




In part one of this series on feature stores and Dataiku, we listed the benefits of feature stores and gave a high-level overview of a feature store implementation with Dataiku. If part one got you excited to try to implement a feature store in your company, this article will provide you with a step-by-step guide on how to get started. We will focus on how to build, store, and serve features in your training or scoring pipelines.

In this article, let’s assume we are a data science team in a credit card company that wants to deploy an array of use cases to prevent fraud on credit card transactions and provide personalized customer service to their merchants based on their profiles and behaviors. As mentioned in part one, there is a significant overlap between the feature set you would use for a fraud detection model and the one you would use for marketing-related use cases. In order to decrease time to value on these models, we’ll centralize our features in a trusted feature store that can be used across teams and use cases for model training and model scoring in production.
1. Setting Up Your Feature Store Connections in Dataiku
The first step is to select our underlying storage for our feature store. Feature stores are typically organized in two parts: the offline and the online feature store. Our offline feature store will store historical values of our features for offline model training and scoring. Depending on how often we’ll want to version our features, this can represent very large amounts of data. Thus, we’ll need to have a scalable and affordable underlying storage like cloud object storage.
For our online store, our main consideration is latency. Since our online store will be used to enrich queries before feeding it to a model in real-time scoring use cases like our fraud detection use case, we need low latency on feature store look-up operations. For this purpose, we can consider using NoSQL and SQL databases.
