




In many respects, machine learning (ML) models are not all that different from people. How so? Well, they infer patterns to make faster decisions, often through picking up biases (good and bad) along the way, and, as you have likely observed with friends, colleagues, and partners, they can act unexpectedly in unfamiliar or stressful situations. Diving into the process of interrogating model performance to anticipate behavior in the wild, this blog rehashes a recent Dataiku Product Days session.

The Impact of Deployment Conditions
Even when a model is carefully trained on a well-prepared dataset, the volume, quality, and context of information often differ in the deployment environment for a variety of reasons. Noise, data corruption, and shifting demographics in the underlying distribution being modeled can lead to grave consequences in business critical domains.
Is Your Model Able to Adapt?
To combat this risk, organizations must go beyond mere performance evaluation, and assess model robustness prior to deployment; i.e., How well will their models cope in the wild when faced with the gritty reality of real-world data?
Judging Model Robustness
Assessing model performance under various forms of stress is already commonplace in some industries such as finance, where teams determine the robustness of their models by simulating a range of hypothetical economic scenarios from the mundane to the seemingly unlikely (cf. black swans). While generating plausible, internally consistent, synthetic data (encompassing the nuances of interest rates, foreign exchange rates, etc.) is a field of its own, there are parallels that can be transferred and applied by ML practitioners more broadly.
Some Everyday AI examples for which you might like to test model invariance:
- Language swaps (i.e., synonyms, typos) in natural language processing tasks
- Lighting/color grading, rotation, etc. for visual tasks
