




{kind=link}
This is a guest article from Juan Navas. Navas has a Bachelor's in computer science and a Master's in big data. He worked for several years in the telecom sector on cloud computing, 5G, and micro-service architectures based on Docker containers. He works on blockchain DApps, mainly in Ethereum blockchain, programming smart contracts and leading an ICO for a startup. Recently, he has worked with AI/ML to develop a recommender system for the fintech sector.
A machine learning (ML) project requires data preparation, feature selection, fitting the learning algorithm and training data, and tuning the algorithm to optimize the test data results. In this way, you’re building an ML model to make predictions on new data.
Model optimization tries to improve these predictions. So, when optimizing your model, you need to consider each step and try to optimize the data input to the model, the selection of the learning algorithm, and the algorithm’s performance.
Moreover, although model optimization is always desirable, it comes at no small cost. As you’ll learn throughout this article, the more optimized the model becomes, the more difficult it is to keep optimizing it. Model optimization is indeed a double-edged sword: It can vastly improve your predictions, but it grows ever more difficult and costly.
Benefits of Model Optimization
Whether you’re trying to discover patterns in your data (clusters) using unsupervised learning algorithms, or make predictions via supervised learning, you need to have consistent and accurate results.
Without applying optimization throughout the ML project, the model results will be far from optimal. With unsupervised learning, you may end up with quite unbalanced clusters, where most instances belong to one enormous cluster and the rest to individual “single instance” clusters. This type of result prevents you from detecting any patterns in the data. Similarly, non-optimized supervised learning may produce a high rate of incorrect predictions, making your model unreliable and capable of causing significant harm to your data, clients, and reputation.
The main benefit of optimizing a learning model is that it will produce reliable, high-quality results on new input data. The question is, “How far should you go with your optimization?” As you likely know, the model optimization costs in a ML project are extraordinarily high. Moreover, the more optimized the model is, the more difficult (and costly) it is to optimize it even more.
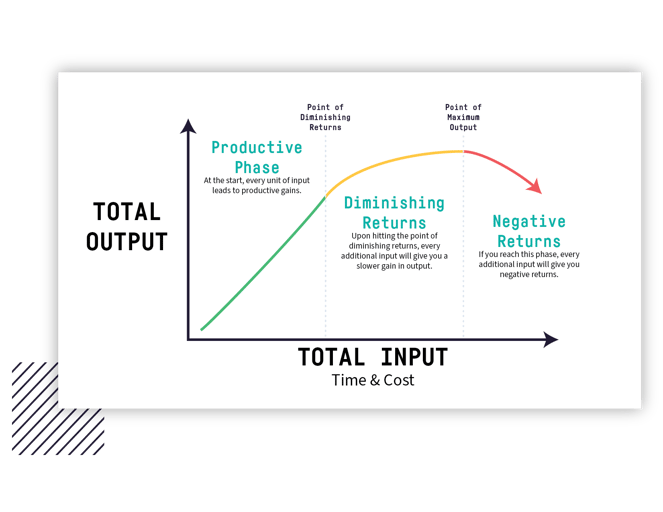
Costs of Model Optimization
When you build a learning model, the goal is to make accurate predictions or discover meaningful patterns based on the available dataset. To achieve that, you need to consider optimization at all the stages of the ML project. Let’s explore them in detail.
Data Preparation and Feature Selection
Data preparation involves data cleansing, where you deal with missing data and outliers. You select the data that you consider useful for the model and transform it into the features you’ll use to fit the learning algorithm. Don’t underestimate this activity, as it can easily be the most time-consuming task in the project.
Data visualization is of great help in this phase. For instance, you can quickly identify outliers or inconsistent data, then decide what to do with them. Once your dataset is in better shape, you can proceed to the feature selection and handling, which is one of the most important steps in an ML project. It greatly influences the result of the learning model. Moreover, it can greatly affect the model’s validity. If the features you choose are insufficient or incorrect, you can disrupt proper modeling methodology (e.g., via data leakage or overfitting) or even violate regulatory policies designed to secure sensitive data like personal identifiable information.
Then, you’ll probably need to fit your model with several feature sets. A feature, meaning a variable to the learning algorithm, may correspond directly to a data variable in the original dataset. It may also be calculated through transformations on the original dataset — for instance, a categorical value to numerical value, a standard normalization of a variable, an arithmetic formula with several original variables, and so on.
Remember that correct data preparation and an appropriate feature selection help to prevent under-fitting/overfitting when training the model. Ultimately, you need to run many iterations with different feature sets and validate the results produced by the learning algorithm. Optimizing the model via the data preparation and feature selection is a computationally costly activity and, if done manually, a time-consuming task.
Algorithm Selection
Another important choice in an ML project is the learning algorithm or a learning pipeline. It’s sometimes difficult to decide a priori which algorithm will perform best. You need to try out several learning algorithms or even pipelines with your feature sets and then select the best one.
