




{kind=link}
Years ago, I was in a men’s over-40 indoor soccer league. It was a fun way to pass the dreary northern Illinois winters, get some exercise, and hang out with friends. Word got around our small village and our family’s pediatrician asked to join. We said no because he wasn’t as good as Messi. That’s not true of course. He joined and played for years. Our small league in Palatine, Ill. was maybe the 1,000th best in the U.S. and perhaps 100,000th in the world. Messi wasn’t an option.
The same is true for data science use cases. If we had enough data scientists from Stanford and MIT (and business analysts from Wharton and Harvard), we’d use them on every use case. But they’re not an option for most use cases. For those use cases, the common alternatives are intuition, the squeakiest wheel, the highest-paid person’s opinion, and old spreadsheets that nobody understands anymore. Like with my family’s pediatrician, the bar is low. Most companies have thousands of such use cases where AI/ML can add value. I call these long tail use cases and the people who work on them long tail data scientists. This article gives examples in multiple industries and describes two case studies.
Long Tail Distributions
By 2010, Tower Records had closed and iTunes carried eight million digital music tracks. One percent of the tracks accounted for 80% of sales (according to the book “Blockbusters: Hit-Making, Risk-Taking, and the Big Business of Entertainment” by Anita Elberse). Millions of tracks, from bands such as Sordid Pink in Serbia, sold less than 10 copies. I’ve worked with two luxury department store chains where 1% of the customers accounted for 80% of sales.
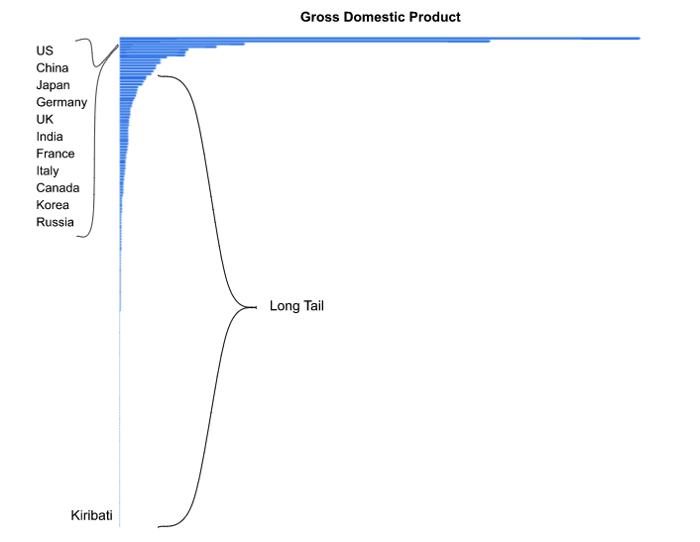
Eleven percent of U.S. cities have 80% of the population. Fifty percent of cities, like Fontana Dam, North Carolina (pop. 10), have less than 1,200 people. Ten percent of countries generate 80% of the global gross domestic product. Kiribati, which is halfway between Los Angeles and Australia, isn’t one of them with a GDP of $200 million. Twenty-two percent of Forbes Global 2000 companies own 80% of the assets of the 2,000 companies with Swedish Match near the bottom at $1.8 billion compared to Fannie Mae’s $4.2 trillion.
Most people have never heard of Sordid Pink, Fontana Dam, Kiribati, or Swedish Match. Those are in the long tail. If you create a chart of band sales, city populations, country GDP, or company assets in descending order, the big winners are on top but the “tail” of smaller ones goes on and on a long way.
The internet is making the big winners bigger but, more importantly, is increasing the diversity in the long tail. The number of music artists to make the Billboard Top 10 from 2010 to 2019 was down 20% from the 1980s (the rich got richer), but the number to make the Top 100 was up 45%. Chris Anderson, former editor of Wired, explained it as, “What’s really amazing about the Long Tail is the sheer size of it. Combine enough non-hits on the Long Tail and you’ve got a market bigger than the hits.” We see that same behavior in data science use cases. There are some monster hits on top, but the long tail of use cases is big and growing. In the next section, I’ll share some examples from consumer credit and retail.