- Small numeric shifts for structured tasks
- Adversarial perturbations
The goal is to create small or subtle differences in the input which should not lead to a switch across a decision boundary. With a robust model, there would need to be meaningful changes in key semantic/conceptual directions for predictions to shift.
Other Problems That Might Pop Up
Sometimes performance issues originate from the quality of incoming data. Even well-engineered pipelines can suffer from data degradation or corruption from time to time — neither of which may bode well for predictive power. Fortunately, it’s straightforward to gauge a model’s resilience to such conditions by imputing missing values and outliers to simulate noisy sensors.
The Process of Stress Testing
Because, in many instances, a model is only as good as it is on its worst day.
Now that we have outlined why it is important to stress models prior to deployment, let’s get into what that looks like.
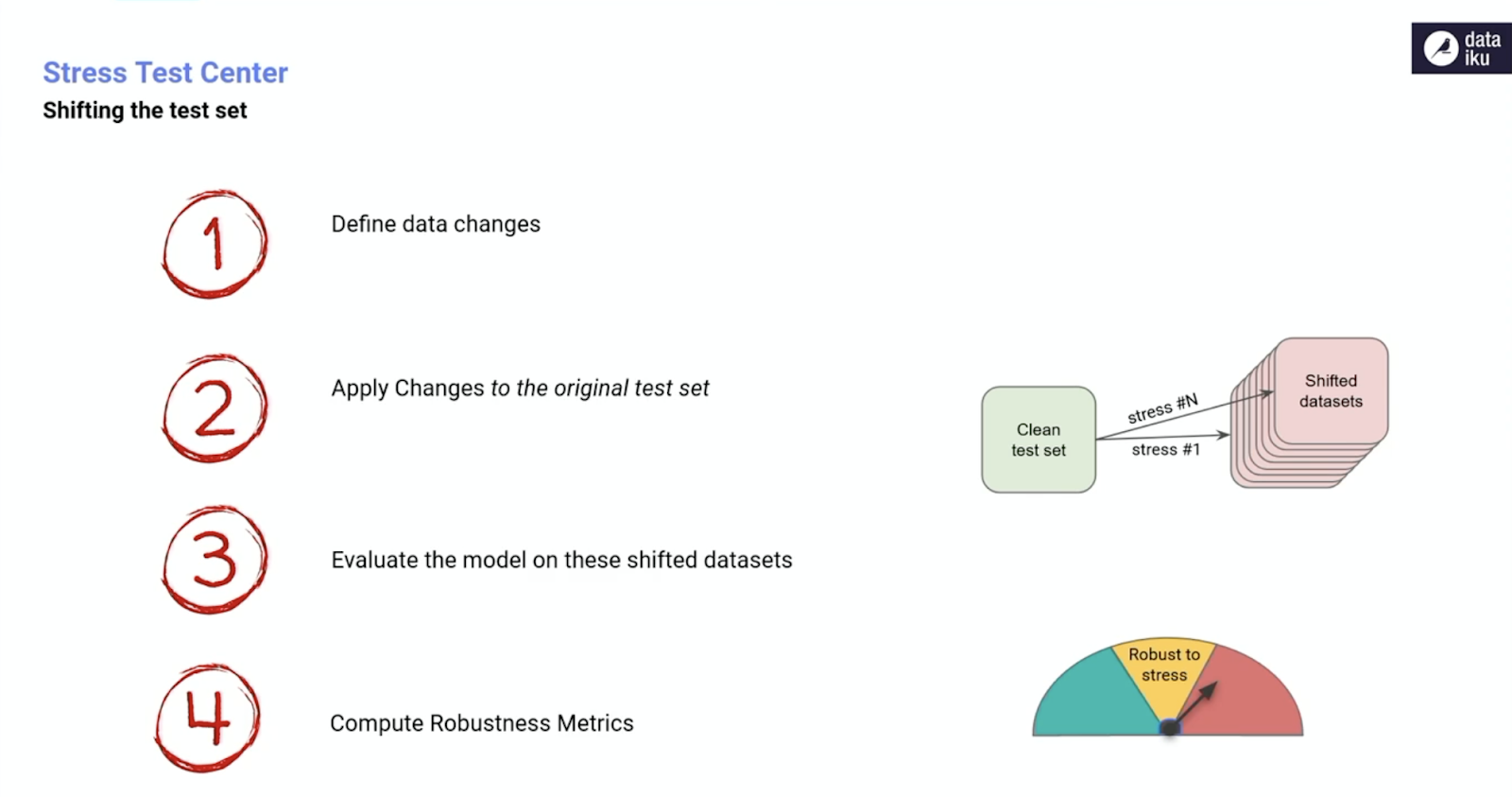
The Steps to Stress Test
- Define data changes.
- Apply changes to the original test set.
- Evaluate the model on these shifted datasets.
- Compute robustness metrics.
Batch-Level Robustness Metrics
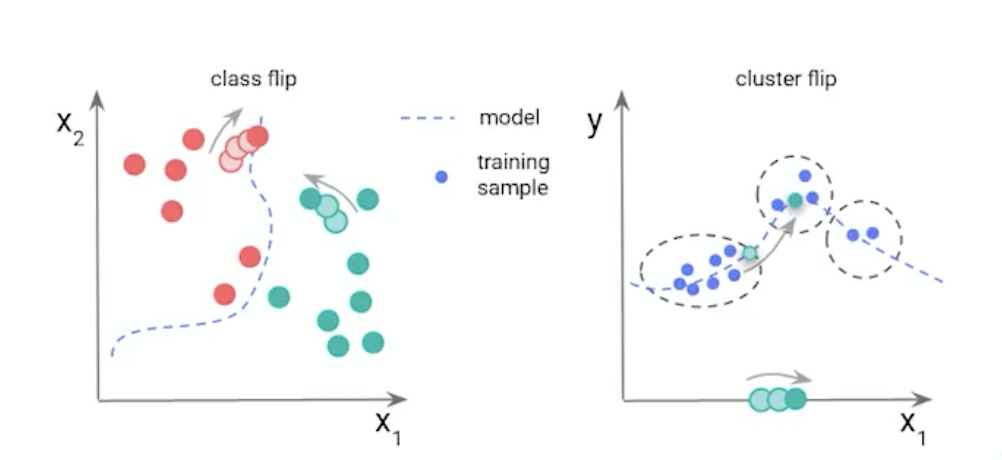
Perhaps the first and foremost evaluation that comes to mind when conducting such an analysis is to compare the level of performance drop between an unadulterated “control” dataset and the “stressed” variants of the said dataset. Another perspective can be gleaned by looking at the resilience rate which aims to capture the nuance and may be hidden behind a small performance drop. In classification tasks, this reflects the proportion of samples with the same predicted class between stressed and unstressed datasets. In regression tasks, it’s indicative of the proportion of records where the error between the true and predicted values is not higher under the stressed scenario.
