




In a recent Dataiku Product Days session, Dominick Rocco from phData gave us the rundown of their perspective on MLOps and shared an interesting use case where MLOps is leveraged for HR department goals. This blog hits the highlights of his session including a recap of Dataiku’s key MLOps capabilities in part one in relation to the use case in practice in part two.

In order to see how the HR use case we'll explain below is impactful, we'll start with the theory up top for background and context.
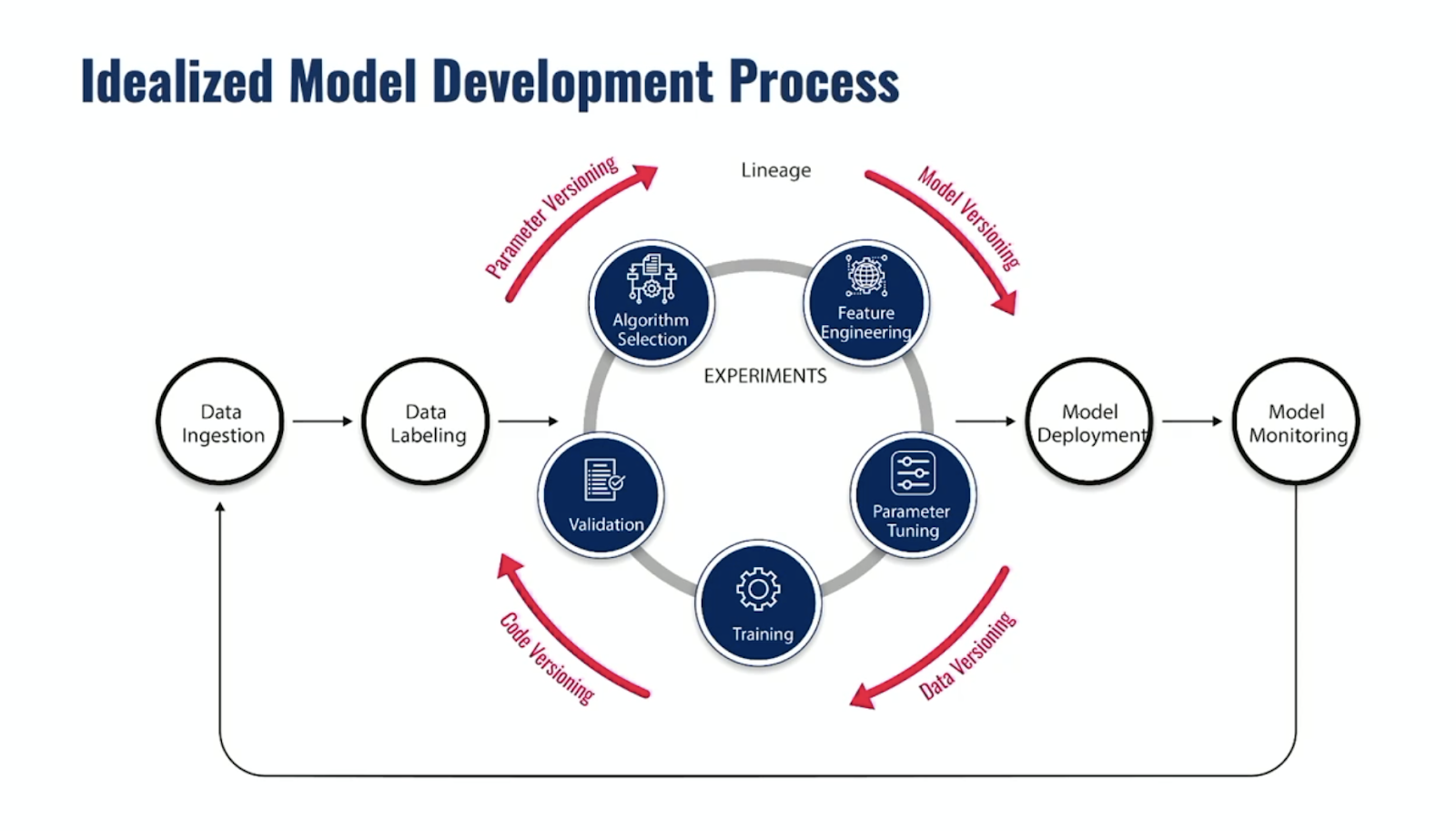
The process of creating and seeing a model through to production is a complex one and, in reality, many organizations — despite their best intentions — have things go awry in the process. This is where best efforts, specifically best MLOps efforts, should become front of mind. Data scientists must not haphazardly throw models over the fence to engineers hoping they can turn unorganized, unchecked models into something viable.
There are many negative consequences that appear when organizations do not place proper attention on MLOps. You can have source code and datasets that get misplaced or deleted or deployments that take much longer than they should. You also may end up discovering that the performance of your model degrades over time. The list of negative impacts goes on. As a result of the errors that collect from not implementing a proper MLOps strategy, your models will never reach their full potential for business value. So, in order to avoid these negative results, an organization should hone in on the key principles that drive MLOps from the exploration stage to deployment all the way through the feedback phase.
Part 1: phData’s MLOps Core Principles
- Reproducible Research: Anticipate the transfer of models to engineering teams and preserve artifacts for follow-up research while enabling retraining as necessary.*
- Streamlined Deployments: On the engineering side of things, use repeated architectures, deploy continuously, and utilize automated model retraining.
- Operational Excellence: Monitor model performance for drift, alert any failures, and prepare to roll back updates.
In the world of ML, you are crafting applications that reflect data. As a result, it is critical to version said data and to pay attention to the metrics on the quality of your ML algorithms. You should continuously investigate the metrics for the experiments you ran and constantly evaluate the output of those experiments. Finally, remember when you train ML models, they produce the models themselves which are serialized artifacts, and these can be quite large. To run the whole show seamlessly, the right tooling and technology are not just a want but a necessity.
*Making experiments repeatable and results readily available will involve:
- Software: custom code and external dependencies
- Data: copies or snapshots of datasets used for training
- Metrics: input parameters and performance metrics
- Models: serialized model artifacts for comparison and deployment
Part 2: Manager Performance Forecasting HR Use Case
Let’s pause. Why would an organization even want to take on an ML project pertaining to this specific use case? The answer is simple. It will lead to better employee performance and business results all around. Measuring manager performance effectiveness can help organizations justify training and other internal initiatives. At the core, manager performance is a key driver of employee satisfaction; taking preemptive action based on analysis results can avert future issues like employee churn and even project failure. Through studying data-driven insights, an organization can identify the areas in which they need to improve and the ones where they are already doing well.
The Data Being Dealt With
As we mentioned above, data is a key part of the phData MLOps core principles, so let’s take a look at what exactly The HR department had a good handful of data sources available that proved valuable to a manager performance evaluation project. This included an organizational health survey, performance reviews, promotions, rewards program, employee feedback, and development activities.