For this article, we’ll use AWS S3 as our offline feature store and Snowflake as our online feature store, but there are many more options that are natively supported by Dataiku. To let our Dataiku users read and write to these data sources, we can create dedicated feature store connections in Dataiku:
- A S3 connection for our offline feature store
- A Snowflake connection for our online feature store
Having dedicated connections will allow us to easily explore and filter datasets from these connections in Dataiku’s Catalog. Additionally, this lets us control permissions to ensure only our power users group can write features to the feature store while the other users can have read-only rights to the feature store connections.
Once the connections are created and permissions are set, we can start writing features to our feature store!
2. Writing Feature Tables to the Feature Store
Features are typically organized in feature groups and stored inside feature tables. In Dataiku, feature tables can be represented as datasets. A feature group is a logical set of features that is identified by a common reference like our merchant ID. Each feature table consists of a reference column to uniquely identify rows, multiple feature columns, and a timestamp referencing the feature value creation date. Here, we create a feature table named fs_company_fraud with the following columns:
- id_company: This is our reference to uniquely identify the rows
- prev_frauds_by_company: Feature computing the number of fraudulent transactions at this merchant in the past
- avg_transaction_amount: Feature representing the average transaction amount in the past for this merchant
- build_date: Reference date
Each feature table column can be documented with a description in order to provide clarity and let end users search and discover features.
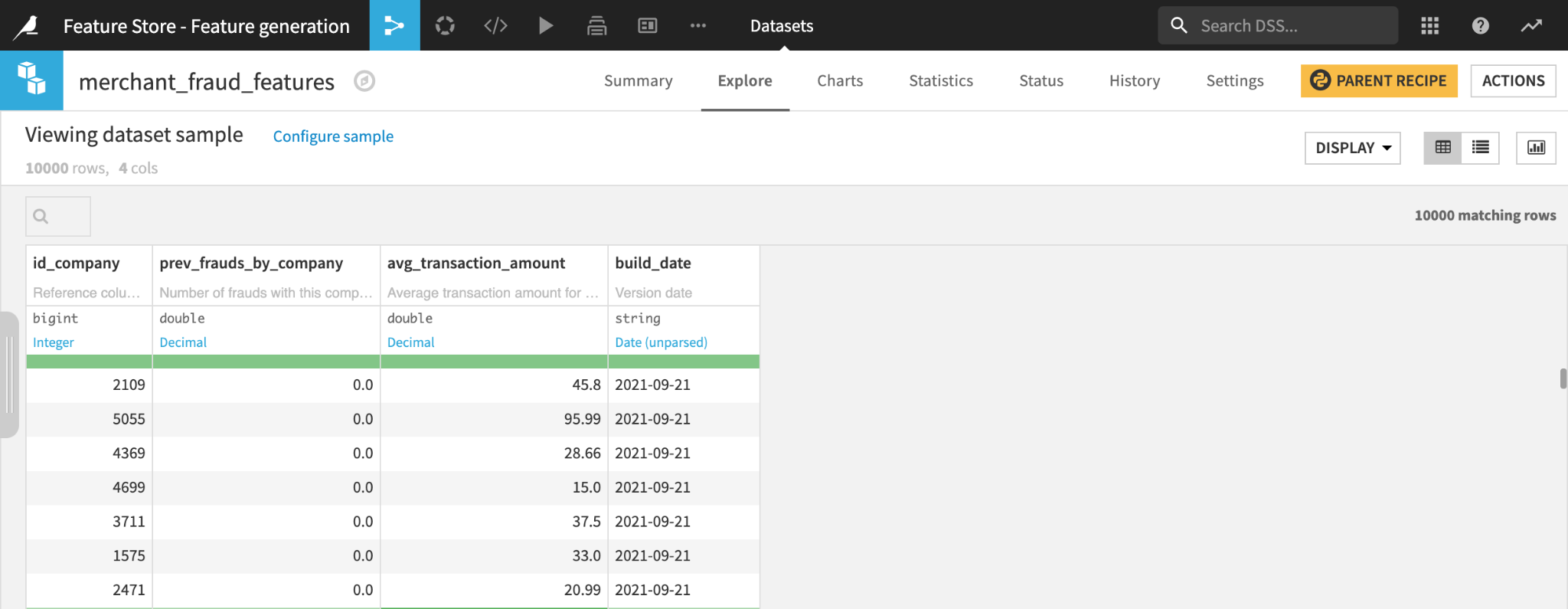
Our feature table dataset in Dataiku
