




Every business function struggles with scale, including AI and data science. Architects have addressed technical scale to increase productivity — blazing fast connections, big data architectures, faster chips, distributed computing, massively parallel processing, and all sorts of optimized hardware stacks for AI.
Bigger, faster systems are only part of the solution to scaling AI. One data scientist working on a massively parallel system (no matter how elastic or scalable) is still only one data scientist. So for AI to thrive in business, we must change how we think about “scaling” data science work.
So what’s the key to unlocking these constraints? AI needs to be scaled in three ways, technically, organizationally, and operationally. This blog will focus on the second pillar, scaling organizationally with a software-centric approach.
If we’ve learned anything over the past decades of automation, people need integrated software platforms to do their jobs efficiently. But most AI platforms were designed only for expert data scientists. But expert data scientists have a super-set of skills that even other technical experts, like engineers in the business, don't have.
Traditional data science platforms and services celebrate the complexities of data science, requiring deep coding and technical skills and leaving most of us on the sidelines. An essential element of scaling is software architecture.
Great Software Architecture Simplifies AI
Software applications (now delivered as-a-service in the cloud) support “teams” and have been the key to unlocking the value of almost every business function you can think of — from accounting, to marketing, to operations. Software simplifies complex workflows, tooling environments, and processes while enabling teams.
Software helped systemize these functions and create departments that scaled beyond the capabilities of their most expert accountant, their most prolific marketer, or the lone genius in operations. Software architecture enabled new users, created a common platform, and connected “super users” (expert data scientists in our context) with business users (citizen data scientists and business analysts).
According to Deloitte, data science is on the same maturity path:
“The critical component to this delivery model is both the availability and capability of tools that can abstract much of the complexity in traditional coding and algorithm development. These tools must work for the ‘clickers’ of the business world and not ‘coders’ of the technology world.” – Scaling Data Science to Deliver Business Value, Deloitte
Dataiku, the platform for Everyday AI, exemplifies this approach. It’s a software-centric approach to creating scale for data science organizations. Whether running on your chosen infrastructure or delivered as-a-service, the software platform combines the ability to scale data science teams and leverage elastically scalable infrastructure. It enables both expert data scientists and non-experts on a common, unified platform.
A modern AI software architecture needs six key design elements to allow AI to scale:
1. Connecting People to Scale
What beats a super-genius Ph.D. data scientist working on a screaming-fast, massively parallel infrastructure? A “team” of data scientists working with skilled data engineers, business domain experts, business analysts, AI developers, and operations as a team on a common, connected platform.
Dataiku connects people to teams, projects, tools, data, work, and insights that help them do their jobs. Data scientists must be connected to data engineers, operations, business analysts, domain experts, and others. And they need to be on the same page around projects, as well as to communicate about and share those projects from inception to production. And they all need a single view of any given project.
2. Scale AI Programmatically and Visually
Data science teams will have a broad range of skill sets. An AI software platform needs to support expert data scientists who prefer working in code and non-technical users (i.e., business analysts) who choose a visual interface. Dataiku enables both modes.
In Dataiku, coders have all the tools they need to customize projects working programmatically. Coding in any language is fully enabled for any IDE or programming language with Dataiku code studios. The code studios directly connect popular IDEs like JupyterLab, VSCode, RStudio, and web app frameworks (including StreamLit) into Dataiku so that experts can work in familiar environments but still leverage visual machine learning (ML) for efficiency. You can scale by finding the optimal mix of coding and visualML that suits your team.
For many tasks in data science, a visual interface can increase scale by enabling more users to tackle ML tasks that formerly only experts could accomplish. Training models using Visual ML and AutoML can significantly reduce the time for model build, and the former accelerates use cases like computer vision and time series forecasting.
