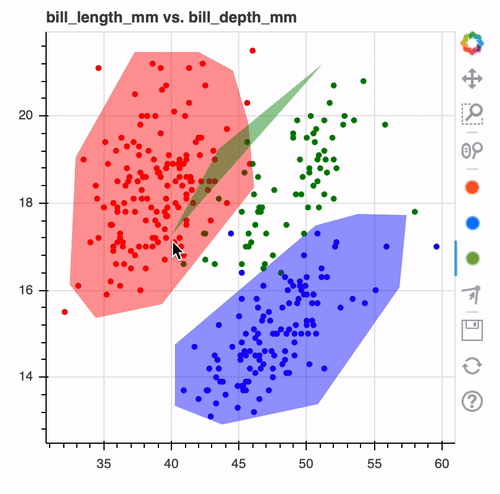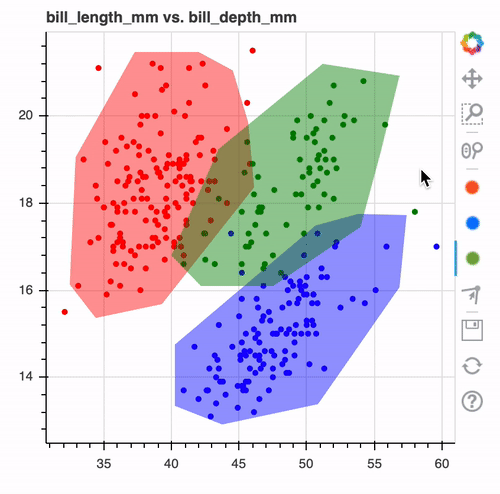
But actually, scientists are working actively on refining the way to interact with human beings in order to better distillate their knowledge into the machine learning model. First and foremost, people are looking at new ways to extract rules from data. We already know decision trees, which are based on simple rules and algorithms like C4.5. But rules are not only about data. Human learning has demonstrated that SOTA data visualization can make it easier for humans to label data and can help extract information. For example, the labeling below can seem obvious, but with this simple viz and a lasso editor, we are able to define our classifier, overlap data, and application domain. Those are the most basic interaction but yet they are already easy to interpret and to validate by a human.
{kind=link}
However, we know that this tool is not enough. We want to be able to put human knowledge directly in our deep models. The methods we have shown benefit of human intelligence by interacting with them at learning time or at inference. But human knowledge could be directly integrated in the design of the model itself. Google has been working on the matter and proposed its wide and deep models in 2016 model mixes expert knowledge under the form of task-specific feature engineering in the wide part, and a deep model to learn upon the residuals or complex patterns that may not arise from expertise. Published in 2018, rules first classifiers combine rules and machine learning based classifier in a boosting fashion.
But the pinnacle of knowledge distillation is achieved in self-supervision where the human design an exercise, or a scheme, that allows the algorithm to learn by himself. SimCLR as displayed in this slide uses the fact that some image transformation such as adding noise, horizontal or vertical flipping, etc. do not impact the label of the sample.
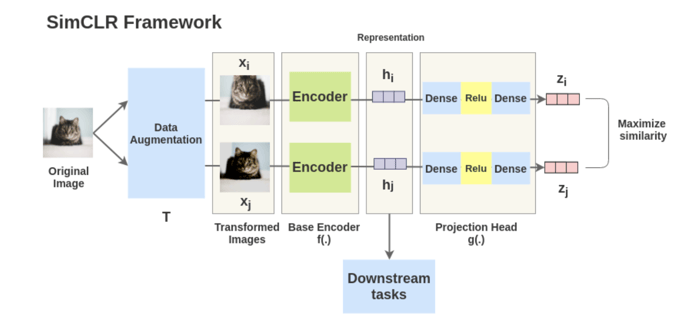
By doing so, the algorithm can learn that one image and an augmented version of it must be close in their embedding space. Using this auxiliary task, embeddings can be learned on unlabeled data, which can then be used to train a classifier. This algorithm offers unprecedented scores on ImageNet in a completely unlabeled fashion. My guess for 2021 is that these methods that already exist will grow faster, become go-to methods, and even reach the industry.