To ingest feature tables into the feature store, our data scientists can leverage the Dataiku Flow to design and orchestrate feature generation pipelines. Pipelines can ingest data from a variety of data sources, including streaming sources like Kafka. Transformations can be defined using a combination of visual and code-based recipes in Python, R, SQL, PySpark, etc. The ability to use various data sources, compute engines, and recipe types inside the same Flow gives feature developers a lot of flexibility in how they design their feature generation pipelines.
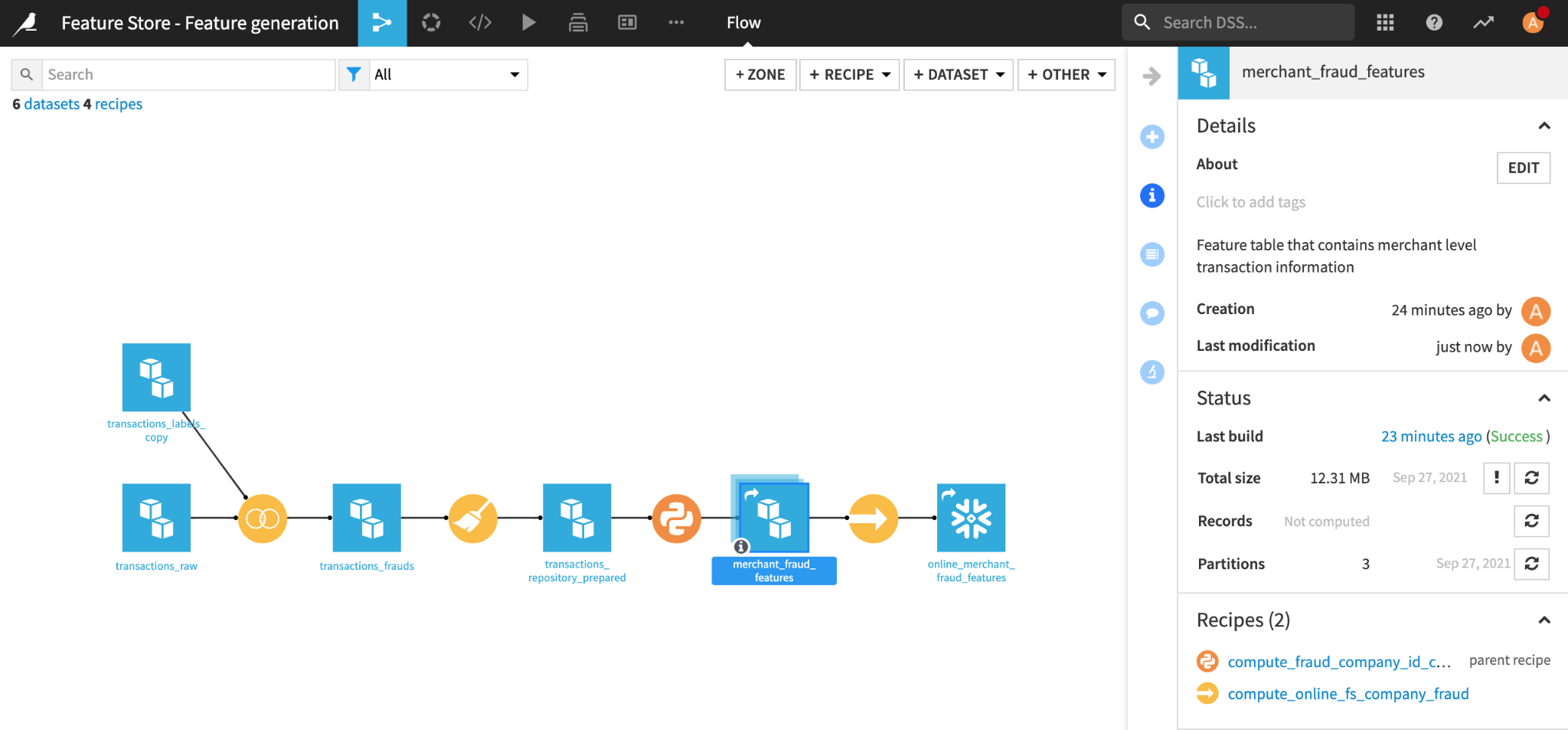
Overview of our feature generation pipeline
3. Using the Offline Store to Store Historical Feature Values
Offline feature stores often require storing point-in-time historical values of features. Indeed, when building their training set, our data scientist should join point-in-time correct feature values to each training example. When training models on temporal data, we want to ensure that the feature values are generated only using data points that precede the event we are predicting for each row in our training dataset. This ensures that we will not introduce any data leakage while training our model. This is called point-in-time correctness and is a key attribute of feature stores. To create our features for our fraud detection training set, we can’t use any transactions that occurred after the date of the transaction for which we have the label (1 for fraudulent, 0 for non-fraudulent).
This is why we need to version our feature values based on the feature creation date. In Dataiku, we can use time-based partitioning on our merchant_fraud_features dataset to allow for what is often referred as “time travel” in feature store lingo.
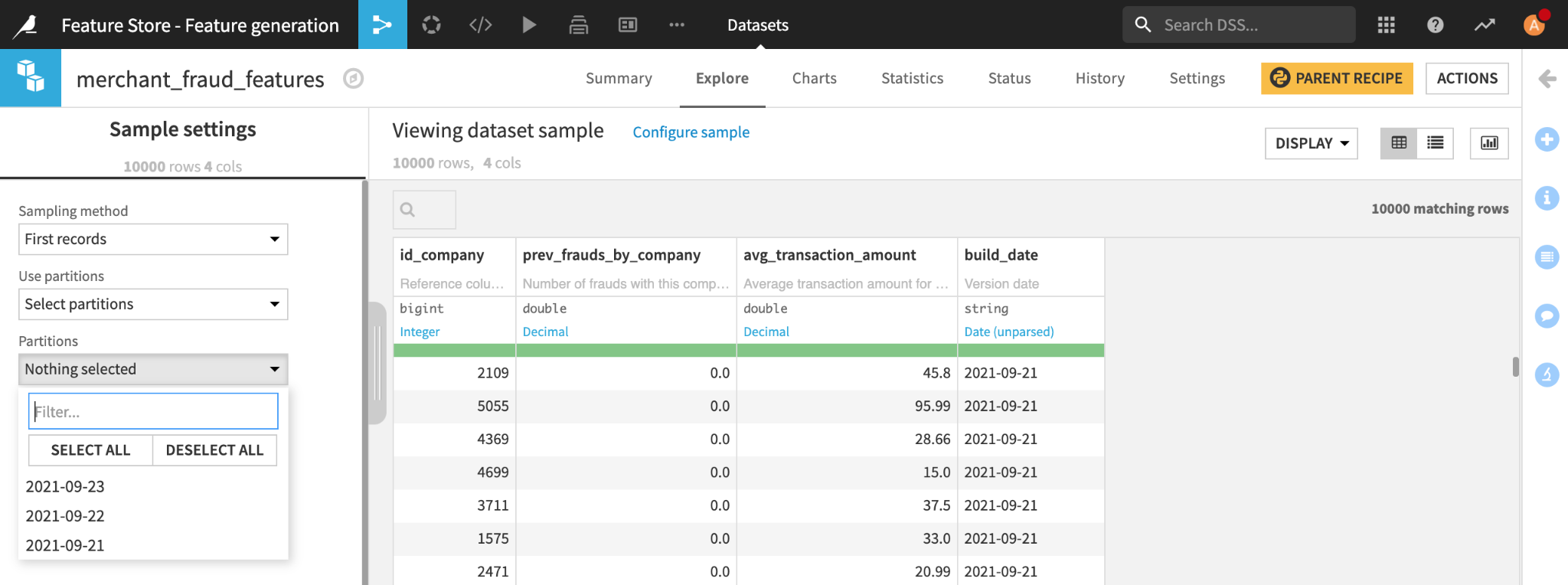
Storing historical versions of our feature table through partitioning
4. Syncing the Online Feature Store With the Latest Feature Values
When performing real-time scoring with our fraud detection model, not all features will be available in the query that is sent to our online model API by our payment system. Features like prev_frauds_by_company typically need to be looked up from a feature table based on the customer_Id. In the real-time scoring case, we are only interested in the most up-to-date feature values.