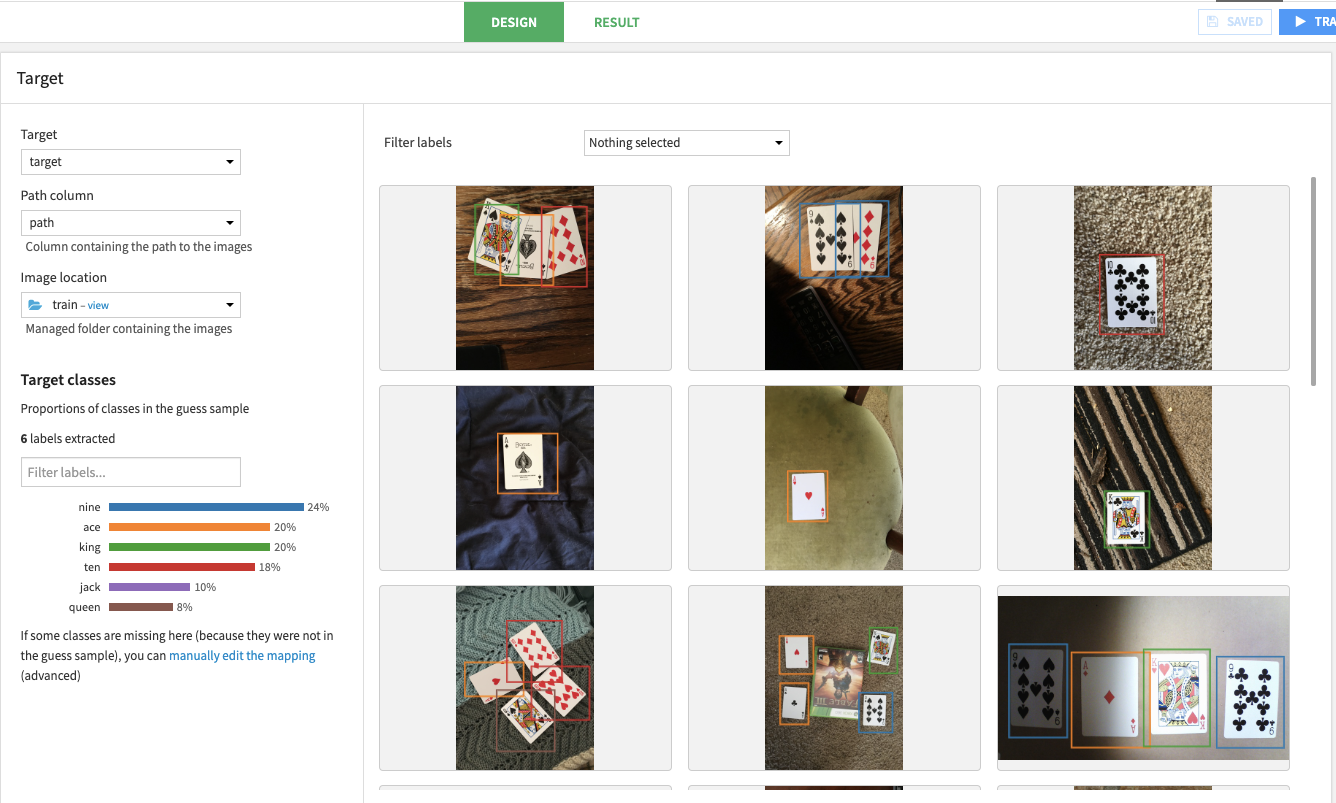
Computer vision: View images and associated labels, augment data, and generate new images for training.