This model optimization through the learning algorithm is usually an activity that is performed manually by a data science practitioner, which is time-consuming and certainly costly in computational resources.
Hyperparameter Tuning
Another crucial step in optimizing the learning model is optimizing the learning algorithm. This is done via hyperparameter tuning.
In ML, you must differentiate between parameters and hyperparameters. Parameters are estimated by the algorithm for the given dataset, like the weights for each neuron in a neural network, for example. Meanwhile, hyperparameters are specific to the algorithm itself, and its values for a dataset can’t be estimated from the data (for example, the number of hidden layers in a neural network). Therefore, different hyperparameter values will produce different model parameter values for a given dataset.
So, when you perform hyperparameter tuning, you select a set of optimal values for the learning algorithm applied to your dataset. That set of values maximizes the model performance, ensuring the end result is the best possible result for the learning algorithm.
There are several algorithms to perform hyperparameter tuning, including grid search, random search, and gradient descent. All of them iterate the learning algorithm with different combinations of the hyperparameter values over the training data. As you can imagine, this is a computationally intensive task.
Continuous Model Optimization
Below is a visualization of the activities described so far. The image represents what it means to keep your model optimized.
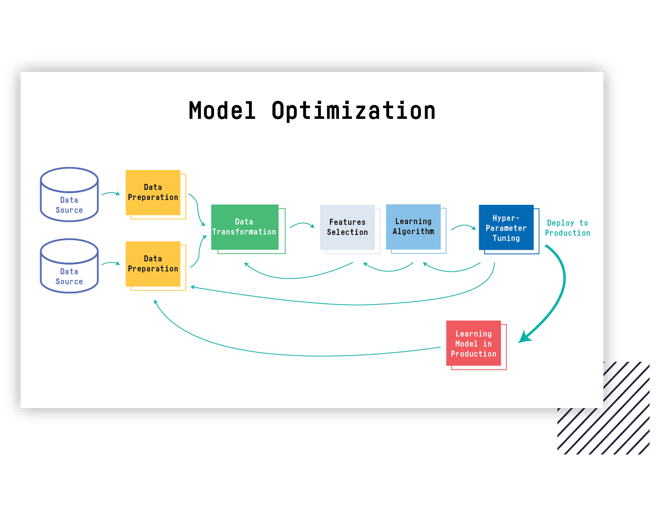
You need to prepare the data from the different data sources and transform it into the features to fit the learning algorithm. Note the iterative loops necessary for the features, algorithm selections, and tune the learning algorithm. These loops are costly not only in terms of computing resources but also in terms of the effort that data science practitioners put forth.
Once your learning model produces effective results, it’s ready to be deployed in the production environment. However, your data sources keep growing with fresh data that you want to incorporate into your learning model, meaning you need to repeat all these steps to keep your model updated and provide optimal results.
Clearly, model optimization is a costly activity in virtually every respect.
Cost/Benefit Analysis of Model Optimization
Forgoing model optimization isn’t really an option. Yet, the more optimization you perform, the more difficult it becomes to continue doing so. And even as improvements diminish with each iteration, costs continue to rise.
Overall, the costs accrue from the practitioners’ combined working hours and the computing resources spent on each optimization phase. The model performance improvements after each phase depend heavily on the learning model itself. Is there a way to find a cutoff point where it is not worth continuing to improve the learning model?
The answer usually depends on the project/organization. How much budget can the project/organization afford to produce the requested learning model? How closely is the learning model performing to the expected/requested model?
Finding the balance between proper optimization and efficient spending is much easier said than done. Part of the answer lies in the reduction of manual task completion. When data scientists have to manually perform repetitive operations, you’re paying both for the immediate tasks and the lost labor and time that could have been spent attending to the core functions of their work. So, you need to find ways to reduce the amount of manual work and aim for optimal efficiency.
For instance, features like Dataiku’s visual flow reduce the toil of the data preparation phase. The Dataiku platform enables you to manipulate and transform datasets, establish data pipelines, and build learning models in an efficient and intuitive way. Dataiku also provides connectors to the industry’s leading data sources, so connecting to a data source is painless.
Additionally, Dataiku offers exceptional exploratory data analysis tools, substantially easing your data cleansing process. You can quickly visualize the missing data and outliers and apply over 100 pre-defined transformations to your data.
Moreover, Dataiku provides AutoML as a comprehensive tool to accelerate the development and evaluation of ML models. You can easily include or exclude algorithms from popular frameworks like scikit-learn or XGBoost during iterative model experiments, and default hyperparameter search settings make it simple to optimize models within business constraints like time or search space limits.
Optimization Still Needs to Be Efficient
In ML projects, success is about building a reliable learning model. And for that, you need to perform model optimization. But its cost and complexity can be restrictive. The more you try to optimize, the more complex and costly it becomes.
For this reason, you need to search for ways to become more efficient and seek to reduce costs through the use of visualization and automation tools. Dataiku’s end-to-end data science and ML platform saves you time, money, and trouble.