These up-to-date feature values can be obtained by syncing the latest available data from our S3 offline feature table to our Snowflake online feature table. In Dataiku, we’ll create a Sync recipe in our Flow with our S3 partitioned dataset as an input, our Snowflake dataset as an output, and the “Latest available” partition selection setting.
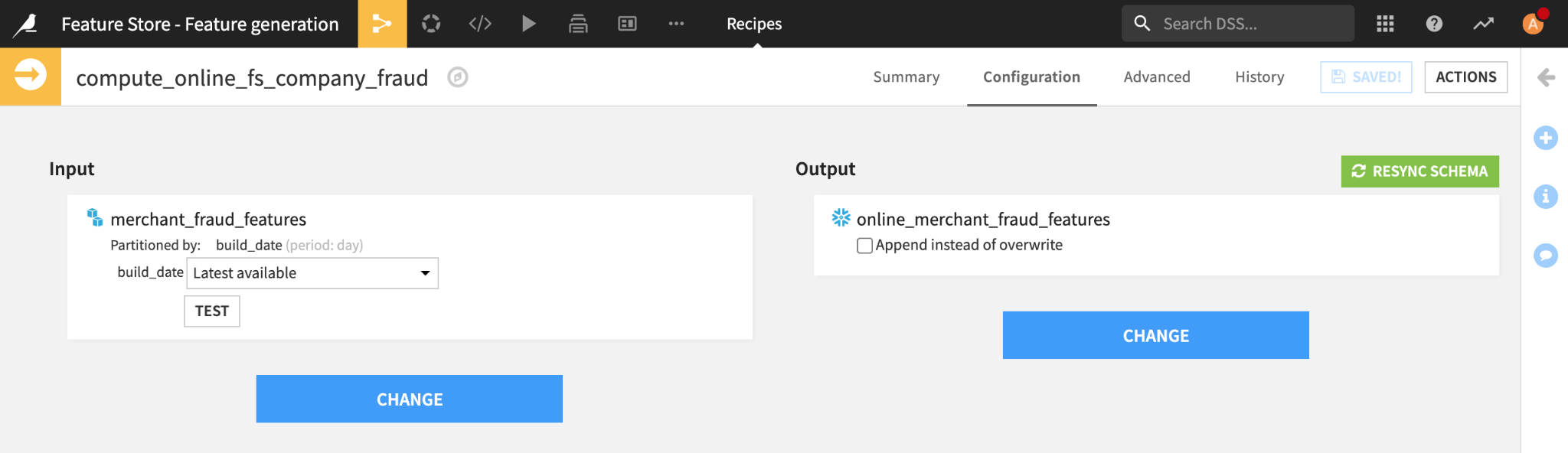
Sync recipe to propagate features to the online feature store
5. Orchestrating Feature Updates
Now that we have our feature generation pipeline, we need a way to update our feature tables in an automated way to ensure our feature values are always up to date based on the available source data. We can do this using a Dataiku scenario, which can either be triggered on a user-defined schedule or based on the availability of new data. In addition to automating the feature table updates, scenarios let you automate data quality checks and alerts to monitor your feature integrity over time and prevent data drift.
For our example, our scenario runs everyday and executes a few steps:
- Execute our flow to build our offline feature table.
- Synchronize the latest available data to our online feature table.
- Run data drift checks on the updated data and send an alert if drift is detected.