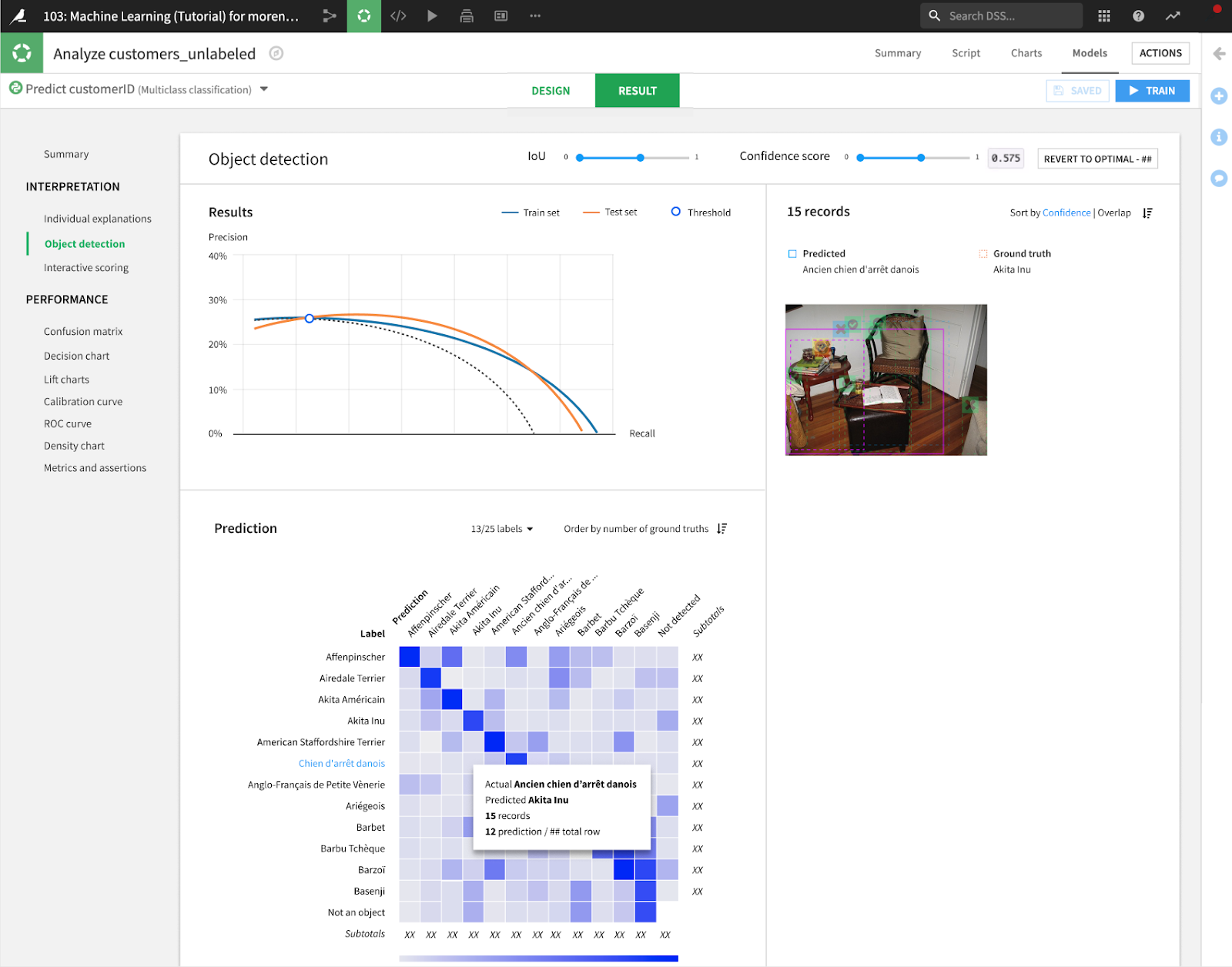
Explore evaluation metrics and use interactive scoring after training vision models.
Code-based and visual approaches can be combined in Dataiku within any given project. And with Dataiku’s extensibility framework, enterprises and partners can build plugins to extend the platform's power. Plugins can be wrapped in a visual interface for use by non-programmers, so expert data scientists can help upskill your entire enterprise. Read how Excelion Partners used the framework to create a tool called Thread to catalog and efficiently view data lineage.
3. Go With the Flow to Scale
The Flow in Dataiku is a visual representation of projects, tasks, data, models, infrastructure connections, and deployment all in one place. But the Flow is more than simply a directed acyclic graph, commonly known as a DAG. It helps simplify the management of your ML projects and provides a unified view of projects.
The example below shows a Dataiku Flow with all the data sources, transformations, models, and infrastructure connections visually mapped, running on Snowflake.
