




In January, our Dataiku Lab team presented their annual findings for up-and-coming machine learning (ML) trends, based on the work they do in machine learning research. In this series, we're going to break up their key topics (trustworthy ML, human-in-the-loop ML, causality, and the connection between reinforcement learning and AutoML) so they're easy for you to digest as you aim to optimize your ML projects in 2021. We've already tackled trustworthy ML and human-in-the-loop ML, so up next is a summary of the section on causality and ML, presented by Léo Dreyfus-Schmidt. Enjoy!
Léo Dreyfus-Schmidt:
If you were with us last year and the year before, you're probably thinking, "This guy keeps on talking about causal inference every year." I think this year, we want to show that we have even more faith than in the previous years and even more elements to illustrate why this is a great time to get into causal inference. The first thing we wanted to introduce in the field of causal inference is to go from prediction setting to prescription. So it's really getting closer to decision making.
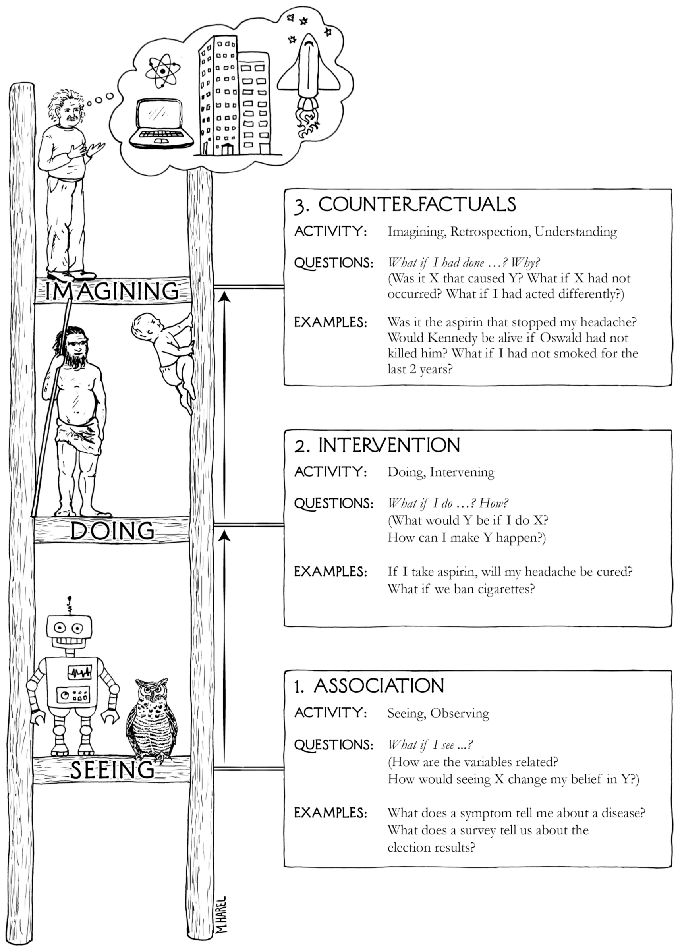
If you're familiar with machine learning, you know that some use cases are churn prevention, fraud detection, and predictive maintenance. All of those are trying to predict some kind of event happening, but it's not about actually intervening on that event. It's not about asking questions such as, "What would happen if I do this action." So for instance, in a dynamic pricing scenario, if you use machine learning, you're not really asking yourself the question, "What will have happened if I raise my prices? Will I still have the same number of bookings, can I have higher prices?" Things like that. So as soon as you want to intervene on the system, on the environment, technically it's moving away from the typical IID setting of machine learning, we are in the unknown. One way to quantify that, one way to get this is for structural relation. This is what causal inference is aiming at providing. What you can see below is a nice representation of what is called the ladder of causation, which you can find in the Book of Why by Judea Pearl, one of the founding fathers of causal inference.
{kind=link}
Once again, I'm happy to advertise for the book. It's for a general audience, so everybody can listen to this. And it really tried to make the case for what traditional machine learning is doing. At the first level where you see the little robot, it's where ML operates. This is what you see and where we want to go is higher. And the doing level is actually making intervention. And I'm not going to even talk about the higher level, which is even harder to actually imagine, which is called imagining, and it's the realm of counterfactual. So this is basically what we mean by the causal inference. It's about understanding what happens when I want to intervene on a system.
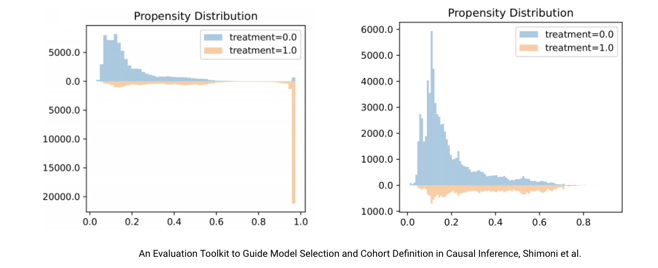
The first proof we want to give you now as to why we think that causal inference is here to stay, and it's not just a passing trend, is we're seeing more and more work on understanding the hypothesis behind the models. You see, if you want something as strong as a causally aware model, you need to make some assumptions and you need those hypothesis to be valid if you want to see them robust in the field, once you can apply them and actually do those actions. Let's take one example. One example of such hypothesis is called the positivity assumption. What it say is everybody is as likely to get my action.
So let's see a concrete example. You want to give a discount to your users. So Xi are our set of feature describing the user and Ti is whether you give or not a discount or the amount of discount you give to someone. If you truly want to learn what is the impact of giving a discount to your user, you need to have that hypothesis, which means everybody within the same level of feature Xi is likely to get or not get the action. What you can see below is extracted from a paper from IBM, which is coming with a nice Python toolkit called causal lib, and it's about measuring precisely whether those hypotheses are valid or not. If they are not, you need to take some step to break things to fix the public (the user that has been treated) and if they are, you can go ahead and try to implement this technique.
Causal Inference Maturity Is Increasing
So this is the strong argument we wanted to present you today as to why we think that causal inference is being more and more mature. Of course there are other elements that made us believe that... such elements as we see more and more companies publishing works. So I've just put some name of all company that actually not only publish research work, but also all of them has been publishing actual code, actual implementation, actually getting feedback of their use cases — Netflix, Uber, Spotify, Microsoft, and Wayfair, for example. So it's very, very thorough. And I think it's a very good example and good source of inspiration. On the research side of things, there were many major machine learning conferences that had causal learning and causality-based workshops, so we think it's going to be here to stay.
There's a lot of interaction and intersection between causal inference and over machine learning domain. As Alex talked about, it's connected to representation and environment and equivariant representation is connected to disentanglement. As Simona spoke earlier about interpretability, robustness and trustworthy ML is also connected to something as counter factual interpretation and prediction. So we really see that causal inference has many roots within already existing machine learning columns and we are hoping to see that more and more people will be using those techniques.
And last but not least, we've been playing a lot with some of these frameworks. The good example is we've been changing a little bit the use of scikit-learn, which I'm sure everybody here is very much aware of and it's become an industry standard and using a framework such as causalML, which is a Uber open source solution. And as you can see, basically without getting into much detail, changing slightly the structure of the classic fit predict interface by not only having a set of feature X and a target Y but also adding a treatment T...T for treatment, but think of it as being an action. So that's all I wanted to talk to you about today that causal inference and machine learning. Don't worry. Next year I'll be here again, and I'll be talking again about causal inference and machine learning, and I hope we'll have even a stronger argument, and perhaps we at Dataiku will have been a part of its active development.