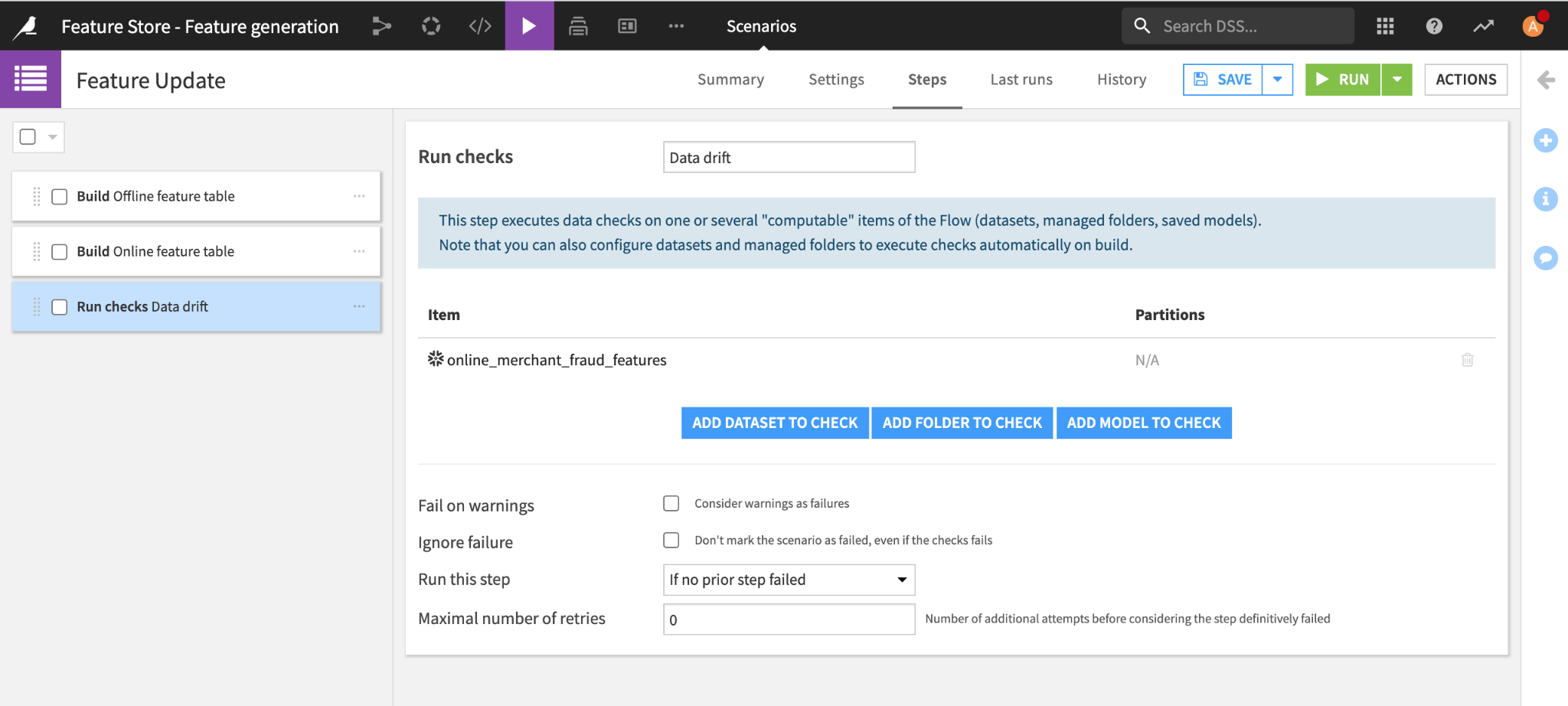
Feature store update scenario
Finally, because the feature tables will be used as inputs to models in production, these orchestrated feature store updates are critical and should be run on a dedicated production environment. With Dataiku’s Deployer, we can easily package our feature creation project as a bundle and deploy it to an Automation node, Dataiku’s production server for batch pipelines.
6. Using Feature Tables Offline to Train a Model
When training our fraud detection model, we’ll want to leverage the features that our team built and that are already available in the feature store. This will save us a lot of time when building our training dataset.
We’ll start from our base dataset with transaction details including date of transaction and fraud/non-fraud label. Next, we can enrich our base dataset with a subset of features from our merchant_fraud_features feature group instead of having to compute them from scratch before training our model.