It can also be interesting to evaluate the impact of shifting subpopulations, identifying which groups have the lowest performance because, as mentioned before, in many instances, a model is only as good as it is on its worst day.

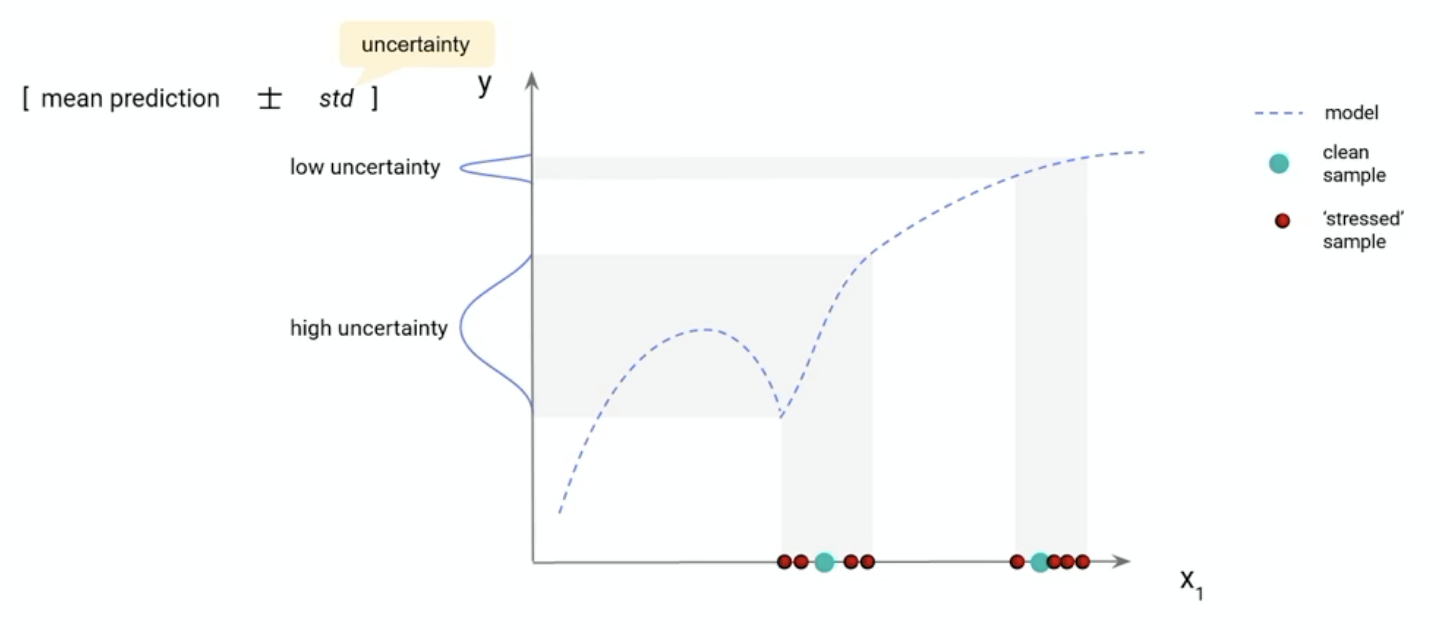
Sample-Level Robustness Metrics
Going deeper than the batch level, we can also look at robustness at the individual sample level by calculating statistics on predicted values or true classific probabilities. Uncertainty can be inferred by the prediction instability exhibited across the stressed datasets for a given sample. Critical samples are those with the highest uncertainty and are indicative of the records which are most susceptible to stress.
