




In the prior posts in the How They Work (In Plain English!) series, we went through a high-level overview of machine learning and explored two key categories of supervised learning algorithms (linear and tree-based models), two key unsupervised learning techniques (clustering and dimensionality reduction), and recommendation engines which can use either supervised or unsupervised learning. Today, we’ll dive into Natural Language Processing (NLP), which overlaps with each of these topics in different ways.
NLP is a subfield of AI that enables machines to understand and derive meaning from human language. Research over the past decade has greatly improved the function and utility of NLP in our everyday lives; some key use cases include speech recognition (as seen through Siri & Alexa), automatic language translation, sentiment analysis, fake news identification, and chatbots.
Before we dive into the details of how it all works, we should take a minute to think about the challenge of NLP, which always reminds me of the movie “Arrival.” If you haven’t seen it, it’s about linguistic researchers tasked with developing a method of communicating with aliens who communicate with one another by blowing smoke into specific formations into the air and have recently landed on Earth.
The premise of the movie hinges on the idea that language is incredibly complex and has a grave impact on our perception of reality — in the absence of a wide vocabulary of adjectives, we may not be able to articulate or even understand all the nuances of our emotions. On top of this, it touches upon the concept that literal language only goes so far, and to really understand one another we must understand metaphorical language, sarcasm, facial expressions, and much more.
So, in order to communicate with the aliens, the linguists must convert English into something the aliens can understand. Not only is this a translation into another language, rather it’s a translation into another dimension of language, as the aliens don’t understand facial expressions or hand gestures, and certainly don’t inherently understand spoken language.

The challenge of NLP is similar in many ways, as it involves converting spoken or written language into something a computer can understand — a numerical format, which I’d venture to consider another dimension of language. This is quite a challenging task due to the complexities of human language, but, in this post, we’ll dive into the fundamentals of how it all works, including:
- Text cleaning
- Text vectorization (conversion into a numerical format)
- Key NLP techniques
Text Cleaning
While it may seem unexciting, text cleaning is one of the most crucial tasks in any NLP project. Almost any machine learning task begins with some level of data cleanup, but text data is typically much more complex and challenging to clean than numerical or categorical data, as it is much less structured. Text cleaning falls into four main categories: normalization, stop word removal, stemming and lemmatization, and tokenization.
Normalization
Normalization refers to the removal of general noise in text, which might include things like converting all text to lowercase, removing punctuation, correcting typos, or removing miscellaneous noise (e.g. unneeded dates and numbers or HTML tags). This sort of miscellaneous noise removal is particularly helpful if text has been generated via web scraping or PDF parsing, which can result in messy output datasets.
Regular expressions, patterns used to match character combinations within strings, can be helpful in detailed pattern searching if we’re working with text that conforms to certain predefined structures, such as user IDs or dates.
Normalization (Lowercasing & Removing Punctuation):
I love running outside in the Summer! → i love running outside in the summer
Tokenization
Tokenization refers to the process of breaking long text strings into tokens, which are typically words but can also be bi-grams or tri-grams — groups of two or three words, respectively. If we were to perform unigram tokenization on the phrase “Thank you so much,” we’d end up with a list containing four tokens: [“Thank,” “you,” “so,” “much”]. With bi-gram tokenization, however, we would end up with a list of three tokens: [“Thank you,” “you so,” “so much”].
When two or three words combined hold a different meaning than they do alone, bi-grams or tri-grams ensure that we capture the meaning of the group of words, rather than each word individually, as “you” alone holds a very different meaning than it does when it follows the word “thank,” for example.
Tokenization is the first key step in transforming text into something a machine can understand, and all tokens are then used to prepare a vocabulary. Each word in the vocabulary is then treated as a unique feature, which is essential if we want to ultimately convert text into numerical values to feed into a machine learning model.
Tokenization:
i love running outside in the summer → [“i,” “love,” “running,” “outside,” “in,” “the,” “summer”]
Stop Words
Stop words are common words in a language that hold very little information, and removing them doesn’t compromise the meaning of a sentence. For example, some key English stop words include “in,” “the,” and “so.” For many NLP techniques, stop words don’t provide much helpful information, and removing helps to reduce noise in your model.
Stop words can also be customized to your dataset; for example, in a corpus of food recipes, “tablespoon” and “cup” might not actually be helpful words and might be considered custom stop words. It’s important to keep in mind that removing helpful words can be quite dangerous, so it’s typically best to err on the side of caution when removing custom stop words, and ensure the subject matter experts are involved.
Stop Word Removal:
i love running outside in the summer → love running outside summer
Stemming and Lemmatization
Stemming and lemmatization refer to two methods of reducing words into their base or root form, in order to convert all terms into present tense. This ensures that the words like “run” and “running,” for example, are considered to be the same word since they have the same core meaning.
Stemming simply refers to stripping all suffixes of a word; for example, the word “assigned” would be stripped down to “assign.” Stemming is quite rudimentary and is computed quickly. For words which follow standard rules of their language’s grammar, this tends to work well. However, not all words do.