In Dataiku, this can easily be done by importing feature tables as datasets and using our built-in Join visual recipe to join any number of feature tables from the offline feature store to the master dataset. In order to ensure point-in-time correctness, we’ll add our transaction date and feature creation date as join keys. For each feature table, it is possible to select a subset of columns to join in.
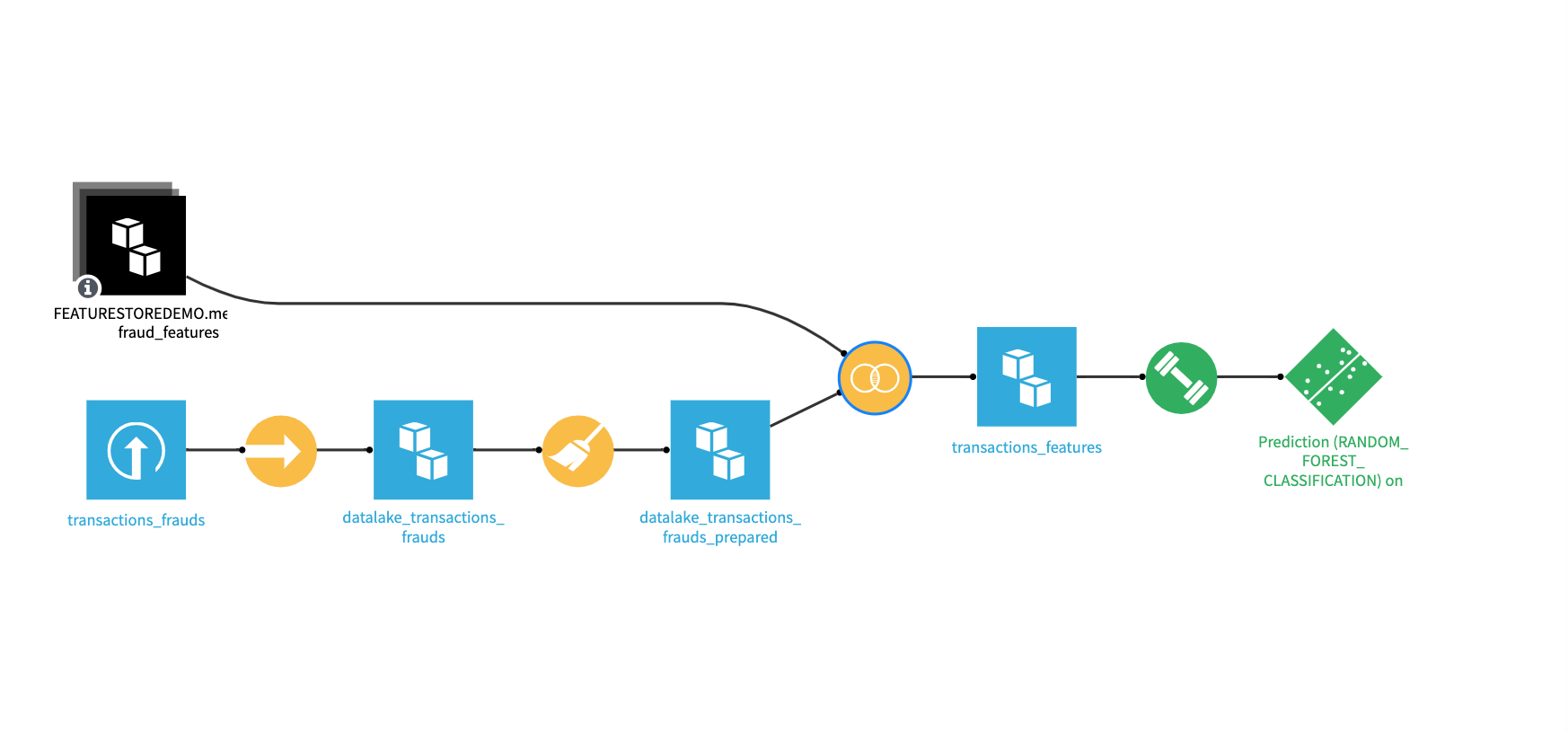
Offline consumption of feature tables through a visual join
Alternatively, we can achieve this through code in a recipe or in Dataiku’s embedded Jupyter notebooks. The Dataiku Python, R, and Spark APIs let you easily load any dataset as a dataframe object and specify dataset columns to load.
Once our base dataset is enriched with features from our feature store, we can use Dataiku’s AutoML features to quickly train and evaluate multiple models. Dataiku’s built-in explainable AI features let us make an informed decision about the model we’ll deploy in production.