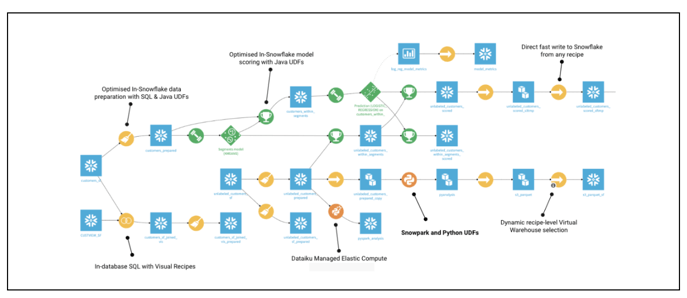 The Flow is an easy-to-follow, visual representation of data sources, datasets, transformations and other tasks (visual and code), ML tasks, and connections.
The Flow is an easy-to-follow, visual representation of data sources, datasets, transformations and other tasks (visual and code), ML tasks, and connections.
In Dataiku projects, all permissioned users can discover the contributions of the entire team and communicate about every step of the project from within the project or with a Flow Document Generator. The Flow centrally organizes an AI project, providing complete transparency and traceability for projects so business stakeholders can understand projects and comply with both internal best practices and external regulations. It directly connects all stakeholders to a single view of any project from any location to increase productivity and scale.
4. Discover, Share, and Reuse for Scaling AI
A software platform increases productivity and helps teams scale by enabling rapid discoverability, sharing, and reuse of data, features, models, and tasks. As a flow-based tool, all parts of the Dataiku Flow are reusable in other projects.
Dataiku feature store and data catalog make feature groups and datasets easily discoverable. Feature store is a dedicated zone within Dataiku where teams can centrally access and share reference datasets containing curated features. And the data catalog enables users to discover data assets you have created, connected to, or brought into Dataiku. And Dataiku has made all objects in AI projects seamlessly sharable, so users can compose new AI applications from existing projects, reusing datasets, features, models, and other objects.
5. Scaling With Integrated Applications and Self Service
The data science team includes ML engineers and operations experts who put projects into production and keep them healthy and well maintained. The Dataiku platform integrates data science with ML operations (MLOps). Today, much of the value delivered by models is lost in the latency between build and deployment when ML engineers have to rebuild poorly constructed data pipelines or refactor models.