Lemmatization deals with more grammatically complex words by considering a morphological analysis, and reducing a word into its dictionary form, or lemma. For example, “being” would be reduced to “be,” but so would the words “was” and “am,” as they have the same core meaning even though they begin with different letters. Stemming would only convert “being” and “been” to “be,” and “was” and “am” would remain untouched. Lemmatization is more complex and sophisticated, but it is much more computationally expensive than stemming, which can be a challenge with very large datasets.
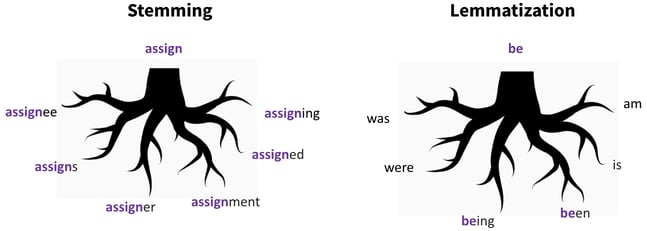
Stemming/Lemmatization:
love running outside summer → love run outside summer
This sentence is the same with stemming and lemmatization, as “run” is the lemma as well as the stem of “running.”
Vectorization
Before we can feed cleaned and tokenized text into a machine learning model, we must convert it into something a machine can understand — numbers. This process of converting text into numerical values is referred to as vectorization.
There are a handful of ways to do this; some of the most commonly used methods are count vectorization, TF-IDF, as well as newer word embedding methods such as Word2Vec. As with many decisions throughout the lifecycle of a data science project, the best method is dependent upon the use case and dataset at hand.
Count Vectorization
Count Vectorization, also known as Bag of Words, is far and away the simplest method of vectorization. It simply counts the number of occurrences of each word within a document. If a word appears once in a document, its feature column will have a value of one, if it appears twice, it will have a value of two, and so on.

The cleaned and tokenized texts [“run,” “yesterday”] and [“love,” “outside,” “run,” “summer,” “yesterday”] would be converted into five columns with word counts like above.
If you’re familiar with one-hot-encoding, count vectorization is quite similar, but rather than dummifying a categorical column, we’ll transform a text column into word counts.
TF-IDF
Term Frequency-Inverse Document Frequency, or TF-IDF, takes count vectorization one step further. It measures the originality of a term by multiplying term frequency (TF), or, how many times the term exists in a document, by inverse document frequency (IDF), or, the frequency of that term across all documents in the corpus.
This ensures that terms which appear frequently in a corpus, or entire collection of documents, are weighted less heavily as they will probably be unhelpful in categorizing documents. For example, if we have an entire corpus of articles about running, the word “run” is probably not going to help us in any way, so we’d want to weigh it less heavily.

In both lines, the word “run” is weighted the least heavily, since it appears in both documents.
TF-IDF is helpful in understanding originality, but it still does not capture context, or meaning. If the words “happy” and “run” appeared with the same level of frequency in a document and corpus, they’d have the same TF-IDF score, although the meanings are of course quite different.
Word Embeddings
Fortunately, research within the last decade has allowed us to capture context more explicitly through word embeddings, which use neural networks to generate vectors for individual words. Rather than just using one number to represent a word, we’ll now have a vector, or a list of numbers.
Word2Vec was the first word embedding algorithm, developed by Google in 2013. Word2Vec looks at past appearances and surrounding words to generate a vector for an individual word, in order to ultimately generate a vocabulary of words and associated vectors. These vectors are numerical representations of context, and can be queried to compute similarities mathematically. If you missed the last post on recommendation engines, check out the discussion of cosine similarity; the idea is the same with text, as we can compare similarities of words by computing the cosine of the angle between the vectors.
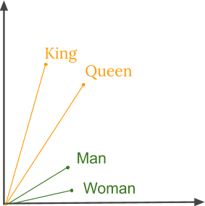
Word2Vec allows us to compute similarities mathematically; for example, we can say “King” - “Man” + “Woman” = “Queen.”
There have been many other recent developments in the world of word embeddings, such as:
- Glove, which emphasizes the frequency of co-appearances
- FastText, which is an extension of Word2Vec but also considers parts of words
- ElMO which enables words to have different word vectors depending on the use within a sentence
- Transformer Models, such as BERT & GPT, which look bi-directionally, so rather than reading only from left to right, they read in both directions which allows for increased accuracy and speed, thanks to parallelizable training.
Advancements in NLP in recent years have been largely tied to improvements in word embedding methodologies, and these advancements have opened doors for much more efficient and accurate processing of speech and text data.
NLP Techniques
Once our text has been cleaned and vectorized or embedded, we can perform a wide array of machine learning techniques to generate some type of meaning from our text. The technique we’ll use really depends on the business problem we want to solve or the type of text we want to process. We’ll explore text classification, sentiment analysis, and topic modeling. Note that there are many other NLP techniques out there, but these are three of the most common and straightforward to understand.
Text Classification
Text classification simply refers to using vectorized or embedded text as an input to a classification model, in order to predict the category which a document belongs to. For example, let’s imagine we want to predict whether or not an email is spam. We can train a model to look at numerical features like the number of emails received from this sender in the past, categorical features like the sender or day of week, as well as text features like subject line and email text. These text features would make use of the text we vectorized or embedded in the prior step.
