




{kind=link}
Our industry has talked about the three pillars of digital transformation for decades: people, process, and technology. However, most organizations implement them in the reverse order. A shiny new technology appears and we prioritize its implementation: enterprise databases, personal computers, spreadsheets, three-tier architectures, business intelligence reporting, the internet, mobile computing, big data, data mining, cloud computing, self-service business intelligence, AutoML, AI, and now Generative AI.
If there’s enough time between shiny things then we update processes but too often that focuses on tech rather than business results. Examples are defensive data governance (security, quality, and privacy), offensive data governance (self-service, democratization), and data classification (public, confidential, internal only, personally identifiable information, personal credit information, protected health information, etc.).
If there’s still some time left before the next technology then we upskill our people. People came last and that’s now increasing the cost of innovation. In the technology pillar of the digital transformation treble, there’s a well-known concept of “tech debt” which means that by selecting a quick and easy solution today, you increase the effort of upgrading to a better solution in the future. You’ve increased the cost of future work. An example is heavy use of stored procedures in a database. If you’re dependent on hundreds of Oracle stored procedures then you’ve increased the cost of moving to Snowflake or Databricks in the future.
We’ve taken quick and easy paths with people for a long time and accumulated what might be thought of as “data culture debt” that increases the cost of future upskilling. An example is data classification and governance. If workers don’t understand how to deal with PII, PCI and PHI then that increases the cost of adopting self-service advanced analytics in the future.
Organizations should reduce their data culture debt to get the most out of AI.”
Three data culture development programs commonly used today are data literacy, citizen data scientists programs, and data mesh. We’ll share some key details around how to implement each program below.
Data Literacy Program
Data literacy is typically the first data culture program run. Similar to natural language literacy, it teaches employees to read, write, comprehend, and explain data. It’s best suited to midsize and large companies that have large amounts of proprietary data that could improve decision-making. Key components of successful programs include branding the program, peer-to-peer mentoring, lots of hackathons, executive immersion workshops, and internal conferences to evangelize business value creation and celebrate individual successes.
Two drivers of the cost of data literacy programs are how course material is developed and how many employees go through the program. Some organizations chose to reduce costs by using free content from YouTube, Coursera, Khan Academy or our academy and making it available to thousands of employees. Others use consultants who already have generic material that can quickly be customized. Lastly, some organizations consider data literacy to be a strategic advantage, worth as much as 5% of their enterprise value, and invest time and effort into developing their own material.
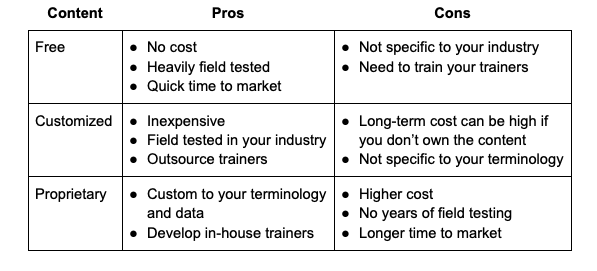
The second cost driver is how many people to get involved. Most companies underestimate this because data literacy is a cultural change and culture is difficult to measure. You need enough to make the change sticky by developing a sustainable community. For business transformations in general, McKinsey research indicates that less than 7% participation leads to negative ROI and 25% or more involvement is ideal. Note that this doesn’t mean that a fourth of your workers will become SQL and Python programmers. Data literacy focuses on higher-level concepts rather than specific tools or skills, and there are many no-code environments available.
Citizen Data Scientist Upskilling
Data science upskilling takes data literacy to the next level by providing teams with skills for manipulating and understanding data that go far beyond charts and tables. It’s increasingly necessary because of the immense volume, velocity, and variety of data that enterprises have at their disposal today. Can you imagine analyzing 10,000 warranty claims PDF files or 50,000 variables from a manufacturing process in Excel or Tableau? Doesn’t work. New methods are needed and that’s what data science, AI, and machine learning (ML) provide. It shouldn’t be too surprising that the components of successful citizen data science programs are the same as for data literacy: branding, mentoring, hackathons, executive immersion workshops, and internal conferences. Many organizations also add capstone projects.
Citizen data science upskilling programs are good for organizations that already have a lot of data in data warehouses or data lakes. We’ve seen them work well across many industries and lines of business including semiconductor manufacturing, oil and gas, pharmaceuticals, and accounting. We’ve even had a 12-year old get certified on our education platform.
The level of effort and duration of data science programs varies greatly and depends on an organization's culture. We’ve seen everything from two hours a week for six weeks (12 hours total) to six hours a week for a year (about 35 work days).
Data Mesh Socio-Technical Architecture
Poor data quality can cost a company as much as 20% of revenue. Many companies overreact by excessively cleaning data and imposing harsh governance processes that squash AI innovation. A proven way to strike a balance is to push ownership of data quality out to the edges of the organization to domain experts who best understand the data. This is exactly what data mesh does: It transfers data product ownership from data experts to domain experts. However, for most organizations it’s a difficult cultural change that shouldn’t be underestimated. To paraphrase Tom Davenport: If you think that data and AI will change your business then change will be involved. Organizations that don’t take this view are likely to fail to generate value with AI.
Data mesh is best suited for organizations that have mature data and AI practices and value interdisciplinary collaboration. It’s the newest of the three data culture programs and best practices are just emerging. So far they seem to include what’s been mentioned: mentoring, hackathons, executive immersion workshops, and internal conferences. However, we’ve worked with many organizations that have successfully implemented data mesh and additional practices that are working are to seed the mesh with a few highly curated data products, start small and iterate, domain-to-domain mentoring, self-service data flows, self-service analytics, policy-as-code, and flexible data observability and governance.
What to Remember About the Treble and Demolishing Data Culture Debt
AI technology has changed a lot the past few years and is changing even faster now that Generative AI is delivering a whole new class of commercial models. Some processes have kept pace, notably around data and ML governance (MLOps). However, the people part of the people-process-technology treble has fallen behind causing organizations to accumulate data culture debt that will impede their ability to get value from new AI technologies. To prevent that, we’ve seen successful organizations execute three levels of data culture development programs:
- Data literacy for general knowledge and democratization
- Citizen data science for upskilling and Responsible AI, and
- Data mesh for ownership, accountability, and decentralization
Dataiku has a lot of experience helping our customers develop and execute these programs so contact us today.