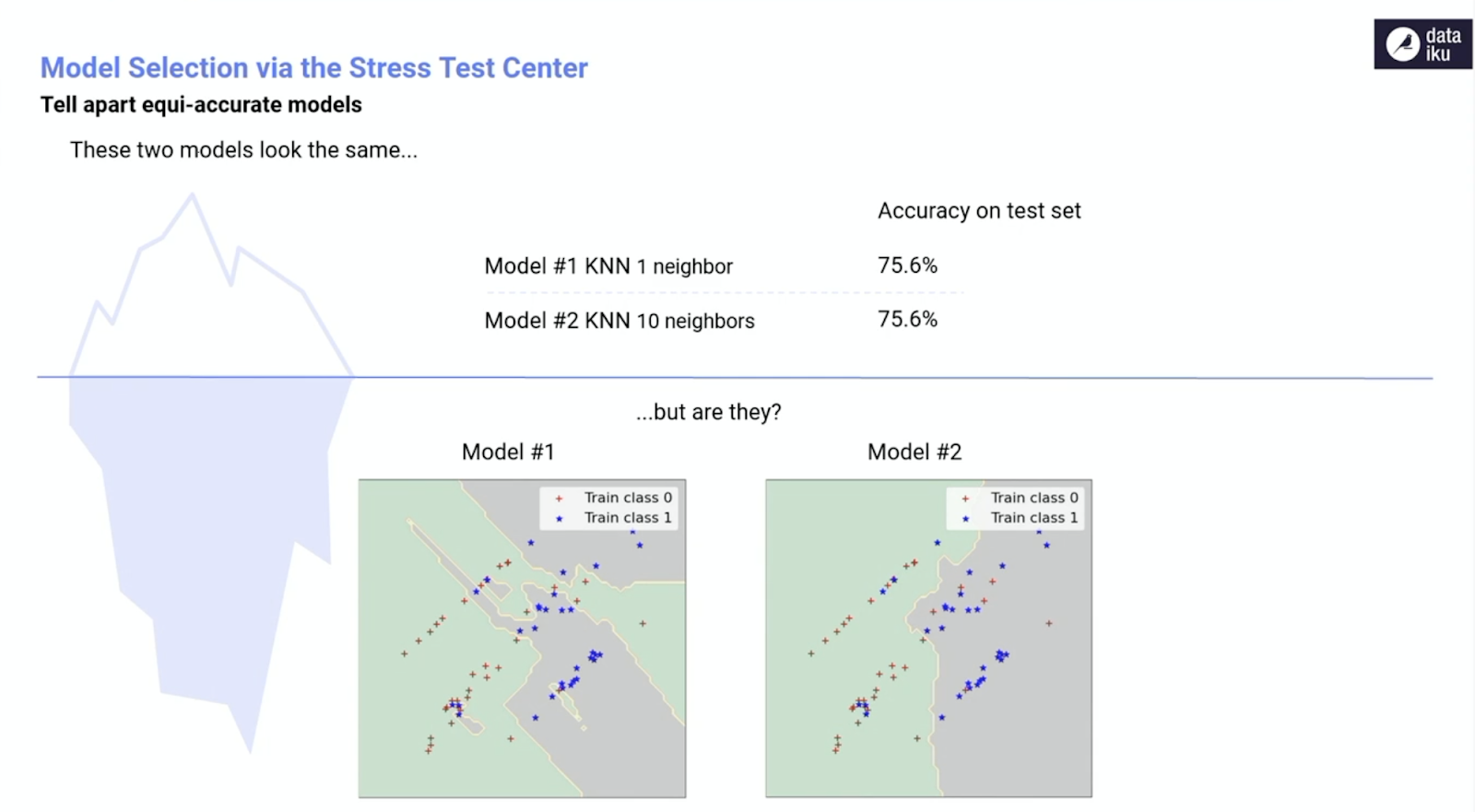
Interrogating Models to Make a Selection
Sometimes we have to go below the surface to be able to choose between models that appear similar (equi-accurate models).