Top Hits and Long Tail Data Science Use Cases
Consumer credits companies had two main AI/ML use cases a generation ago:
- Likelihood to be 90-days delinquent in payment
- Transaction fraud detection
Both were multibillion-dollar opportunities with industry leaders for each, Fair Isaac Corp. (FICO) and HNC Falcon, respectively. Over time, innovators such as Capital One realized that building their own credit and marketing AI/ML models were a big competitive advantage, gained market share, and boosted profits. By 2007, companies were operating hundreds of their own models such as:
- Credit limit
- Interest rate
- Next best product
- Customer segmentation
- Long-term value
- Customer acquisition
- Customer retention
- Favorite marketing channel (paper mail, email, SMS, etc.)
- Favorite marketing message (save money, take a vacation, cash back, etc.)
Retail, like consumer credit, started with a few big data science hits:
They’re still big hits today but have been joined by hundreds of other such as:
- Likelihood of a manufacturer to ship on time
- Likelihood of a shipment to arrive on time
- Estimated arrival date at the Long Beach warehouse
- Should this shipment go by sea or air?
- Customer segmentation
- Store segmentation
- Next best store location
- Product return forecasts
- Store to ship from when buying online and shipping from a store
- New SKU performance based on detailed product attributes
- SKU rationalization
Like the bottom 90% of the Billboard 100 after the internet, we're seeing increased variety in long tail use cases in all industries, driven by readily available data from cloud migration and readily available data science from AutoML. Other long tail use cases include:
- Predictive maintenance for everything from individual valves to oil field compressors to fire trucks
- Customer email classification and prioritization; e.g., billing error, shipment status, billing inquiry, shipment late, damaged goods, etc.
- Rank new-hire candidates
- Rank internal promotion candidates
- Predict the ROI of paid promotions with health and beauty social media influencers
- Forecast the demand for new candidate restaurant menu items
- Forecast my AWS bill for this and the next 12 months
- Predict the best time to call back a telco customer who needs help
- Classify evidence in immigration cases
Long Tail Data Scientists
People who work on long tail data science use cases have been called citizen data scientists. Professional data scientists warn of risks with their work. Similar things were said about literacy, textile machinery, automobiles, women voting, desktop computing, and spreadsheets. There are viewpoints other than professional data science to consider. Business managers are often more concerned about whether results are better than the previous method rather than whether they’re better than professional data science. Can citizen data science outperform intuition, highest paid person’s opinion, or hundreds of tightly coupled spreadsheets that nobody understands? A banking executive recently told me that she was sick and tired of basing major decisions on intuition and that she wanted more data science, any data science, citizen or otherwise.
We’ve seen citizen data science perform well in many industries. Two quick examples are energy and logistics. BP made energy buying, selling, and shipping decisions using 140 linked Excel workbooks with over 500 tabs. By replacing the basic calculations with automated data pipelines and quality assurance checks, domain experts could work on higher value analytics tasks.
Ericsson operates warehouses globally. To optimize their use, they need good estimates of the space available in each based on its current inventory. That calculation is simple for most products. For example, if an item comes in a 1 foot by 1 foot by 1 foot box then up to 64 units will fit in a 4’x4’x4’ storage shelf. However there are many irregularly shaped items where that does not work so a citizen data scientist used historical data and machine learning to estimate the space used. Ericsson and BP are two of many success stories. For more stories written by the citizen data scientists themselves, see our Community website.
A second viewpoint to consider is the citizens’. Key drivers of worker retention, performance, and happiness are staying current with skills development (like data science), doing meaningful work (such as modernizing data pipelines rather than hacking 500 spreadsheets), and making an impact (like optimizing warehouse utilization globally). Citizen data science checks all three.
Of course, not every knowledge worker will acquire, apply, and retain data science skills. Large-scale upskilling programs can increase your odds but technology adoption progresses through companies just like it progresses through industries: A few innovators grab on first, early adopters are next, followed by the middle majority and laggards. Our experience is that about 50% of candidate “long tail” data scientists acquire data science skills, and 20% retain and apply them over time. That’s huge, resulting in thousands of new data scientists that would be impractical for most companies to ever hire. And even if you could hire hundreds, they’ll never all be Messi.