7. Enriching Real-Time Queries From the Online Feature Store
Dataiku allows you to author and deploy API services in a few clicks. For example, our trained fraud prediction model can be exposed as an API service to perform real-time scoring. An API service can be made of several endpoints (model prediction, dataset lookup, Python function, etc.). In order to retrieve feature values from a table prior to applying the model, feature store lookups can be added to your API service to enrich the query. The query enrichment can be parameterized to read from the online feature store. Here, we’ll set the lookup key to our id_company and add features to retrieve from the online feature table.
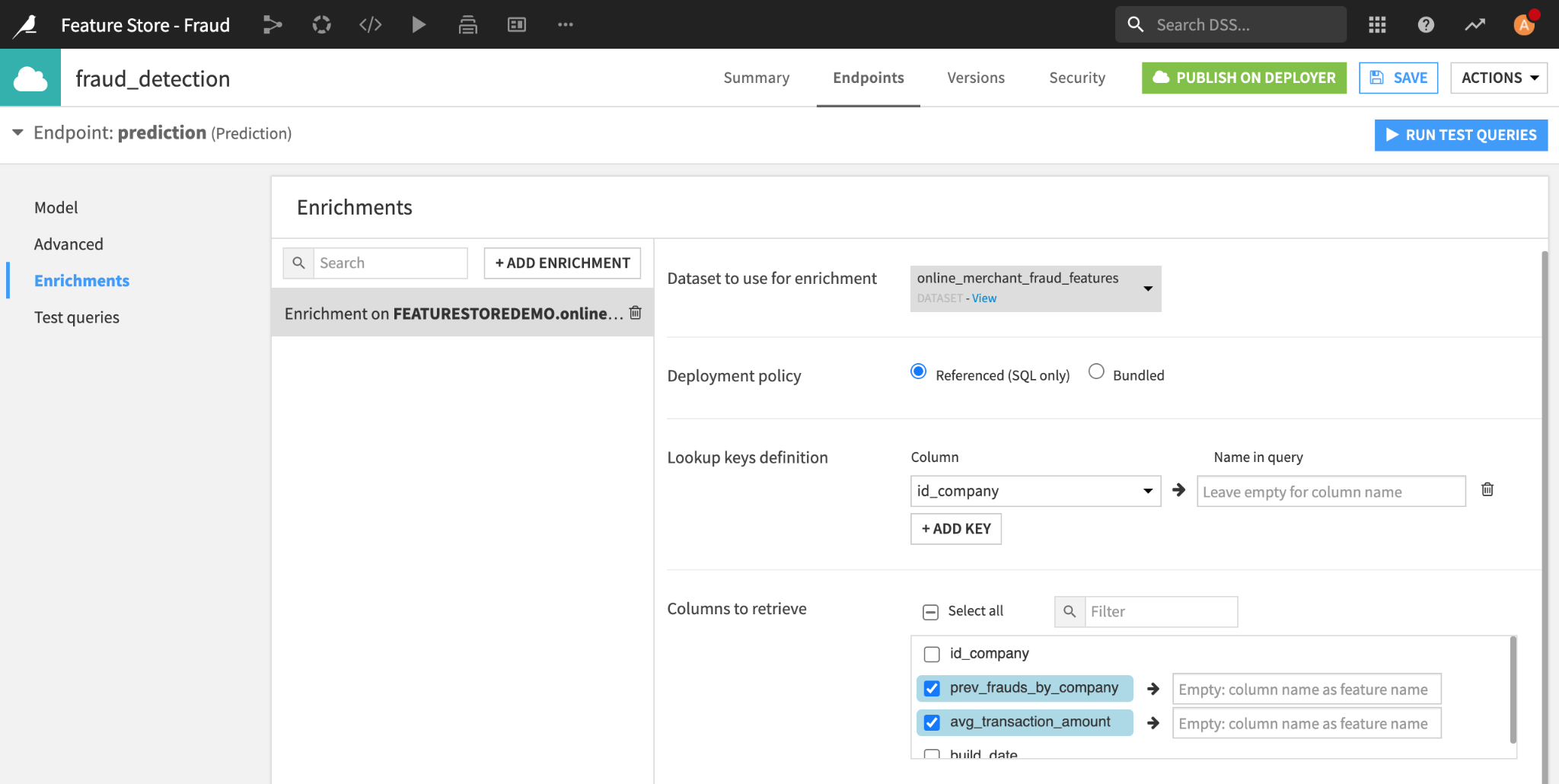
Setting-up Online feature store look-ups through API query enrichment
For some of your model features, however, the values can’t be pre-computed and stored in a feature store. For example, the embedding of a natural language input that is only available at query time would have to be computed in real time and not retrieved from the feature store. A Python function endpoint in your API service will let you do these on-the-fly feature computations. To avoid training/serving skew between your offline and online feature generation code, the Python code used in your endpoint can use the same custom Python library as your offline feature generation pipeline.