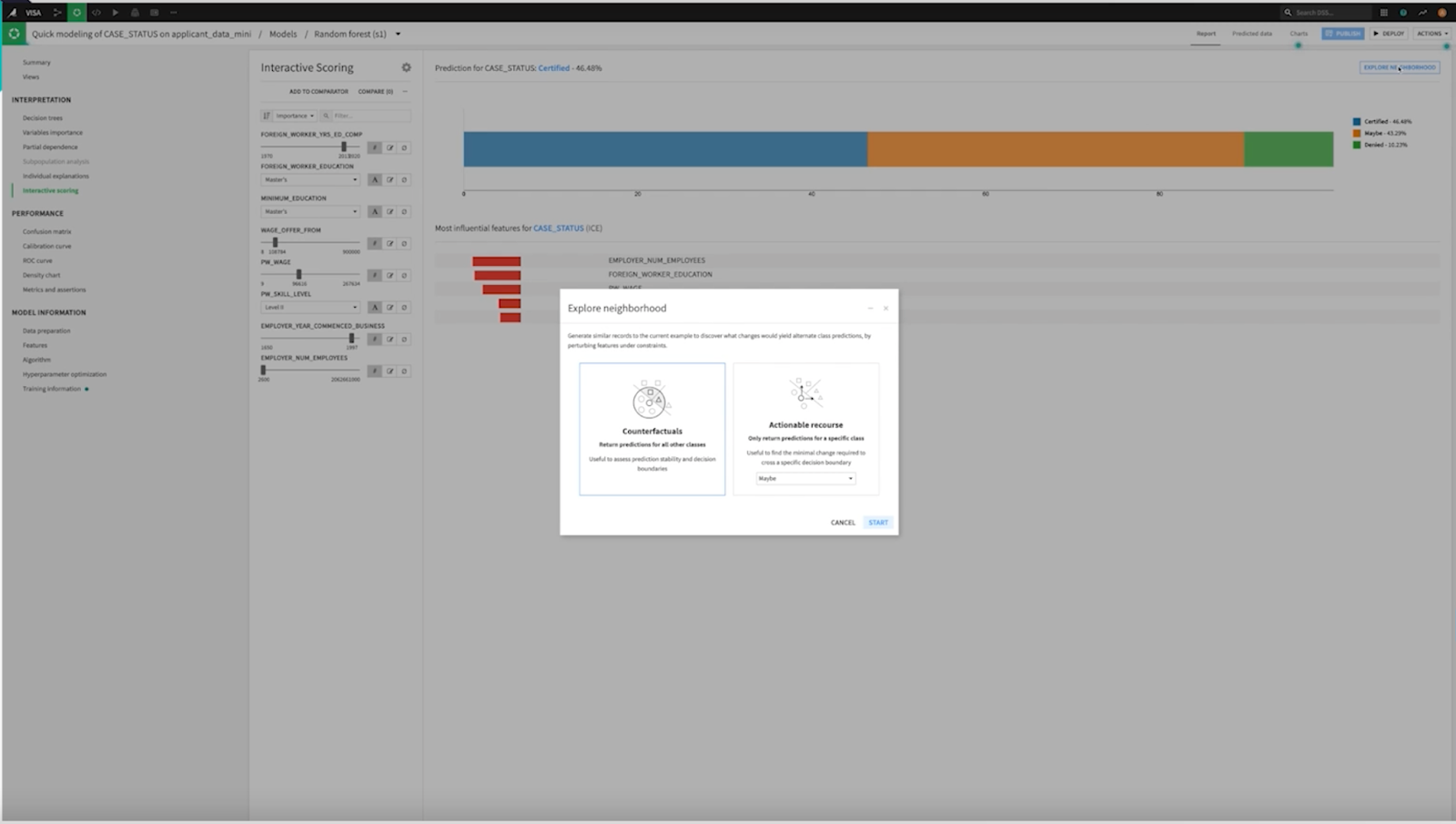
One way you can approach this problem is through the lens of counterfactual explanations. In this case, you are trying to ascertain the stability of a model’s decision boundary. You begin with a reference sample and adjust it until it crosses over to an alternate predicted class. Judging the extent of change necessary can provide a sense of whether the data point falls within a stable region or whether it lies close to a decision boundary. Many diverse counterfactuals (dissimilar modifications from the reference) close to the original record might indicate a region where the model is unstable.
Another way to look at it is actionable recourse. In this mindset, you are taking a specific example and trying to understand what is the smallest (realistic) change that could be made for a specific alternative (typically beneficial) outcome to be achieved.
In both cases, it is useful to focus the search on plausible records (i.e., those similar to what the model has already seen and could expect from the underlying distribution as the investigation can be computationally expensive). Before relying on a smart algorithm to intelligently explore the feature space, leveraging domain knowledge to constrain the variables should be the first port of call.
Dataiku 10 Exploration Features
Actionable recourse and counterfactual explanations can be easily achieved with Dataiku, to answer important “What if” questions like, “What if I applied for the mortgage with XXX deposit instead?”
{kind=link}
Features can be set as ‘actionable’ for bounded exploration or frozen to a specific reference value. These capabilities enable you to effortlessly interrogate your model for robustness and gain a better understanding.
For a complete overview of the features released in Dataiku 10, check out this video.