Combatting Project Challenges With Dataiku
In this particular use case, the main challenges were related to data diversity, data quality, and collaboration. All of the datasets have very different filtering and aggregation requirements to enable linkage. Some datasets were sparse and had missing values. On top of these data issues, the project team had a mix of non-overlapping skills: SQL, Python, Stats, HR. Luckily, Dataiku was able to help. Dataiku made it easy to ingest all data in separate flow zones and merge the zones. And Dataiku helped profile and resolve issues iteratively all with a platform that enabled easy collaboration between profiles of varying expertise and skill levels.
As you likely guessed by looking at the plethora of data sources, this was not going to be a trivial project if you were not using the right tools. Trying to run the pipeline manually with so much data in many different notebooks would be an extremely arduous process.
But with Dataiku, you can start with a particular flow zone connected to one of your data sources and then plug that into the rest of your overall flow! With one click of a button, you can run and manage the whole project without having to manually track each of these steps. This empowers teams to grow the complexity of their ML models.
It’s one thing to just create a machine learning model on one data source but to really get to the next level in data science, you have to be able to create complex workflows like this.” - Dominick Rocco

In the image above, you are able to see where the team reduced the forecasting problem to a simple regression problem by appropriately aggregating all the time series data into well-engineered features. You can see how Dataiku training is built into the flow, the model’s output, and some of the test scoring.
Additionally, it was easy for the team to stack models. With the output of the regression model, they were able to do a clustering analysis — clustering the output into well-performing managers, middle-performance managers, and underperforming managers. They could then link those clusters to some attributes, such as development activities.

{kind=link}
MLOps is integral to Dataiku flows. Dataiku flows are automated by default, versionable and reproducible, as well as observable and monitored.
The Project Outcomes and Takeaways
With the successful implementation of MLOps, the team was able to efficiently garner key understandings from the ML project, such as guidance for intervention and points for targeted development. HR could see which managers were on the verge of underperforming and fix the issues proactively. By inspecting areas of weakness identified through the data, HR was also able to recommend specific content that would help managers improve their performance and reach the next level.
The solution is expected to save upwards of $1.8M by reducing workforce churn.”
From the project team’s perspective, the main takeaways were that Dataiku flows made it easy to ingest and process data from multiple sources and built-in recipes fully supported the entire ML project process.
Collaboration was easy thanks to the nature of the platform and ultimately all of the best practices for MLOps were reinforced with Dataiku.