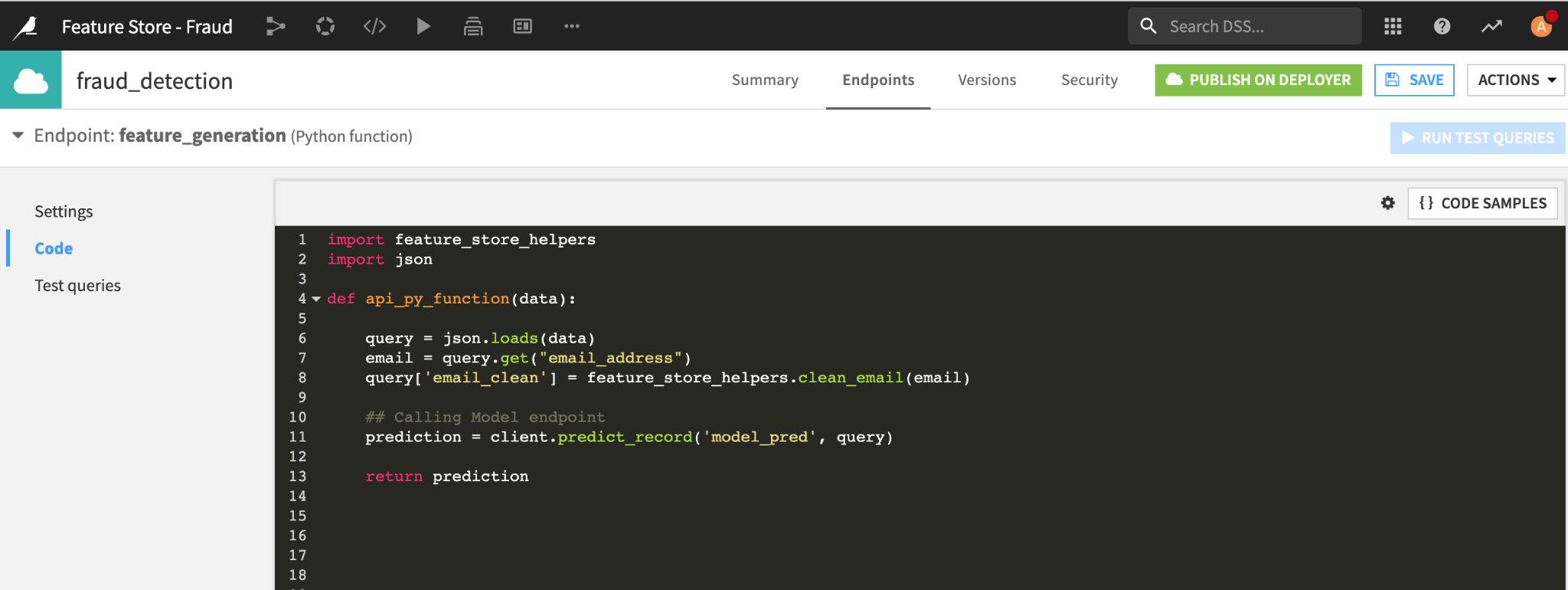
{kind=link}
On-the-fly feature generation code and model prediction using a Python function endpoint and model endpoint
Once this is set up, we can deploy our API service in production using Dataiku’s Deployer and deploy our service on a flexible and elastic compute cluster. We now have a URL that can be called from our payment system to get real-time predictions on each transaction!
It All Comes Down to Reuse
While feature stores are not the end-all-be-all of efficient ML pipelines, they can definitely help reduce time to market on models by ensuring features are easily reused and not built from scratch. Feature stores also mitigate risks of training/serving skew to make models more robust. Dataiku helps organizations achieve Everyday AI by empowering everyone in the organization with AI. On this journey, you’ll find that combining Dataiku with a feature store is a great way to accelerate your journey and bring even more people on board!