




{kind=link}
We met recently with the data culture team of a large, international online retailer. What, you don’t have a data culture team? You should get one. Anyway, the company is a digital native but, like most everyone else, strives to improve their data culture. Their central data team publishes “official” data products and dashboards for things like sales and website traffic. They’re very good at it and have state-of-the-art technology such as massively parallel databases, ETL, and data quality to deal with the velocity and volume of online retail data.
Their reputation grew across the company, so they started receiving data product requests from business units and business functions. The central team hired more team members, but demand exceeded capacity and they fell short of the business’s expectations. “That team became a bottleneck. It was very hard for us. The team was growing very rapidly and that growth was never enough,” a manager told us (emphasis added).
The central team was tech-focused, but to meet demand they needed to get more people involved. Many organizations faced this situation the past decade. A common response was to create a self-service data lake so that 10x more people could create data products. However, many of the data products created were shallow, rarely updated, and the lakes became stagnant swamps that, again, fell short of the business’s expectations. Centralization fell short. Decentralization fell short. As the American troubadour John Melloncamp wrote, “I know there's a balance. I see it when I swing past.” Enter data mesh and a third try at finding a Goldilocks solution.

Cloud-based databases gave us the technology we need. Data lakes enabled the people we need. Now, hopefully, data mesh will give us the processes we need, completing the popular people, process, and technology treble.
The online retailer is well on their way to developing a data mesh, far ahead of 95% of the companies we work with. Their central team has developed 3,000 tables for broad use and self-service users from business domains created another 1,300. They have 20,000 people and 500 production AI models using their data mesh. Now, how to manage it? What are data mesh ops? This article briefly describes three data mesh operations topics we’re seeing: data product metrics, quality and redundancy control, and simple operating rules.
Data Product Metrics: Observability and Reusability as Cultural Values
A common theme heard from IT executives about a data mesh is that it is akin to a software product or platform. We will buy a platform, we implement it like we did our CRM, and then analytics ROI rolls in. On some level, that’s true. There is a certain amount of technology enablement required to remove barriers to entry, to enable business and IT collaboration, and to measure the emergent data products and services that arise.
However, in a perhaps more fundamental way, a data mesh represents the collective wisdom of an organization. Investments in a platform without investment in the culture surrounding the creation and consumption of data are likely to be a proverbial if-we-build-it-they-will-come failure. To get ROI rolling in, companies should manage the cultural shift to a democratized data mesh in which business domain experts reuse data products, create new products, and innovate at their own speed. As with most changes, success depends on how you measure it, how you reward productive behaviors, and how you discourage counterproductive behaviors.
Start with simple measurements. As a brilliant colleague, John Rauser, used to say, “First, we count.” Count your active data products and, for each, its active users, active developers, inputs (fan-in), uses (fan-out), and updates. Data is unlike other resources in that it increases in value with use. Valuable data products are heavily used and provide a robust backbone for the company’s normal operation. A few core products can be combined into new products which span domains and break down silos. Conversely, low-value products have few inputs, consumers, and users. They’re like stagnant ponds waiting to become a swamp. These simple metrics can help you quickly understand the “shape” of your mesh.
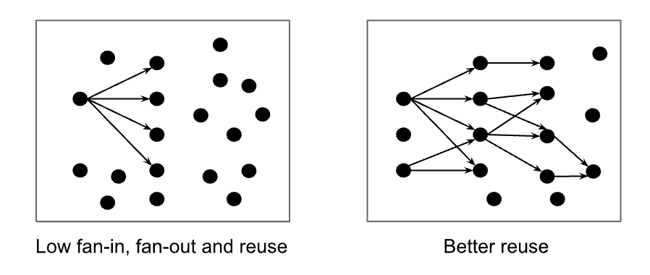
Publish these stats everyday for everyone to see. Create leaderboards, laptop stickers for top producers, internal conferences, hackathons, award ceremonies, and Slack or Teams badges to foster competition among domains, as one would for most any cultural change.
Quality and Redundancy Control
If we do all that then we might generate thousands of data products from dozens of domains and yet fall victim to our own success. Many democratized data lakes fell prey to the tragedy of the commons and destroyed their resources. Data meshes run the risk of doing the same. Here again, simple measurements and transparency go a long way.
Which data products haven’t been updated in two months, six months, or a year? Comparing product age to its update frequency service-level objectives helps to prevent false warnings, but just listing old products is a good first step. For example, sales data might be updated every 12 minutes while executive promotions data is updated every 12 weeks. Also, which products have no users or rapidly declining users? Simple approaches like these have been useful in maintaining corporate wikis and apply to data meshes too.
Data products with many users tend to improve while products with few users tend to deteriorate. Reuse also avoids unnecessary rework and accumulation of tech debt. Thus it’s worthwhile detecting duplicate data products, looking for opportunities to merge them, and consolidate their user bases. Start with tabular data and fuzzy matching to compare data products using Levenshtein distance for column names, Kolmogorov-Smirnov distance for column values, Jaccard index for sets of column names, and Jaccard index for sets of inputs to a data product. Together with a good GUI where administrators and end users can provide feedback (👍👎) by flagging good and bad matches, and machine learning to learn from the feedback, fuzzy matching can help keep your data mesh from becoming bogged down.
Innovation and Adaptation
A third issue that many will need to manage while navigating the cultural change to a data mesh is, “Which data products remain centralized?” Some organizations have a legacy of centralized IT that creates inertia (or dead weight) around centralization, especially in heavily regulated industries such as financial services and healthcare. Again, simplicity and transparency can help overcome this. Consider a case in point from one of our logistics customers. They defined data product risk around three factors: late deliveries, revenue loss, and negative brand impact.
Thresholds and guidelines were published for each, and risk categories created. Then, decentralization rules were agreed to for each category. Domains can do as they please with low risk products, deploying to production any time. Medium risk requires central IT approval, and production high risk products are managed by the central team. They’ll track the number of products in each category and, eventually they hope, use it to track their data mesh maturity. This table summarizes the rules:

Note that these rules are what fit one logistics company this year and are by no means good for everyone. Many mature data companies, for example, no longer even have a high-risk category.
Conclusion
Many large organizations are developing data meshes because data mesh processes are a logical next step in balancing the tech and people of analytics. As meshes start to scale, questions arise on how to operate them. It’s never too early to begin that discussion to prevent building newer and bigger data swamps. Ultimately, a data mesh should be a dynamic ecosystem that fosters innovation and growth while simultaneously providing a robust backbone for company operations. That balance is being achieved by adopting a mindset of measurement and transparency.
The thing which most stood out to us about our conversation with the large retailer was their commitment to making a data mesh cultural shift happen. The data culture team realized they couldn’t “build” a data mesh themselves like one would build a mobile app or ERP implementation. Rather, their role was to measure it, promote it, and help it grow organically.