We’ll then train a regular classification model, and the numerical representation for each term is now a feature in the model. We can use any classification algorithm, including some of the ones we’ve discussed earlier in this series, such as logistic regression or tree-based models. There are also some other algorithms such as naive bayes which are even better suited for certain text classification tasks, due to the algorithm’s assumptions.
Sentiment Analysis
Sentiment analysis is a method of algorithmically determining sentiment associated with an input text. This can be helpful for tracking brand health over time or identifying key promoters or detractors of your product. Sentiment analysis is particularly useful in the analysis of social media data and can be used to track reactions to a big event, such as a buzz-worthy new ad campaign.
The most common method of performing sentiment analysis is actually via a fairly simple rules-based approach, using a python package called TextBlob. TextBlob leverages a custom English dictionary, WordNet, which contains polarity and subjectivity scores for each word. Polarity ranges from -1 to 1, and provides a measure of how negative or positive a sentiment is, while subjectivity ranges from 0 to 1 and provides a measure of how factual or opinionated text is.
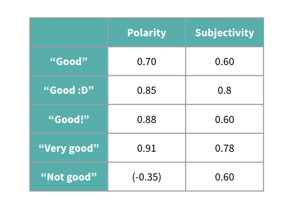
Polarity scores for variations of the word “good.” TextBlob accounts for preceding words or punctuation to adjust the polarity and subjectivity scores, so a negation word like “not” reverses polarity, whereas adverbs like “very” increase the magnitude of the polarity as well as the subjectivity.
Since WordNet provides us with a numerical representation of each word, we don’t need to worry about vectorizing our text. On top of this, we can also actually cut down on the amount of text preprocessing we do, as some punctuation, like exclamation marks, as well as stop words, like “not” or “very,” can impact polarity and subjectivity scores. We’ll typically want to either entirely remove certain text processing steps, or at least pare them back so we don’t end up altering the meaning of the sentence.
Rules-based approaches like TextBlob are fairly rudimentary but tend to work quite well for sentiment analysis, especially when speed and efficiency are important. If you have labeled data, or are able to easily label your data, you can also treat sentiment analysis as another text classification problem, as mentioned above. In this case, you’d use the vectorized text to predict the sentiment category.
Topic Modeling
Topic modeling refers to using unsupervised learning to identify latent topics within a corpus of text. Topic modeling is conceptually similar to clustering, as we don’t need labeled data or explicit category tags to assign categories, rather, we’ll find keywords from documents which are close to one another in vector space.
LDA, or Latent Dirichlet Allocation, is one of the most commonly used methods of topic modeling. The goal of LDA is to learn the mix (or, probability distribution) of topics within each document as well as the mix of words in each topic, in order to ultimately assign documents to topics. This happens via four key steps:
- Choose a number of topics to learn (this is a hyperparameter that we set).
- Randomly assign each word in each document to one of the topics.
- Re-assign words to topics, if necessary, based on:
- How frequently the topic appears in the document.
- How frequently the word appears in the topic overall.
4. Iterate through Step 3 until topics start to emerge.
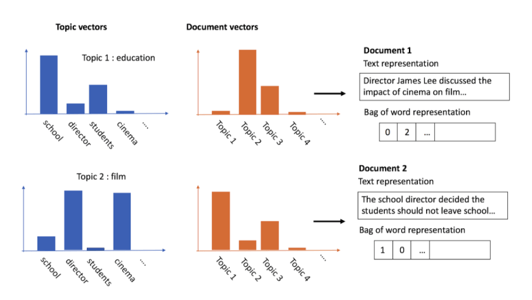
{kind=link}
We can see the distribution of words within each topic and the distribution of topics within each document. Document 1, “Director James Lee discussed the impact of cinema on film…” is mostly associated with topic 2, film, and lightly associated with topic 1, education, which makes sense. Topics won’t actually be labeled for us, but we’d look through the keywords to come up with appropriate labels. For example, it makes sense that a topic which has many appearances of the words “director” and “cinema” would be labeled “film.”
LDA is one of the most popular algorithms for topic modeling, but there are a handful of other algorithms that can be used as well, including Non-Negative Matrix Factorization (NMF) and Latent Semantic Analysis (LSA).
Recap
NLP is a very broad field, and has grown exponentially over the past decade, paving the way for major advancements in our day to day lives. This said, the fundamental principles of NLP projects haven’t really changed.
In any NLP project, we must first clean and preprocess our data to ensure that our model is free of unnecessary noise. Text cleaning often involves normalization, tokenization, stop word removal, and stemming or lemmatization. However, some NLP techniques such as sentiment analysis require as much information as possible and less text cleaning, to ensure that polarity and subjectivity are not lost.
Once text has been cleaned, it must somehow be converted into a numerical format. Typically, this happens via vectorization or generating embeddings, and there are a ton of new and advanced techniques which leverage neural networks to generate embeddings.
Cleaned and vectorized text can be used to perform a wide array of NLP techniques. Some of the most common include text classification, sentiment analysis, and topic modeling. There are a handful of ways to perform each technique, and as always, the best approach depends on the problem at hand.