




Data drift is more important than ever. The COVID-19 health crisis has brutally reminded us that, to paraphrase French chemist Antoine Lavoisier: nothing is lost, nothing is created, everything is transformed. In a context marked by multiple and repetitive lockdowns around the world, online commerce has exploded faster than expected. Like merchants, consumers have abandoned cash, and organizations have digitized communication systems to support the unexpected rise of remote work. International shipping is in chaos; freight costs are skyrocketing, and supply chains often become unpredictable.
Who could have foreseen such profound changes would happen so quickly? And now, in 2021, who would rely on 2019 pre-COVID-19 data to predict the 2021 buyer online shopping experience? According to Gartner®, "Data drift profoundly degrades the quality of machine learning models and, consequently, the predictability induced by them. As a matter of fact, upon discovering drift in datasets, some enterprises were forced to stop operationalizing machine learning models."*
What Is Data Drift? Is It Something New?
Data drift is a comparison between two versions of the same dataset taken at different times. When looking at a histogram of values for a particular column, if the two histograms do not overlap significantly, then the data for that variable is said to have drifted. This drift shows the change in the composition of the data. If that data provides a signal for significant features in a predictive model, then the drift could cause the model to be less accurate.
Data records people, customers, and organizations' evolution. As such, it's natural that datasets may degrade over time. Data drift is then inherent to a dataset. It is indeed one of the classic data quality issues that is important to address on an ongoing basis. Data quality is often described with six dimensions such as accuracy, completeness, consistency, timeliness, validity, and uniqueness. Timeliness is often the one that causes data drift. It's also probably one of the most difficult to address because data teams need to constantly supervise it at different phases of data usage.
Why Is Data Drift Important?
Data powers our insights, so changing data could lead to different or inaccurate insights. The rapidness of digital transformation coupled with data and AI innovation pace has created complex, diverse, and even bigger datasets. And the problem has mechanically gained in importance. As previously mentioned, the COVID-19 health crisis has made it worse, impacting demand and customer behavior machine learning models.
In the meantime, predicting customer behavior or operational maintenance has become increasingly complex so that existing outlier detection and data profiling techniques cannot meet demanding needs — without mentioning the growing number of data workers that want to use, validate, or control them.