Integrated deployment with Dataiku deployer maintains continuity and eliminates latency between model build/train and deployment. It provides an easy-to-use, self-service interface for data team members to deploy Dataiku project bundles, from design nodes to automation nodes. Software with such self-service features helps your people and organization scale.
See an example of how Dataiku's software architecture enables self-service and eliminates latency between model build and deployment.
Integrated MLOps enables the entire AI lifecycle to be automated as well. While it integrates the pre-production and production environments, it also connects data engineers and ML operators. And integrated governance enables scale as well by enabling oversight and providing confidence in the model. And everyone has a single view of the models running in production via the model registry.
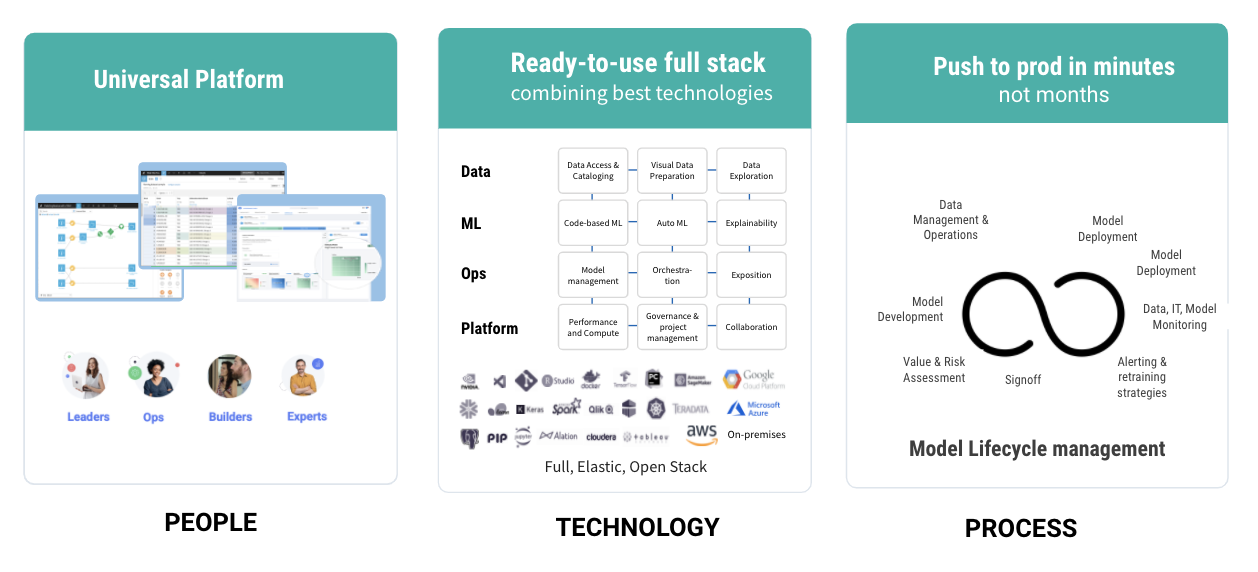
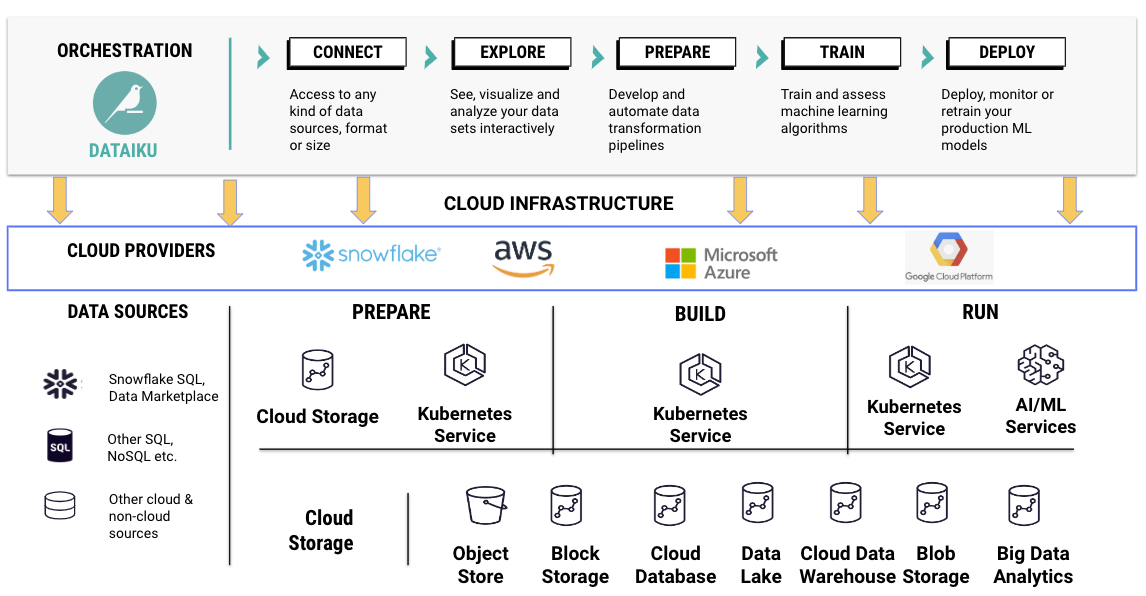
6. Orchestrate Infrastructure to Scale AI
Last, but not least, the team that scales AI includes both architects and administrators who implement the underlying tools and infrastructure required. Dataiku has pre-built integrations and templated approaches to orchestrating scalable infrastructures and technologies, which enable both vertical and horizontal scaling to match workload requirements in step with the AI/ML lifecycle.
Dataiku enables both architects and administrators with all the tools they need to quickly and efficiently deploy the Dataiku platform on AWS, Microsoft Azure, and Google Cloud Platform. Additionally, Dataiku has deep integrations with the Snowflake Data Cloud. But the key to orchestrating AI and ML workloads is … you guessed it … great AI software that removes the complexity of provisioning and managing infrastructure.
{kind=link}
Dataiku offers seamless integration and orchestration across the entire AI/ML lifecycle.
Dataiku’s software platform scales your people and organization. If your software architecture doesn't enable people with the six key design elements, you’ll fail to scale — no matter what infrastructure you run on.