





One of the most fundamental concepts to master when getting up to speed with machine learning basics is supervised vs. unsupervised machine learning. This blog post provides a brief rundown, visuals, and a few examples of supervised and unsupervised machine learning to take your ML knowledge to the next level.


Supervised vs. Unsupervised Machine Learning
So when thinking of supervised vs. unsupervised machine learning, what are the key differences?
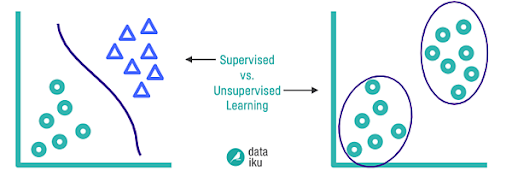
Supervised learning is like having a personal teacher to guide you through the learning process. In supervised learning, the algorithm is given labeled data to train on. The labeled data acts as a teacher, providing the algorithm with examples of what the correct output should be.
Supervised learning is typically used when the goal is to make accurate predictions on new, unseen data. This is because the algorithm has access to labeled data, which helps it learn the underlying patterns and relationships between the input and output data. Supervised learning is also highly interpretable, meaning that it is easy to understand why the algorithm made a particular prediction.
Unsupervised learning is like a treasure hunt — you’re given a map, but it’s up to you to figure out where the treasure is. Unsupervised learning is typically used when the goal is to identify patterns and relationships in data. Unsupervised learning is typically used when working with large datasets where labeling the data may be time-consuming or impractical.
Types of Supervised Machine Learning:
There are two main types of supervised machine learning, classification and regression.
Classification: Classification is a type of supervised machine learning where the goal is to predict which categories or classes new data falls into based on predefined categories or classes.
Regression: In regression, a model provides a continuous output variable based on one or more input variables. The model learns to predict a numerical value, such as price or temperature.
Supervised Machine Learning Use Cases:
Predictive analytics is one of the most common use cases for supervised machine learning. It involves using historical data to predict future events, such as stock prices, sales trends, or customer behavior.
Next, supervised machine learning can be used to analyze and understand human language via Natural Language Processing (NLP). Applications of NLP include sentiment analysis, chatbots, language translation, and text summarization.
Time series forecasting is used to predict future values of a time series based on its past values. For example, to estimate future values in stock prices, revenue predictions, or weather patterns.
Types of Unsupervised Machine Learning:
There are several methods of unsupervised learning, but clustering is far and away the most commonly used unsupervised learning technique. Clustering refers to the process of automatically grouping together data points with similar characteristics and assigning them to “clusters.”
To see a practical example of clustering in action, check out Clustering: How it Works (In Plain English!).
Unsupervised Machine Learning Use Cases:
Some use cases for unsupervised learning — more specifically, clustering — include:
- Customer segmentation, or understanding different customer groups around which to build marketing or other business strategies.
- Genetics, for example clustering DNA patterns to analyze evolutionary biology.
- Recommender systems, which involve grouping together users with similar viewing patterns in order to recommend similar content.
- Anomaly detection, including fraud detection or detecting defective mechanical parts (i.e., predictive maintenance).
Machine Learning in Dataiku
With everything from no code with AutoML, to full code, completely customizable model building, Dataiku makes it easy to involve more people in the ML creation process. Features for model explainability and interpretability mean that you can have a better understanding of model outcomes, understand the impact of different variables on model performance, and proactively monitor results.
 Build models from no to full code
Build models from no to full code
You can also dive into advanced techniques with deep learning, time series forecasting, generative AI, and more.
 Image classification in Dataiku
Image classification in Dataiku