According to Gartner®, "Every year, poor data quality costs organizations an average $12.9 million."** Your machine learning projects are pumping your customer experience, your cost optimization plan, and your innovation. Therefore, it’s vital to take control of data drift as you'll need to maintain data and model accuracy over time.
How Can You Do It in Practice?
Monitoring and supervising the evolution of data drift is crucial when you want to industrialize your machine learning processes. Implementing an MLOps approach is a perfect way to take back operational control of data drift to monitor and alert the importance of data drift.
This allows you to alert the data manager or the data engineer of the existence of a drift or even to anticipate it as much as possible before the problem gets worse and forces you to pull the plug on a machine learning model. However, monitoring ongoing data drift in production can be time-consuming and laborious for data teams — and periodic, manual spot checking is an inadequate solution to detect emerging issues at scale.
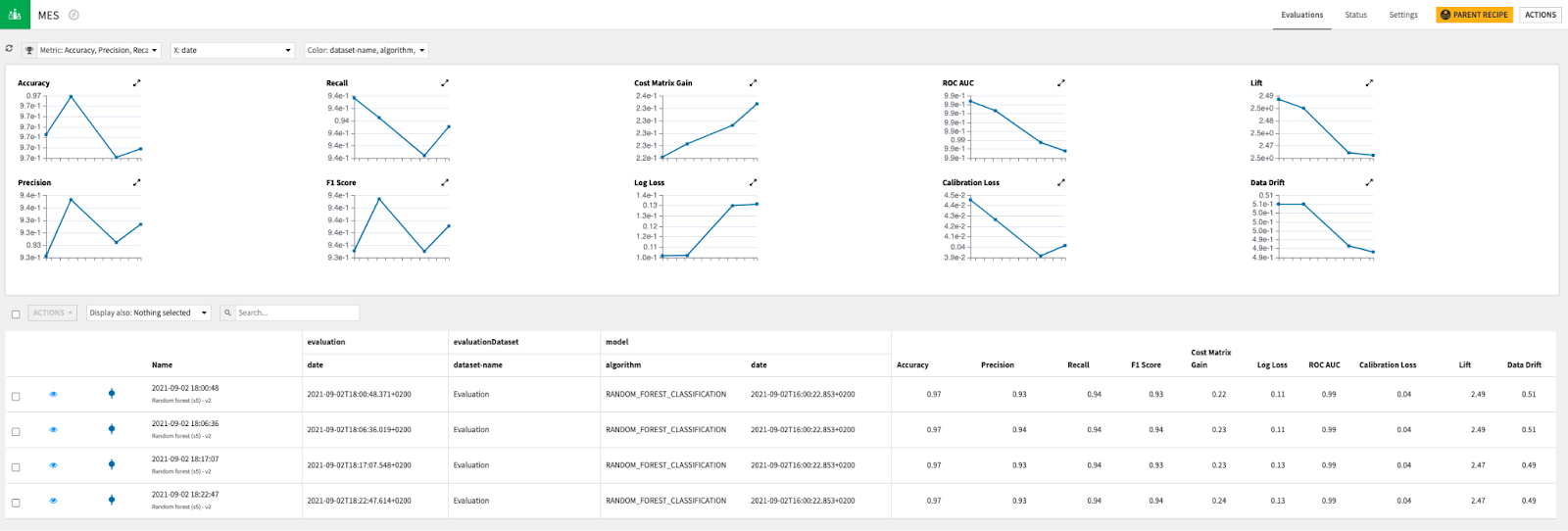
With its latest release, Dataiku helps data teams to perform automated checks and monitoring on deployed models that alerts operators to potential performance or input data drift. Plus, implementing controls and monitoring of data and related models is a critical imperative in the maturity progression of your AI applications. This will allow you to prepare your compliance in the future regulatory frameworks around AI and show that AI remains under control in all circumstances.
{kind=link}
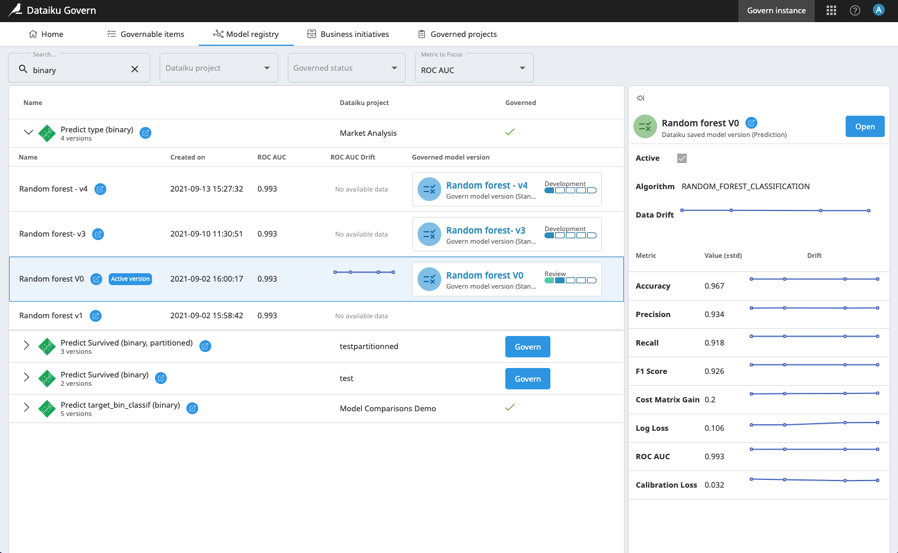
As such, Dataiku AI model and project governance capabilities helps expert and risk managers track and monitor data drift as a key element in validating or invalidating the deployment of ML projects into production.
The Value of Drift Monitoring
There are alternatives before violently pulling the plug on your machine learning models. Being able to identify drift, whether it is related to the input data or the model itself, is the first step. Monitoring drift over time in a way that is accessible to different audiences is an undeniable asset for the ongoing monitoring and efficiency of your machine learning projects. This way, data teams can be alerted in advance to correct it and all the AI projects can continue being deployed with confidence.
*Gartner - Key Actions to Prevent Machine Learning Failure Due to COVID-19-Related Data Drift, Alexander Linden, Erick Brethenoux, 3 July 2020
**Smarter With Gartner - "How to Improve Your Data Quality" - Manasi Sakpal, July 2021, (https://www.gartner.com/smarterwithgartner/how-to-improve-your-data-quality) GARTNER is a registered trademark and service mark of Gartner, Inc. and/or its affiliates in the U.S. and internationally and is used herein with permission. All rights reserved.